
“多年以后,面对投出去石沉大海的简历,他将会想起在大学里,第一次运行import torch的平平无奇的,遥远的下午。”
这篇blog是为了记录一些搭建炼丹炉的过程中的常见命令,旨在作为一份备忘录。
由于我并没有MLsys,LLM等相关经验,所做单机多卡就够用,所以内容不会包括多机多卡,accelerate,DeepSpeed等内容。
PyTorch
在近几年,如果一个人选择接触炼丹,最开始都是先在自己装着Windows的笔记本电脑或者台式机上安装CUDA,cudnn,Python,Anaconda/miniconda,PyTorch,然后开始做一些比较简单的炼丹项目。

一般有两种方式安装PyTorch,一种是用pip,另一种是conda。pip是Python Package Index (PyPI)的简称,是一个托管了许多Python包的公共仓库。例如可以用如下命令安装1.8.0的PyTorch:
1 | # CPU |
pip本身不管理环境,只是用来安装包。这样久而久之会产生许多问题(开发环境中不同的包冲突,环境本身冗杂),虽然可以用Python的虚拟环境venv来创建一个与当前操作系统部署的python环境(base)相隔离的环境,但venv中的Python版本受限于base的Python版本,这造成了很大的局限性。而且在炼丹中,CUDA版本也是一个很要紧的事情。如果非要在base里完成所有的事情,那就需要来回来去切换CUDA和Python环境变量,这显然很不友好。
所以,自带环境管理功能的conda显然是更好的选择。conda从Anaconda和Conda Forge仓库安装包,这些仓库不仅包含Python,还包含一些R,Java,C++的包,被广泛用于生信分析,数据科学等。例如用如下命令安装PyTorch 1.8.0:
1 | conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 \ |
这里的cudatoolkit,里面包含的是一些编译好的跟CUDA程序相关的动态链接库,在大多数情况下可以满足PyTorch的需求。换句话说,比如主机上装的是CUDA 11.3,你在conda环境里装了一个cudatoolkit 10.2,那么这时候你nvcc -V出来的,以及PyTorch在运行时用的cuda版本(torch/utils/cpp_extension.py中的_find_cuda_home)检测出来的,就会是10.2。
注意GPU硬件要和CUDA的版本匹配。
PyTorch与torchvision,Python,CUDA,PyTorch3D的版本关系如下:
| PyTorch | torchvision | Python | CUDA | PyTorch3D |
|---|---|---|---|---|
| 2.2.0 | 0.17.0 | >3.7 | 11.8, 12.1 | 0.7.6, 0.7.7 |
| 2.1.0 | 0.16.0 | >3.7 | 11.8, 12.1 | 0.7.5 |
| 2.0.0 | >0.14 | >3.7 | 11.7, 11.8 | 0.7.4, 0.7.3 |
| 1.12.0 | 0.12 | 3.7-3.9 | 10.2, 11.3, 11.6 | 0.7.2, 0.7.1, 0.7.0 |
| 1.11.0 | 0.12.0 | >=3.6 | 11.3, 10.2 | 0.7.2, 0.7.1, 0.6.2 |
| 1.10.0/1 | 0.11.0/2 | >=3.6 | 10.2, 11.3 | 0.7.2, 0.7.1, 0.6.1, 0.6.2 |
| 1.9.0 | 0.10.0 | >=3.6 | 10.2, 11.3 | 0.7.2, 0.7.1 |
| 1.8.0 | 0.9.0 | >=3.6 | 10.2, 11.1 | 0.7.1 |
| 1.7.1 | 0.8.2 | >=3.6 | 9.2, 10.1, 10.2, 11.0 | |
| 1.7.0 | 0.8.0 | >=3.6 | 9.2, 10.1, 10.2, 11.0 | |
