
“时露流萤百草底,一梦氤氲到天明。”
在2026年的语境下,文本生成图像变得非常成熟。从一开始不到1B的Stable Diffusion,到一些商用闭源的可能几百B的模型。问题也从早期的“能不能根据prompt生成一张差不多的图”到现在的“更高分辨率,更复杂的文本理解,更强的多图和多轮编辑。”,同时架构也从一开始的Latent Diffusion,转而向纯AR,AR+diffusion,纯pixel-space上的探索。
最近,微软开源了一个3.8B的文生图模型Lens,其提供了Base,RL和Turbo三种变体。并且附带了一个报告,其中相对详尽的给出了各个过程的实现细节。从研究和学习的角度看,Lens处于一个很合适的位置。它规模为3.8B,和一些早期的开源文生图模型类似却同时又更接近今天的训练范式,很适合想理解现代文生图模型内部机制的人来进行测试。同时其提供了RL和Turbo两个变体,使它很适合作为一个case study,来理解文生图模型在后训练前后发生了什么。这也是这篇blog的目的。
Overview
我们从最直接的事情开始,我们用一些prompt和相同的噪声,分别用Base,RL,Turbo来进行采样。我们按官方仓库的推荐值,对于Base,我们以5.0的CFG采样50步,对于RL后的model,我们以5.0的CFG采样20步。对于Turbo,我们不开CFG采样4步。我们默认都生成1440$\times$1440的图片。

上图中每个子图里,最左边是Base,中间是RL,最右边是Turbo。我们可以发现Base的结果有时候会感觉“去噪没去干净”,而RL以后的结果倾向于更真实和清晰。Turbo是从RL的模型里蒸馏的,可以观察到Turbo的视觉质量并没有太大的损失,但能感觉到Turbo输出的图片饱和度会比RL的高一些。同时有一些图片会存在一些artifacts,例如第二行右侧,灯泡灯芯处;第四行右侧,RL和Turbo后,彩纸叠的飞龙的质感发生了改变。考虑到其有限的训练数据和模型规模,这可以接受。
现在我们看了一下Lens具体结构:
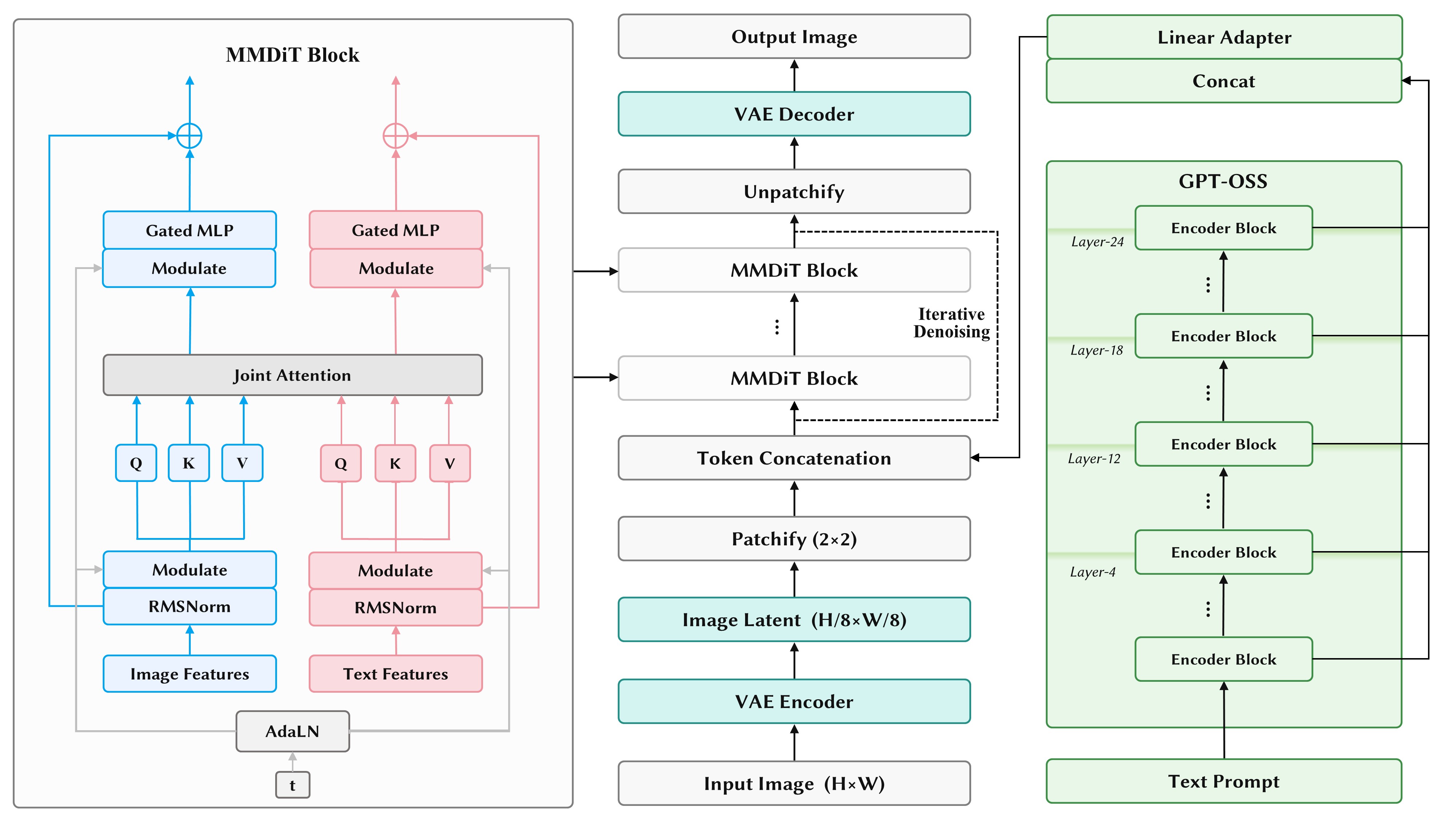
其是一个标准的MM-DiT,DiT中叠了48层,hidden dim选取为1536,多头注意力的头数为24。可以大致估算出一个block是85M。