| 1.6.0 | 0.7.0 | >=3.6 | 9.2, 10.1, 10.2 | |
| 1.5.1 | 0.6.1 | >=3.6 | 9.2, 10.1, 10.2 | |
| 1.5.0 | 0.6.0 | >=3.6 | 9.2, 10.1, 10.2 | |
| 1.4.0 | 0.5.0 | ==2.7, >=3.5, <=3.8 | 9.2, 10.0 | |
| 1.3.1 | 0.4.2 | ==2.7, >=3.5, <=3.7 | 9.2, 10.0 | |
| 1.3.0 | 0.4.1 | ==2.7, >=3.5, <=3.7 | 9.2, 10.0 | |
| 1.2.0 | 0.4.0 | ==2.7, >=3.5, <=3.7 | 9.2, 10.0 | |
| 1.1.0 | 0.3.0 | ==2.7, >=3.5, <=3.7 | 9.0, 10.0 | |
| <1.0.1 | 0.2.2 | ==2.7, >=3.5, <=3.7 | 9.0, 10.0 |
PyTorch3D的安装有时候会比较棘手,有时候项目里可能只是想要一些单纯的I/O函数(
load_obj,save_obj)或者转换函数(旋转相关),完全可以从PyTorch3D的源码里拿出来,而不需要费劲去装PyTorch3D.。
Conda Environment
那么,如何建立一个conda环境呢?创建一个名为Radio的环境,并指定Python版本为3.8,可以使用:
1 | conda create --name Radio python=3.8 |
然后输入:
1 | conda activate Radio |
就会进入名为Radio的环境。
在某些时候,假设你安装了anaconda,但可能没有合适的初始化之类的,可以运行conda init,这将会把一些conda的初始化脚本添加进终端的初始化中,运行后你再启动一个新终端,就会在最左边看见(base)图标了。
在一些旧版本的Conda中,你在
conda activate之前,可能需要运行source activate来启动base环境,source activate是一个旧版本中用于激活conda的命令,在较新版本中,这一指令已经被conda activate取代。
这样你就能建立许多环境,你可以进一步用conda env list来检查你具体有哪些环境,这些环境之间,以及这些环境与base之间,都是相互隔离的。当你想清理或不需要某些环境时,可以用如下命令删除镜像:
1 | conda env remove -p <enviroment path> |
或者:
1 | conda remove -n <enviroment name> --all |
当建立一个环境后,可以在这个环境里装包,用pip和conda都是可以的。但他们会有不同的行为。由于conda建立了完全隔离的环境,即使在当前激活的环境下pip install,也不会影响base环境。
当我们开始为新建的环境装包,无论我们在哪个环境使用pip来安装,下载的包文件(例如.whl,wheel发行版)都会缓存在全局的缓存目录中,与当前激活的环境无关。如果在Linux里,这一路径大概是:
1 | ~/.cache/pip |
在Windows里,会是:
1 | C:\Users\<current user>\AppData\Local\pip\Cache |
而用conda安装,缓存文件会在当前环境下的pkgs目录下:
1 | ~/anaconda/envs/<env name>/pkgs |
至于在conda下,那些安装好的Python包在哪里,取决于安装时使用的是系统的Python还是conda中的Python,如果是前者,那一般在系统安装的Python的site-packages目录下;如果是后者,则一般在:
1 | ~/anaconda/envs/<env name>/lib/site-packages |
这些缓存的目的是如果在某个环境中下载了某个库,那么当在另一个环境里还要用这个库时,就可以直接从缓存中复制进来。但时间长了这两个缓存路径的大小会变得很大,所以如果出现一些容量的问题,第一时间先清理这里。
pip和conda都会自行管理依赖,来避免库之间的冲突。但这有时候会很令人困惑,例如当你安装某些库时,他检测到一些冲突,把你现在装好的torch直接卸了要装新的,会很不方便。在这种时候可以强制让其忽略依赖:
1 | # use pip |
很多时候炼丹项目会提供environment.yml或者requirement.txt,理想情况下,可以分别用conda和pip一键安装,例如:
1 | # use conda |
但真实情况下,直接这样conda往往会得到卡死,一直在solving environment,或者PackageNotFound,用pip走requirement.txt往往会更顺利。这种时候建议直接手动的装,先从一些大的包开始装,后面那些小的包也就能自动匹配上了。
有些时候,我们需要将自己的环境配置发给其他人,其中一种途径就是发一份environment.yml和requirement.txt,这样来完成某种意义上对环境的打包:
1 | # use pip |
其中第一种导出的会有本地路径,例如一些包,并不是在线pip下来的,而是离线安装的。而第二种会只保留版本号。
但这其实不解决根本问题,因为很多时候离线装的包就是因为在线装装不下来,例如
dlib,就算变成有个版本号的形式,另一边直接pip安装的时候也会报错。
如果用conda的话:
1 | # use conda |
问题反而会更多,conda导出的很多具有标识符,其中有一些会标注特定的操作系统(如linux),第二种的--no-builds,会滤掉那些跟平台相关的依赖,来实现跨平台的导出。
所以无论哪种方法,都需要一些手工删除,才能得到一个干净的环境配置表单。
GPU监控
当配好环境,安装好torch后,基本就可以炼丹了。GPU的状态当然是很有必要观测的,如果所处的系统/环境正确的安装了NVIDIA的驱动,那么可以通过nvidia-smi来查看GPU的型号,驱动版本,当前显存占用率和利用率。在Linux下可以用watch -n 1 nvidia-smi来在终端上每隔1秒刷新一次监控的结果,来动态查看。
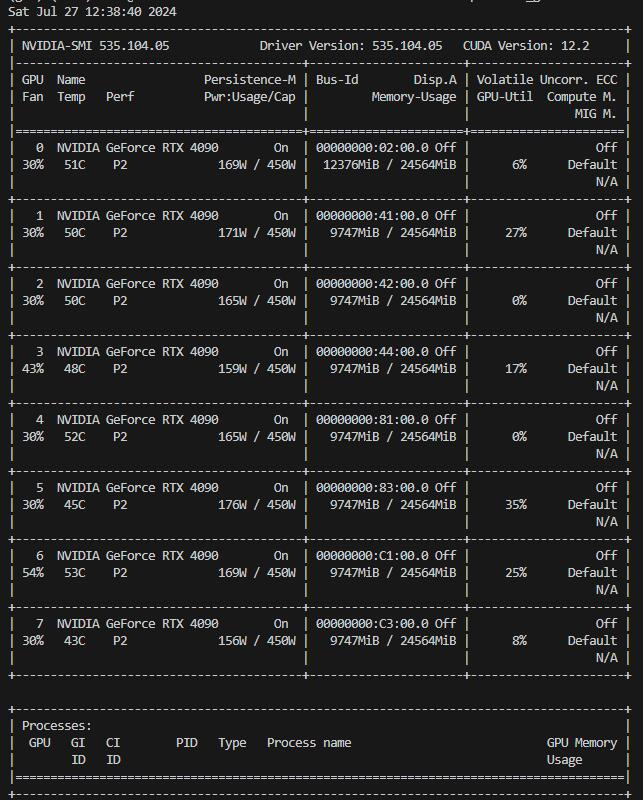
这里我们往往要关注显存的占用率和利用率,简单理解就是,显存的占用率就是模型权重,输入数据,中间结果等各种各样的被放进GPU上的数据所占的比例,这个当然不能超过GPU的最大显存。而利用率指的是GPU中的计算单元进行计算的繁忙程度。
理想情况下,我们希望显存占用率和GPU利用率都拉满,但这很难实现。常见的一些情况有读取数据时的时间过长,导致GPU空转,这时候显存占用率可能很高,但利用率很低;另一种情况下就是显存没占满,这时候可以根据任务需求拉大batchsize,或者根据此时内存的情况多开几组实验。
在有些情况下,运行的Python程序可能没能正确的进行中断,导致“僵尸进程”的出现,这时候GPU上被占用着大量显存。这种时候需要手动找出哪些进程没有被正确的关闭,然后手动kill掉:
1 | # 查找python进程 |
或者使用fuser指令,查找和GPU有关的进程:
1 | # 查找与GPU有关的进程 |
不过在有些时候,比如使用了DDP的训练脚本没有正确退出,这时候需要手动kill掉七八个进程,比较繁琐,可以用下面的指令一键清除:
1 | fuser -v /dev/nvidia* 2>&1 | grep python | grep -o -E " [0-9]+ " | xargs kill |
但要注意不要删除此时正在正常运行的进程。
除了nvidia-smi以外,还可以安装nvitop,这是一个用python封装的监控GPU的包,可以得到颜值更高,自动刷新的监控界面:
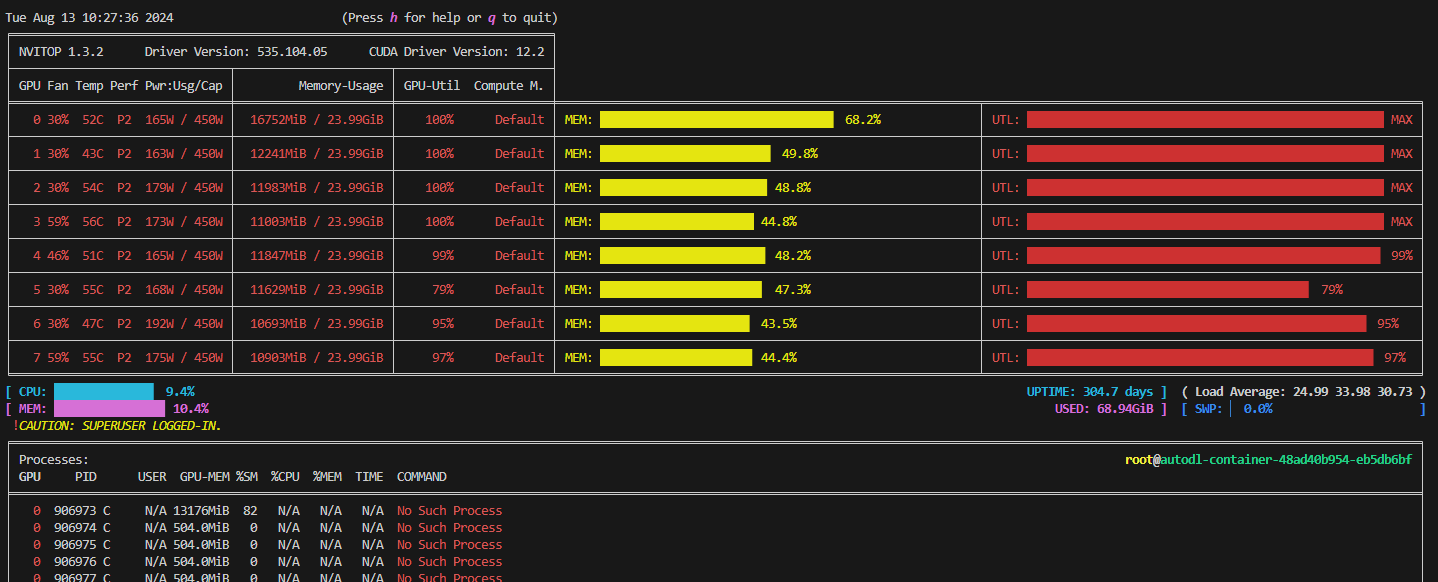
VScode
”一天下午,阳光明媚。
公交车上,高中校服。
少年和少女坐在一起,他们是同学。
“我跟xxx(班里另一个女生)谁更好看?”