1536$\times$1536大约是2.35M,那样QKV的投影,和多头注意力的投影,一共是4份,就是9.43M左右。然后在那个Gated MLP里,一般会跟通常的FFN的操作一样膨胀再压缩回来。gate,up,down都是1536$\times$4096,加起来也是9.43M,然后一共3个,那就是18.8M。跟刚才attention需要的加起来,28.2M。然后还有AdaLN来注入timestep的信息,这个在图里被省略了,需要为attention前和gated mlp前各自生成一组shift,scale,gate。1536$\times$9216,14.1M。加起来42.3M,然后text和image是双流的,就接近85M了。
Lens使用Flux2 VAE作为latent space,用GPT-OSS-20B作为text encoder。20B听起来相比于DiT本身,大的太多了。但由于GPT-OSS一是其是个MoE,一共32个experts,然后激活Top-4,这使得激活参数没那么多。二是它原生是MXFP4的,在新版的transformers库实现里,只要装了合适版本的triton和kernels,在很多计算卡和消费级显卡上都可以实现运行时反量化(NVIDIA GPU with compute capability ≥ 7.5),所以显存开销并没有那么大。Lens的设计里,GPT-OSS的hidden states分别从浅层和深层,共4个锚点来提取,最后汇聚成送给MM-DiT的text tokens。
Lens的三种变体都共享一样的结构,所以很自然的,我们可以看一下RL前后和Turbo前后模型参数的变化量。我们简单的统计他们欧氏距离的相对变化,对于权重矩阵,那就是Frobenius范数,对于偏置,那就是L2范数:
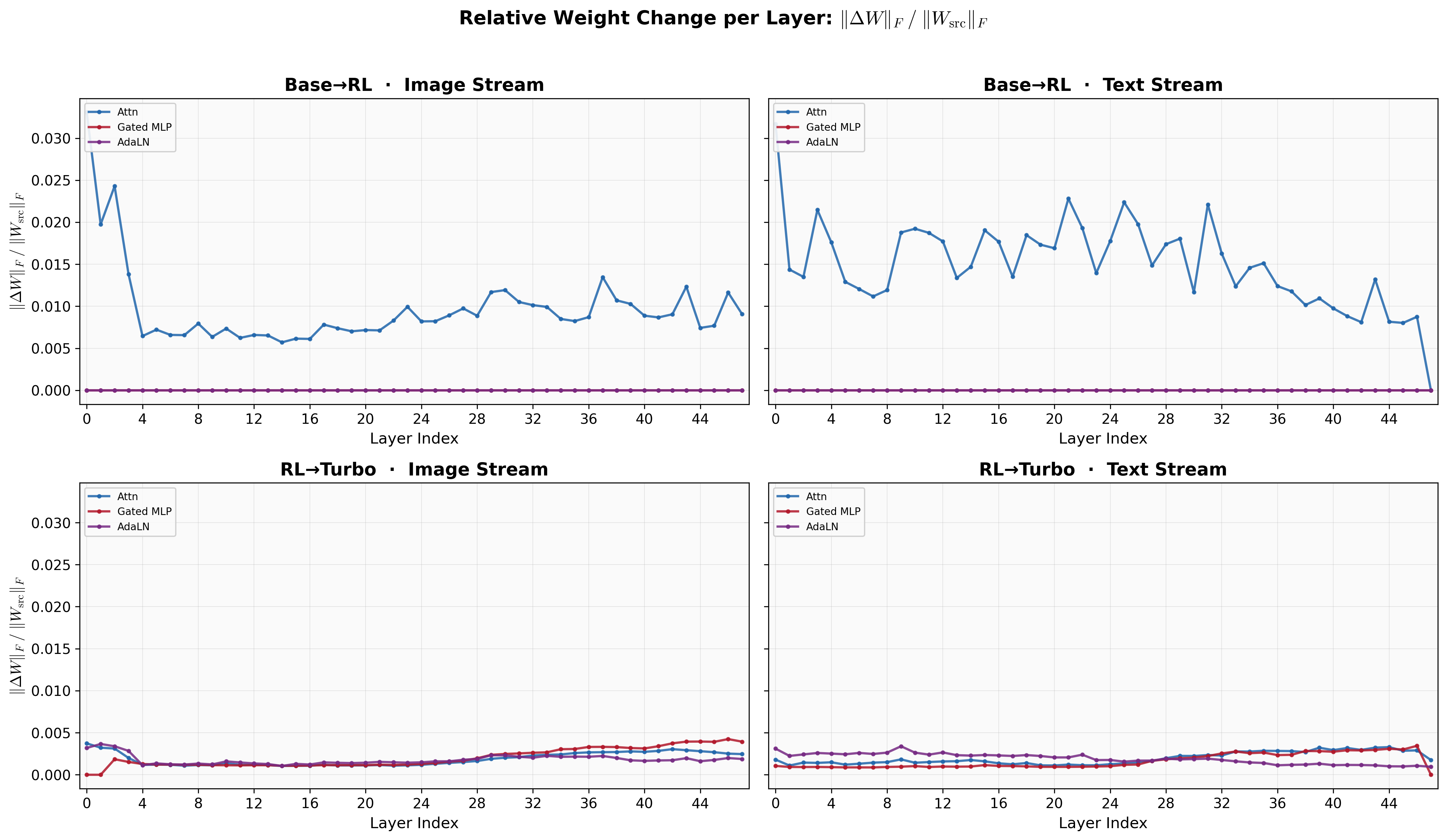
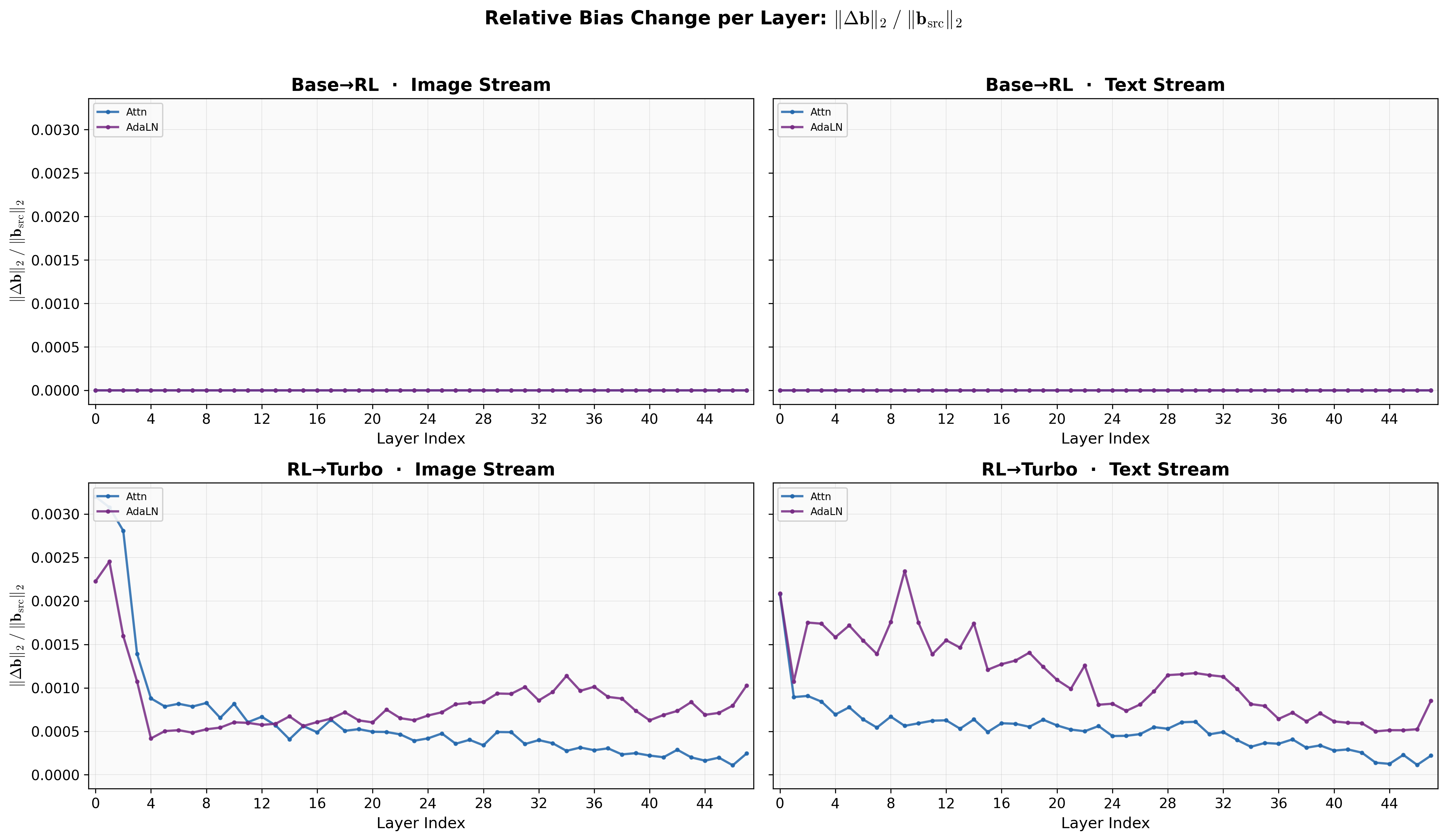
可以发现,对于权重$w$,RL基本只改变了attention的权重,而Gated MLP和AdaLN没有任何变化,这和技术报告里说的RL是用LoRA微调是吻合的(并且说明LoRA只加在了attention上)。而Distill是全量微调的,Attention,Gated MLP,AdaLN的参数都发生了一些变化,但幅度跟RL的LoRA微调比起来变化小了很多。而偏置$b$上并没有什么太多的现象,RL的LoRA微调并没有改偏置,Turbo导致的偏置的变化也很小。
Exploring DiT Blocks
由于三种变体的结构都是一样的,我很好奇如果我们交换相同层数下,不同模型的blocks会发生什么。一共是48层,我将其看作连续的6段,每段是8个blocks。接下来我们用相同的噪声和prompt,去看一下如果我们交换不同段下的blocks,这样产生的“hybrid”的模型所生成的结果。首先是RL和Base:

我们在sample这上面的每张图片时,依然是steps为50,CFG为5.0。可以看到整个上三角形成的图片,有一个缓慢的过渡,并且都能生成合理的图像。考虑到RL是从Base LoRA微调出来的,这个现象感觉是很正常的。一个观察是,如果我们交换的是一开始(seg 0)的blocks,生成的图片往往都是RL那张图片里的饭店的轮廓。而如果从seg不为0的地方开始交换,则还是Base生成的饭店的轮廓。同时如果仔细观察会发现图像细节也有一些差异。一个自然的猜想是:浅层的blocks会决定图片的大概结构,深层的blocks决定了图片的细节。
接下来,我们直接把Base和Turbo的blocks进行交换,我们直接按Turbo来采样(即4步,无CFG)。
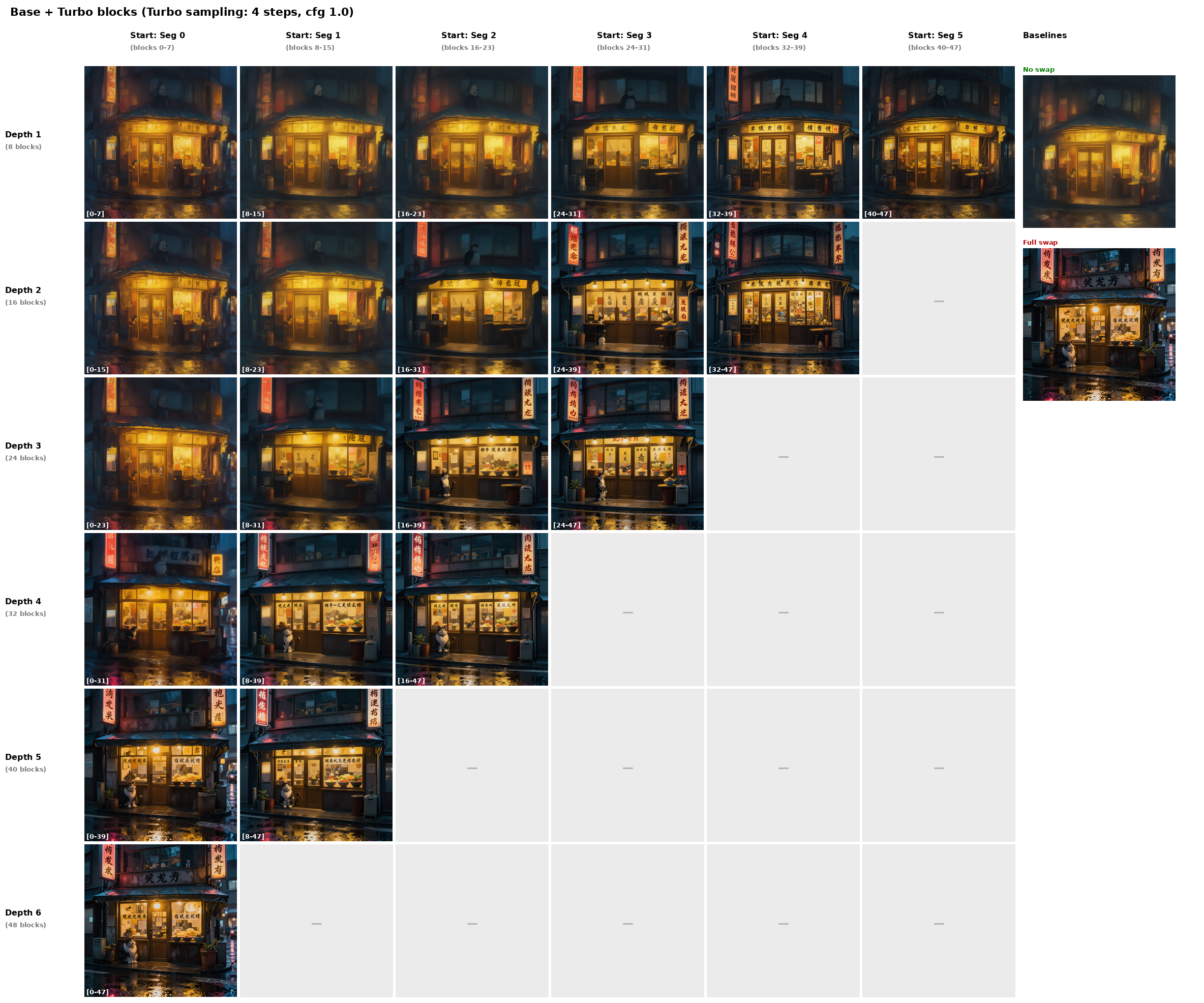
Turbo是在RL的基础上全量训练的,注意我们这次是和Base交换,所以这个结果有些有趣。我们看第一行,第一行每次都是替换一段(8个blocks)。替换越往后的segment,图片会相对变得越清晰,但结构不变。如果看对角线和第一列的结果,会发现如果想变成Turbo四步出来的样子。光替换开头的seg0,即浅层的blocks是不够的。我们可以提出一个猜想,RL可以理解为$p_{\mathrm{RL}}(x|c) \propto p_{\mathrm{Base}}(x|c)\mathrm{exp}(\beta\cdot R(x,c))$,即可能Gated MLP里已经储存了大量的视觉的pattern,RL只是需要通过修改attention来把这些pattern更好的调出来。并不涉及关于timestep上的动力学。而few-step distill,往往需要微调出一个新的表征。一个印证的例子是,一般的LoRA确实是attention-only的,但一些关于蒸馏的,比如DMD2-LoRA,LCM-LoRA,看起来都会把FFN,time embed给加进去。在RL的基础上如果起一个attention-only的distill,可能可以验证一下。