“你最好看,我不觉得xxx好看。”
“真的?”
“真的真的,我脸盲。”
嘻笑打闹,言笑晏晏。
到站了,他们站起来准备下车。
少年站起来转身,须臾间,
他腰间被什么一挣,像是铁锁。他猛的从桌子上趴起来。
黄昏时分,房间昏暗。
电脑桌前,屏幕微亮。
他眼前,
只剩下,
vscode的键入光标,在不停闪烁;
logger的损失曲线,在上下起伏;
像是心跳。
荒凉寂寥,
令人无法忍受。“”炼丹误人。“——佚名
VScode是一款轻量级的源代码编辑器,当安装对应的插件后,它可以为用户提供集成开发环境。由于这些好用的插件,在炼丹中,VScode往往比PyCharm这样的Python专用的IDE更受欢迎。除去炼丹任务的性质(一般并不是特别复杂的Python项目),语法高亮颜色等个人习惯,让大多数人选择VScode的是其Remote-SSH远程插件。

这个插件允许用户通过SSH连接到服务器上进行开发,在本地环境和服务器之间进行无缝的切换。当在VScode中安装了Remote-SSH扩展后,左侧就会出现一个“远程资源管理器”,鼠标移动到SSH那一行,会有一个“+”号,然后依次输入登录指令和密码,即可远程登入,例如:
1 | # ssh -p <端口> <用户名>@<主机> |
在~/.ssh/config里会有一些历史记录,有时候需要手动删除那些冗余的记录,不然可能有问题。例如:
1 | Host connect.westc.gpuhub.com |
用这个方案来远程,最美好的性质就是完全“无缝切换”,我们仿佛就是在旁边操作那台不知道在哪里的服务器。每次我们在本地的修改都会被对应到服务器那一侧,同时也可以直接在服务器环境下运行程序,然而我们并不需要在本地配置环境和保留相关代码。据我所知,PyCharm提供的远程功能并没有这么方便,必须基于本地和远程服务器的不断同步。而VScode由于其是一个很轻量化的编辑器,其远程的实现是基于某种“通信”。
在第一次连接时,VScode会在远程服务器上安装一个轻量级的Remote Server:
有时候由于一些原因,服务器端可能下载不了Remote Server,这时候就需要手动下载,然后想办法传过去。
这个Remote Server能够进行一系列的通信和操作,即所有的编辑,调试等操作和命令都是通过这个Server进程来实现的。当我们远程到一个服务器上后,可以查看现在运行的进程:
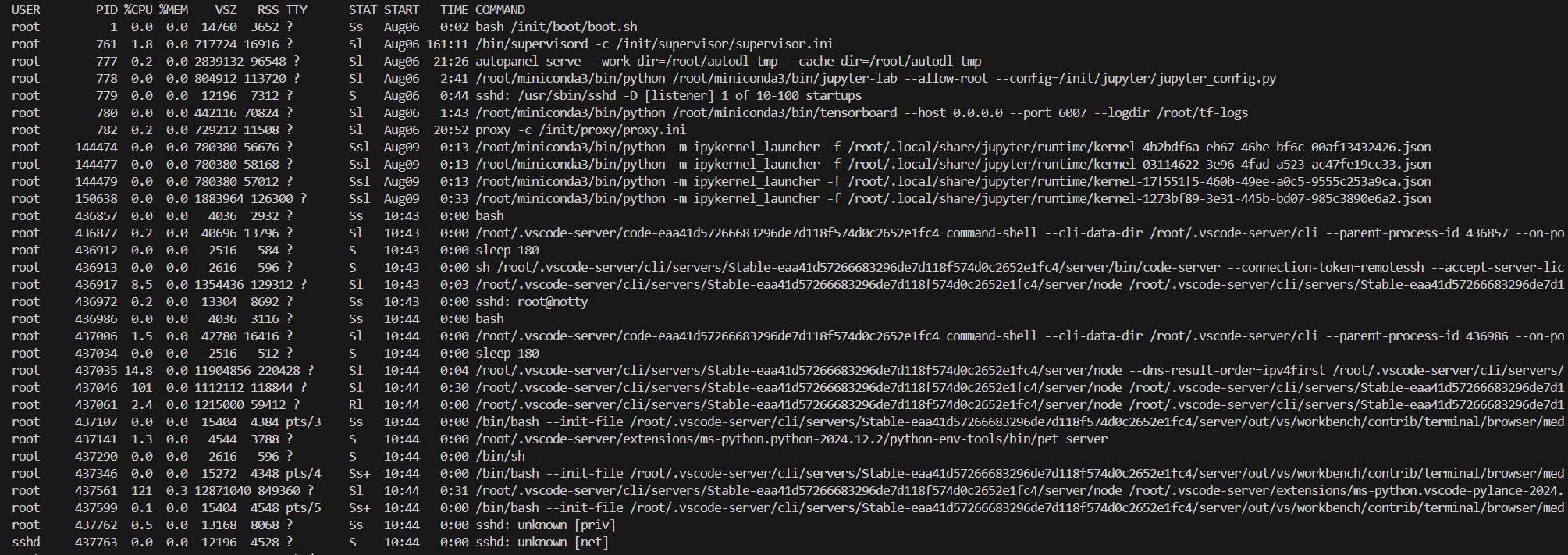
图中那些有.vscode字段的,就是跟Remote Server有关的进程。
但要注意,当我们打开一个远程服务器上的文件时,我们实际上是在本地缓存了这个文件的副本。编辑操作会通过SSH通道同步到远程服务器上的真实文件,这一步骤对用户其实是感觉不到的。这些缓存,插件,扩展,当使用时间长后会攒的非常大。所以最好把本地VScode整个用符号链接移到别的磁盘,在Windows下一般是:
1 | mklink /D "C:\Users\%username%\.vscode" "D:\VisualStudioCode\.vscode" |