这引出来了一个更自然的问题,即48层DiT blocks都是有用的吗?他们是否存在一些冗余?这次我们也是按照那6段的分法,连续的移除1,2,4,8个blocks,然后观察生成图片的样子。



这三张图片依次是Base,RL,Turbo的结果,每张图片从上到下依次是移除1,2,4,8个blocks的样子。移除最浅层和最深层的blocks的结果我们大体上可以预测,结果也在意料之中。一个意外的发现是从anchor=24,即中间位置开始移除,明显更变化更剧烈一些。以及看起来,Base在移除起来比RL和Turbo更鲁棒一些。RL在移除后最先出现的artifacts是色调的漂变,而Turbo出现的是语义的漂变(玄凤鹦鹉的样子变成了虎皮鹦鹉)。但这确实表示了一定的冗余程度,说明模型尺寸上可能还有压缩的空间。
Exploring Text Encoder
Lens从GPT-OSS里提取了multi-layer的feature来当作condition,很自然的一个做法就是探究一下GPT-OSS不同层数的feature到底在生成中起了哪些作用。我们选取了两条prompt:
Prompt A : “A cherry-red Ferrari F40 parked on a rain-slicked cobblestone street in Milan at dusk, reflections of neon shop signs shimmering on the wet ground, dramatic side lighting, shallow depth of field with creamy bokeh, shot on a Leica M11 with a 50mm Summilux lens”
Prompt B: “An enormous sapphire-blue dragon soaring above jagged snow-capped peaks, iridescent scales catching the last rays of sunset, massive leathery wings spread wide, swirling clouds and aurora borealis in the sky, epic fantasy digital painting with intricate detail”
我们想探索两件事,一个是如果我们丢掉某些层的feature去生图,效果会怎么样。另一个是如果我们用其他prompt(例如prompt B)去覆写prompt A里的某些层的feature,结果又会怎么样。我们用Turbo去做4步生成,得到了很有趣的结果:

左侧是针对prompt A,进行drop某些层的,即我们用空字符串计算出的token,然后zero-pad到跟prompt A一样的尺寸(但其实由于mask的机制,DiT并不会看到zero-pad的内容)。我们发现如果只丢弃其中一层(例如$\mathrm{S}_0\emptyset _1\mathrm{S}_2\mathrm{S}_3,\mathrm{S}_0\mathrm{S}_1\mathrm{S}_2\emptyset _3$),大体的图片结构和语义还是保留的,只是特定的细节,例如“Ferrari F40”不能成功被表现。而丢弃两层及以上,图片的语义就会明显漂变,看起来丢弃$\mathrm{S}_1\mathrm{S}_2$和$\mathrm{S_2}\mathrm{S_3}$的影响更大一些。而右侧,如果我们用prompt B去混合,则会合成出一些新奇的结果,例如翅膀闪着红光的蓝色飞龙,和红色机械风格的飞龙。经几次测试来看,语义距离越远的,混合效果越明显,就像某种嵌合体。例如下面的哥特教堂与海底水母。

但,GPT-OSS实际还是太大了。即使triton可以进行运算时反量化,再加上offload,峰值内存也达到大约16GB。GPT-OSS是一个MoE,他其实一次只激活4个experts,共24层blocks。那这个MoE的路由(routing),有没有什么规律呢?首先我们要明确这里面text prompt是怎么被变成condition的,与CLIP/T5不同,GPT-OSS并不是直接见到caption/text prompt,而是类似一次会话:
<|start|>system<|message|>
You are ChatGPT, a large language model trained by OpenAI.