很多时候,当很长时间没有操作,或者不小心断网了,VScode的远程也会断开,在重新接入时需要再次输入密码。当你同时开了好几个VScode窗口时,这样会很烦。可以用SSH密钥来避免每次都输密码:首先在本地创建一对SSH密钥,id_rsa是私钥,id_rsa.pub是公钥。然后进入服务器里/root/.ssh,将authorized_keys(如果不存在就手动创建)里填入id_rsa.pub的内容。最后配置一下config:
1 | Host connect.westc.gpuhub.com |
这样就不需要反复输入密码了。
VScode上可以很简单地进入调试模式,从而单步,跳步,逐过程的来看代码运行的中间结果,监视变量和当前堆栈的变量都会显示在左侧。进入这个调试模式需要写一个launch.json文件,在现在,最方便的方法就是将你要运行的DEBUG命令直接发给ChatGPT,让他帮你写这个json文件。对于炼丹来说,一般是需要明确"args"和"env":
1 | { |
有时候你需要查清楚自己现在激活的conda环境的路径或者Python路径,在Linux下可以通过:
1 | # 查找当前Python |
如果不想这样来调试,那就用pdb或ipdb吧,大部分时候都够用了。
但要注意,在用VScode远程的时候,如果因为网络原因或者误操作,导致SSH的窗口断开了连接,那么在服务器上运行的程序也会随之断掉,这对于炼丹来说是不可接受的。这是因为当SSH断开时,系统会发送一个SIGHUP信号,这个信号的默认行为是终止进程,于是Linux将会杀掉与之相关的所有进程。
在Linux/Unix中,通过Remote-SSH远程到服务器上,当我们新建一个终端时,实际上是在远程服务器上建立了一个新的SSH会话(session),并启动一个shell作为会话首领(session leader)。在这个会话期内,会有一个或多个进程组,例如你运行了一个多进程的训练脚本。会话期通常与一个控制终端(controlling terminal)关联,这个终端将为会话中的所有进程提供输入输出(例如我们print出来的内容),如果控制终端关闭,会话期中所有的进程都会收到
SIGHUP信号。当你再新建一个终端时,实际上你会开启一个新的SSH会话,同时启动一个新的shell进程并关联一个独立的控制终端。
所以最简单的处理方法是在运行脚本前加一个nohup,这样将会忽略所有挂断信号。并将输出重定向到当前目录的nohup.out下:
1 | (my_env) root@autodl-container-xxx:~/My_Project# nohup python train.py --outdir=training-runs --cfg=my_cfg --data=./dataset |
或者使用screen或tmux等工具来创建一个持久化的会话。但大部分时候nohup对我来说都够用了。
Docker
有时候许多人都会用同一台服务器,每个人可能有不同的几个环境,这样导致这个服务器里可能会存在太多的conda环境,这会带来一些麻烦。以及,有时候你在Windows上配置了一个环境,但因为版本号等原因,你并不能那么方便的利用conda将这个环境移植到Ubuntu上。所以有没有一种系统级的隔离呢?