Knowledge cutoff: 2024-06 …
Valid channels: analysis, commentary, final. …
<|end|><|start|>developer<|message|>
Instructions
Describe the image by detailing the color, shape, size, texture,
quantity, text, spatial relationships of the objects and background.
<|end|><|start|>user<|message|>
A cat sitting on a windowsill ← 用户的 prompt 在这里
<|end|><|start|>assistant<|channel|>analysis<|message|>
Need to generate one image according to the description.
<|end|><|start|>assistant<|channel|>final<|message|>
← 模型从这里开始”生成”
相当于是做一次prefill,所以其实会按TEXT_OFFSET=97来截断一些chat template的token。我找了一份rewriting过的OneIG-bench的prompts,他rewriting后有short,middle,long三种模式,然后OneIG大约有一千多条prompts。所以我们可以统计一下expert激活的routing来看看:
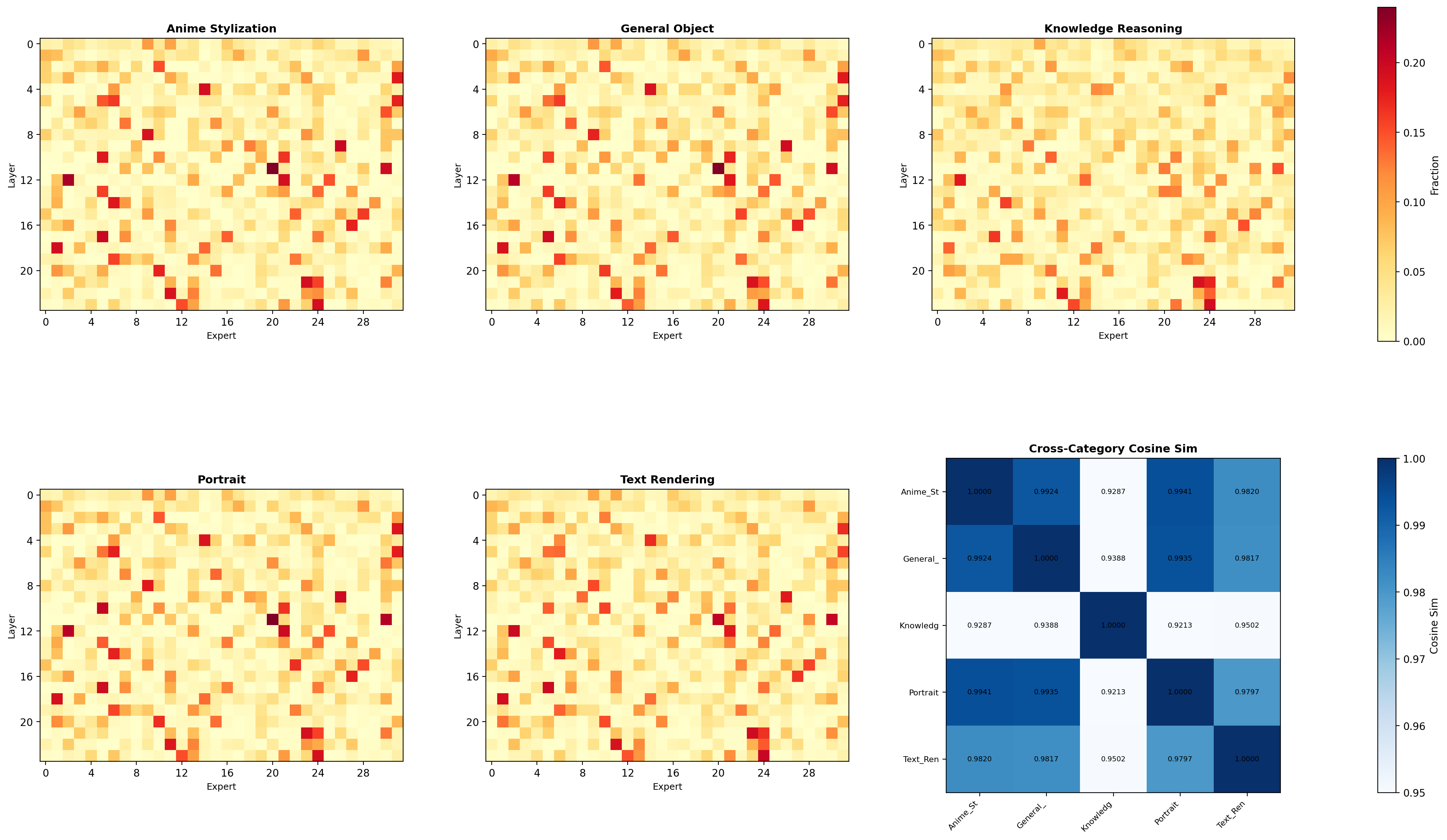
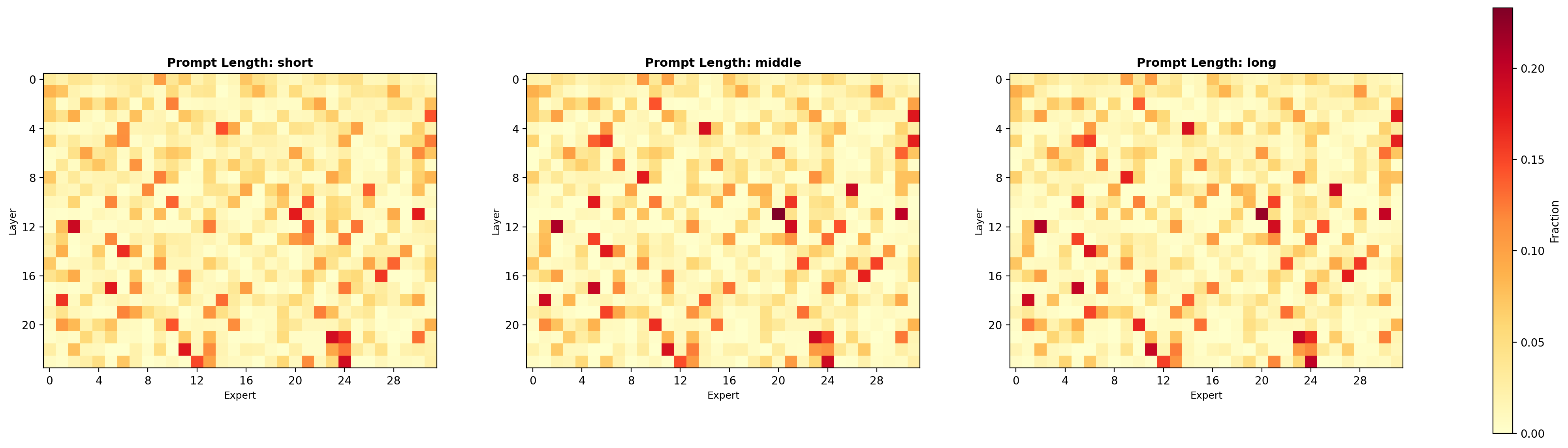
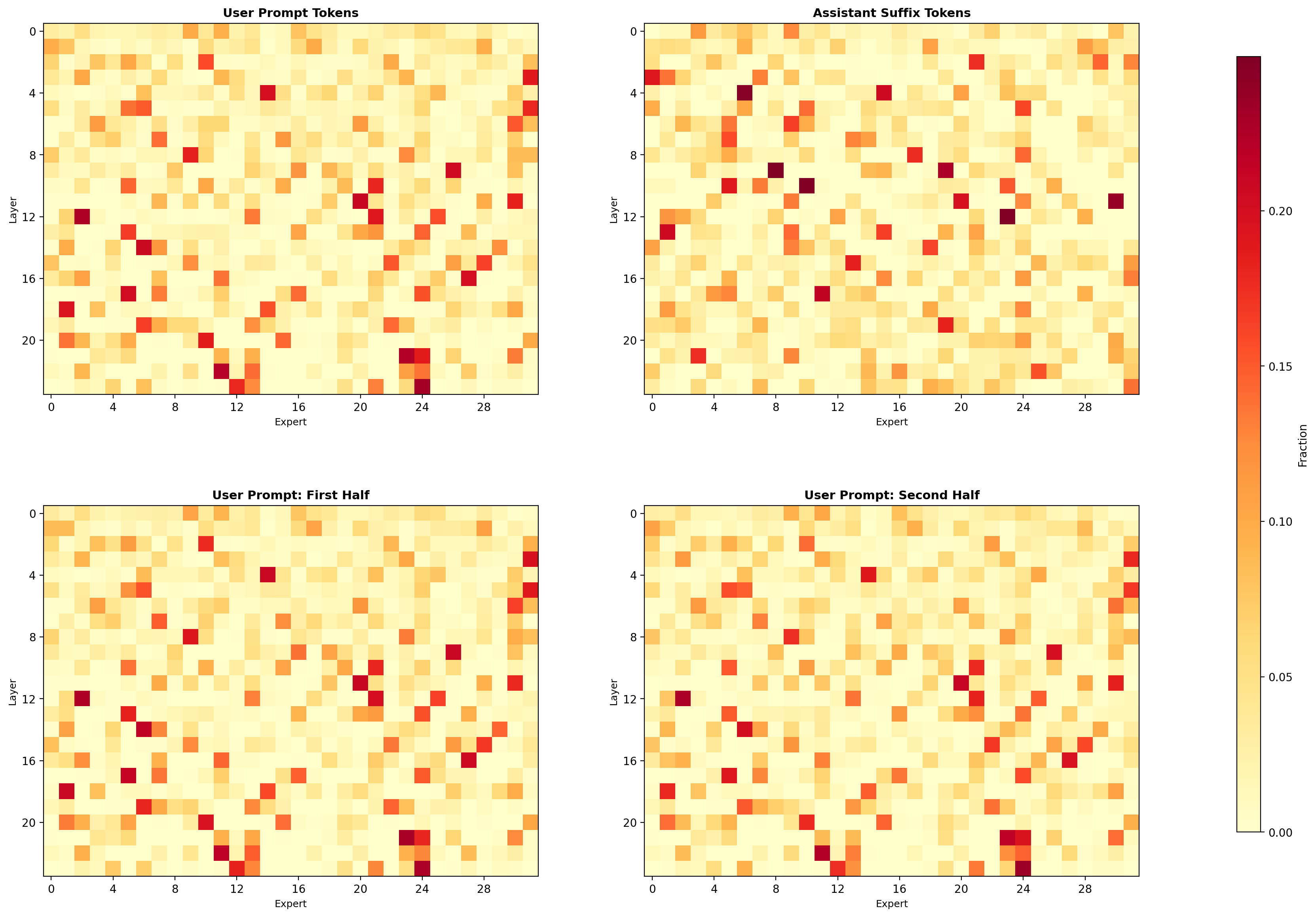
于是我们发现,好像不管是不同种类的prompt,不同长度的prompt,以及按前一段,后一段,前缀token,后缀token来统计,跟描述text prompt/caption相关的experts,服从某种统计规律。
“那还说啥,都哥们。”——佚名
那为什么不干脆直接把GPT-OSS-20B里的那些experts按刚才的统计规律给剪枝掉呢?于是这样做,得到了Lens-Text-Encoder-Top4和Lens-Text-Encoder-Top8,他们在text encoder阶段的峰值从一开始的16GB,锐减到6.7GB和7.9GB,也就是说,在offload的情况下,我在A6000上进行测试,峰值显存仅有8GB。如下图所示:



这个剪枝确实带来了一些语义上的退化,从上到下依次是原版32专家,Top-8专家,Top-4专家的推理结果。例如僧人的衣服颜色,幻想蜗牛,随着experts的降低确实变克苏鲁了。但看上去Top-8是一个不错的权衡,因为在Top-8下,Text Encoder的显存峰值就已经小于DiT的峰值了,所以如果offload的话,没必要比Top-8再小了。