Docker技术就可以提供这种操作系统级别上的隔离,实际上如果你习惯用autodl等云GPU平台,每次新建一个实例的时候,autodl其实就是给你开辟了一个docker容器(container),当你远程上去或用jupyterlab的交互界面操纵是,仿佛你就在操作一台Ubuntu的服务器。但实际上那台服务器上可能同时有其他人在租用着,你看不见他们的环境,他们也看不见你的。从直觉的意义上,可以理解为虚拟机,但其比虚拟机轻量许多。
假设你本地的工作机是Ubuntu的,或者你需要给一个Ubuntu服务器安装docker。那么你可以在终端上用几行指令来安装docker。首先:
1 | sudo apt-get update |
安装docker本身,然后将当前用户加入到组里,否则无权限运行docker实例:
1 | sudo groupadd docker |
但docker本身没有对GPU的支持,所以需要再用下面的指令安装nvidia-docker:
1 | # 配置nvidia-docker及其GPG key |
可以通过检查版本来测试是否正确安装了,例如:
1 | (base) test@test-4U-GPU-Server:~/zjw$ docker -v |
或者docker run hello-world,这里hello-world就是一个docker镜像(Image)的demo,用run来运行hello-world,就得到了一个运行实例(上文中的container):
1 | C:\Users\user>docker run hello-world |
在真正炼丹的时候,我们不会每次都从从零开始配置镜像,我们可以在基准镜像的基础上配置我们需要的环境,例如:
1 | docker pull pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel |
docker镜像有其命名规范,如前面的pytorch/pytorch:2.0.0-cuda11.7-cudnn8-devel,以:为分割,前面是镜像名称(IMAGE_NAME),后面是标签(TAG)。
在docker hub中,pytorch提供了不同版本的基准镜像,其中有
runtime和devel之分。runtime阉割的更多,只提供了能作inference的基础组件,比如runtime版本里没有提供编译PyTorch的CUDA扩展的功能。所以建议下载devel版。
当拉取成功后,输入docker images可以查看当前镜像列表:
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
为了安装对应的包,我们需要运行基准镜像:
1 | docker run -d -it --name $CONTAINER_NAME$ $IMAGE_NAME$:$TAG$ |
其中CONTAINER_NAME就是实例的名字,最好取的易于区分。运行后我们需要与该容器进行交互,用以下命令进入交互模式:
1 | docker exec -it $CONTAINER_NAME$ bash |
当我们安装了需要的包后,我们需要将容器保存为镜像。否则当容器关闭后,配置的环境将会消失。即整个环境是不持久的。用如下命令进行保存:
1 | docker commit $CONTAINER_NAME$ $NEW_IMAGE$:$NEW_TAG$ |
最后,我们可以将docker中的镜像导出为.tar包来进行转移:
1 | docker save > /your_path/$IMAGE_FILE.tar$ $NEW_IMAGE$:$NEW_TAG$ |
>是重定向符,用于将docker save的输出保存到文件中。实际上这个打包挺费时间的。
注意,当容器关闭后,是所有内容都会消失,包括上传的数据集(如果整个数据集没有被commit进镜像的话)。我们会在稍后讨论这个问题。
当镜像迁移到服务器中后,就可以运行docker容器了。在nvidia-docker正确安装的情况下,运行:
1 | docker run -d -it --runtime=nvidia --gpus all --name $CONTAINER_NAME$ $IMAGE_NAME$:$TAG$ |
如果需要特别选取某几个GPU,那么可以用--gpus='"device=3,4"'。注意--runtime选项,--runtime=nvidia将会在容器运行时期,使用nvidia container toolkit提供的nvidia-container-runtime作为容器的“运行时期”,其保证了容器可以访问到主机的GPU。
当容器不用的时候,要关闭容器实例:
1 | docker kill $CONTAINER_NAME$ |
如果在实例运行时,做了一些需要被保留的修改,那么要记得docker commit来保存新的镜像。
按照上述操作,我们对于开启的docker实例只能在终端上进行交互,这不是很方便。VScode里提供了Remote-Containers插件!让我们可以像远程一台服务器一样“远程”运行的docker容器,这带来了极大的便利。
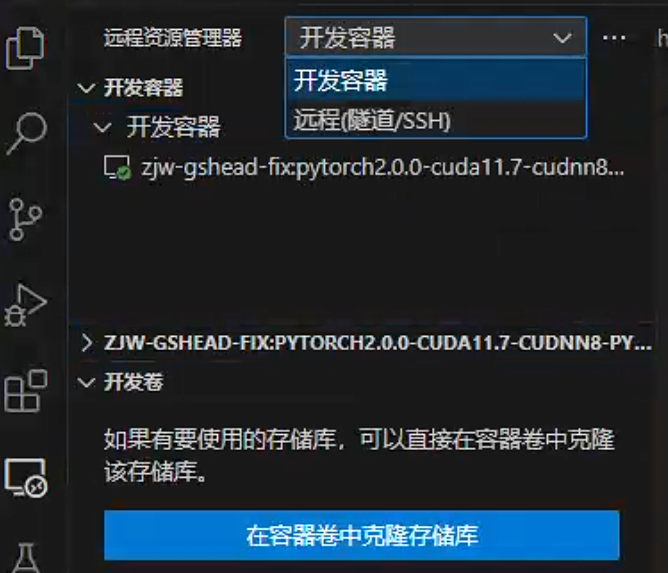
当安装插件后,在远有的远程界面,远程资源管理器就会提供“开发容器”这一子选项,在那里就可以启用,禁止不同的容器。
所以在Remote-SSH,Remote-Containers等插件的加持下,你几乎不需要再用到Vim进行编辑。有些人觉得用Vim很高端,因为很多经验丰富的人都用Vim,但这实际上是一种归谬,是因为那些经验丰富的人在入门的时候只有Vim,然后他们坚持到现在,所以经验丰富。
当然,在一些特殊场合,例如服务器完全不让联网,或者一台服务器上啥也没有的情况,是另一个故事了。
对于一些很小的文件,代码等,在远程到容器内后,可以直接拖进VScode界面来“上传”。但这对大的数据集并不可行,这时候需要用到docker的挂载(mount)机制。我们在运行容器时,可以将docker容器中的目录绑定到主机的目录上,用-v实现:
1 | docker run -v $HOST_PATH$:$WORKSPACE$ $IMAGE_NAME$:$TAG$ |
HOST_PATH就是服务器里的某个目录,比如可以是你存放大规模数据集或者一个炼丹项目所在的目录,WORKSPACE是docker里的目录,这样当容器消失时,HOST_PATH的内容和WORKSPACE里的内容会一直同步,也就不会消失。
那么假如你在运行实例时没有这么做,你还可以单纯将现在运行的容器里的内容复制到主机上:
1 | docker cp $CONTAINER_NAME$:$WORKSPACE$ $HOST_PATH$ |
至此,我们对在Ubuntu上建立docker有了圆满的答案,但在有些时候,比如你为了在实验室工位上摸鱼的便利,工作机装的是Windows,那么会额外带来一些问题。在Windows里docker提供了docker desktop,为docker操作提供了图形化界面。但炼丹时候需要的nvidia-docker并没有提供Windows的版本,这时候可以利用WSL(Windows Subsystem for Linux),我只在WSL2上尝试过,并且对Windows的版本应该也是有要求的。基本逻辑是,我们进入cmd,运行:
1 | wsl --install -d Ubuntu-20.04 |
安装成功后,我们应该可以在开始菜单里找到这个子系统,然后我们在这个子系统里安装nvidia-container-toolkit工具包:
1 | curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ |
然后我们进入docker desktop修改docker daemon(docke的核心组件,负责管理容器的生命周期)的设置:
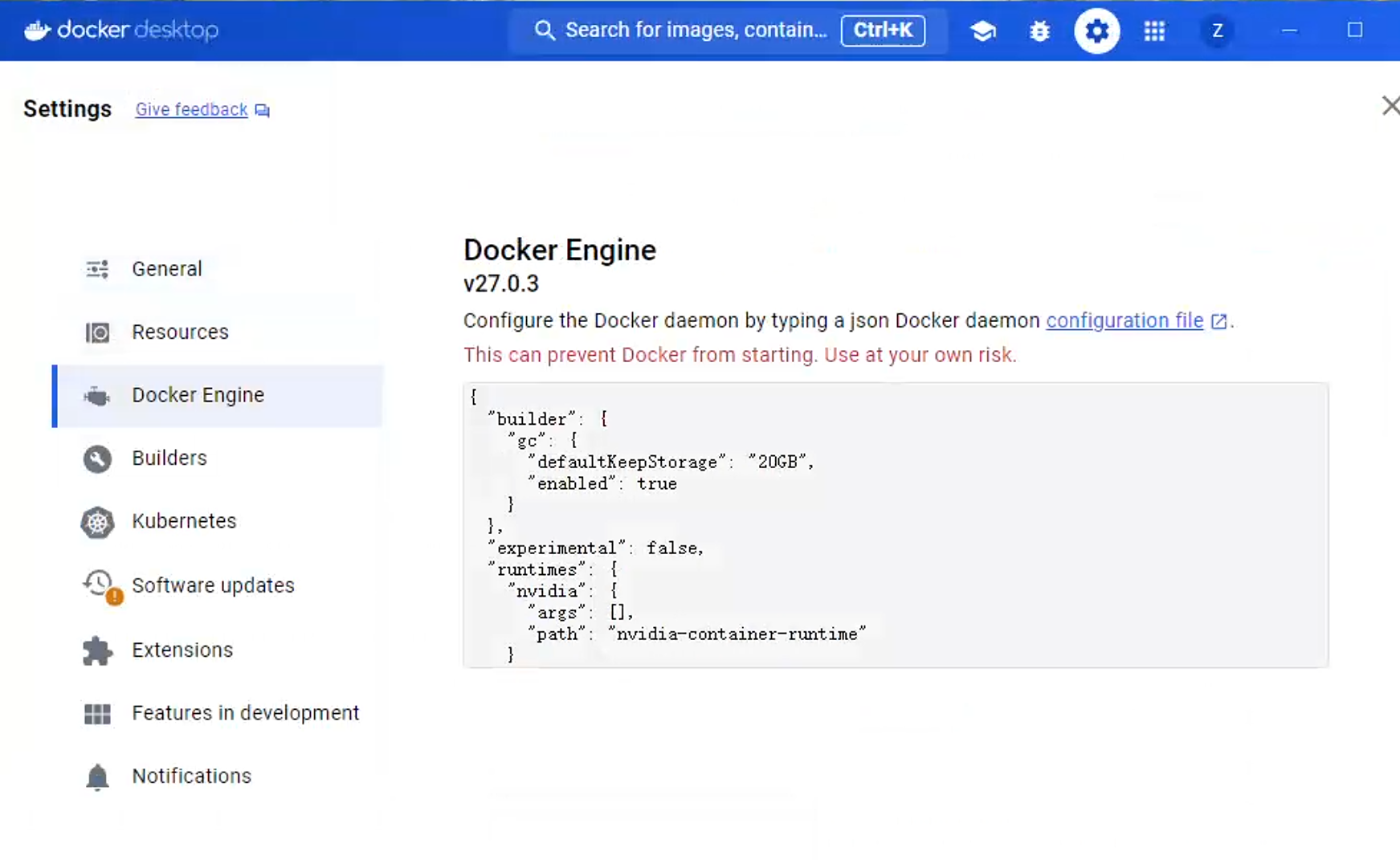
这样在Windows系统上也能--runtime=nvidia了,不过这个过程中可能会遇到很多BUG。网上更多的推荐是在WSL里直接安装整套docker,nvidia驱动,但这样比较麻烦,还需要设置代理让WSL联网等。
当完成这一步后,在Windows里运行的docker实例也可以有GPU了。但事情还没完,这种借助WSL2子系统保存的镜像,当放到服务器上时,会遇到关于libnvidia-ml.so的报错。例如运行nvidia-smi:
1 | ``` |
这个报错的原因是WSL中的显卡实现行为的不同,在用nvidia-docker启动时,为了容器和主机驱动版本的兼容,nvidia-docker并不会安装驱动到镜像中,他会自动地将主机上的驱动(nvidia-driver,CUDA等)强制映射到容器中。也就是说道理上,其实我们不应该在镜像里安装跟GPU相关的驱动。但WSL中本身对GPU的实现是通过一种模拟的方式,其具有特殊的wsl-nvidia-driver,而我们为了debug和配环境,往往会在Windows上运行
docker --runtime=nvidia,然后再打包镜像,这样在这个镜像里,他们建立的链接都是关于wsl-nvidia-driver的,而当在Ubuntu服务器上强制映射后,容器并不会索引到服务器本机的驱动。
所以一种解决方法是在本机配镜像的时候不要用GPU,即不添加--gpus all等项,但这样会带来问题(例如安不上CUDA扩展,测试不了程序等),另一种解决方法是当容器运行后建立软链接,首先查找libnvidia-ml所在的位置:
1 | find --name libnvidia-ml* |
然后可以编写如下脚本来进行软链接:
1 |
|
然后就应该没什么问题了。
Misc
在实际炼丹中,我们还需要知道并运用Git,GitHub,Tensorboard/Wandb等,这些内容以后有时间在写,这里列个TODO list作为”炼丹中缺失的一课4“的可选内容:
- [ ] Git,Github
- [ ] Tensorboard/Wandb等以及其他打log的方法
- [ ] config/argparse/click等配置管理
- [ ] 实验管理,logger等
- [ ] 优雅的trainer
- [ ] hook机制
- [ ] 装饰器,register
- [ ] 混合精度相关
- [ ] DP与DDP
End
”那时他还只是一个对”人工智能“抱有憧憬的本科生,对着那些玄而又玄的公式发呆,查着资料习惯那些API的用法,希望自己能有好多好多显卡来炼一些好玩的东西。大学新生伊始,许多事情他想不明白,提到的时候尚需用手比比划划。“