这至少是一个不错的training-free的办法,Top-8下MXFP4的模型才5.72GB,相当于一个6B的text encoder,然后接一个4B的DiT,还有充足的想象空间。
Exploring Image Editing
很遗憾,Lens目前并没有原生的支持图像编辑的变体,可能以后会有。但我们也可以用一些training-free的方法实现editing来玩一玩,比如FlowEdit。这个方法可以简单的理解成“单个样本的,在prompt层面的DMD”,细节这里就不作赘述了。

上图中奇数列是源图,偶数列是编辑后的。可以发现,替换材质,个体,完成的是很成功的,一些简单的物品增加和移除也能做一下。这里要注意一个事情,在Lens的推理流程里,实现的是norm-rescaled CFG,即:
1 | comb = uncond + cfg * (cond - uncond) |
这个对寻常的文生图来说是正常的,但如果跑FlowEdit,这会让速度场的差几乎为零,所以在玩FlowEdit得HACK一下代码,把这个norm-rescaled的机制给关了。
End
在这篇blog里,并没有仔细去探索如何最大程度上发挥Lens的潜力,来生成各种各样的图片。作为一个3.8B的模型,以及不到1B的训练集,其难免对于一些细节(例如人手,四肢)等会出现错误。但就像上文分析的那样,其还是一个可玩性很高的模型,可以从中观察到一些有趣的现象,并且易于实验。

