
“沿着风的轨迹,乱舞蹁跹,困于死水之间。”
这篇blog想记录一下我在“试图”(因为没做出来)做毕设的时候,关于人脸/人头数据的一些预处理。
预处理(preprocess)是非常重要的一个环节,在刚学习炼丹时,预处理只是对类似图片数据那样的,做均值-标准差归一化什么的,你甚至可以借助torchvision轻易的实现:
1 | transform = transforms.Compose([transforms.RandomRotation(20), |
但当接触的任务变得复杂的时候,就会发现预处理往往比炼丹本身要复杂。预处理本身是需要一些先验知识的,比如一些医学图像处理的任务里,那些CT扫描或MRI图像的格式并不是三通道的RGB,需要自行进行处理,以及他们一张图分辨率往往非常大,所以可能需要自行打patch;在有些跟信号处理,频谱挂钩的任务里,需要对时频分析,功率谱,维纳-辛钦定理有一些认识。但这些好歹都还是“theoretical”的问题,只需要“了解”这些概念,然后读一些文档,就能跟上了。
由于我毕设试图做关于人头相关的,预处理的步骤是为了从单目的人头视频帧中提取一些先验。这就有些一言难尽,这些预处理管线往往都基于了许多人头人脸之前工作的pretrained model,然后将许多仓库进行穿针引线,最后打包成一个shell脚本来一键启动。这个往往是非常“technical”的事情,不同作者预处理的方式,得到的数据集的内容和格式都有所不同。以及这里有许多繁杂的概念,不是那么好理解。
但大多数时候,把前面工作的数据集制作的管线直接拿来follow,或者直接用其制作好的数据集,也不失为一种洛可可风格的方式。
所以这篇blog旨在记录INSTA和PointAvatar两篇工作的预处理管线,前者是马普所的,后者是苏黎世理工的,这两篇工作都是为了从单目视频中重建出一个人头,或者叫“Avatar”。剖析这两个预处理管线主要是为了其中的细节,所以很难具体的按某个特定逻辑来撰写,不可避免的会显得生硬一些。但大概会包含以下要素:
- 如何从单目图像中提取FLAME系数。
- FLAME的灵活使用。
- landmarks(人脸关键点)之于预处理中的作用。
- 某科学の线性代数。
INSTA
INSTA的数据预处理分为三步:
- 先从MICA中运行
demo.py,获得一个identity.npy。 - 然后用Metrical-Tracker,将一段视频和刚才提取的
identity.npy作输入,得到一系列的输出。 - 最后用INSTA中提供的脚本
generate.sh来将刚才那一系列输出再处理成需要的样子。
我们一步一步来看,MICA也是马普所的一篇工作,目的是从一张二维的图片中恢复基于FLAME的3D topology。第一步是得:
1 | python demo.py -i ./demo/input -o ./demo/output |
这个操作是为了得到一个identity.npy,具体来说,这个identity.npy是先将输入图片,送入一个预训练好的ArcFace,ArcFace是一个很成熟的用于人脸识别的模型,ArcFace是用一种辅助度量的loss来进一步帮助以ResNet-50为backbone的分类网络来分类,它已经是2017~2018年时候的事情了,我们现在已经不用关心其本身了。不过那时候是一个很好的年代,不仅是因为炼丹的刀耕火种在如火如荼的进行,还因为那时候我还能和女同学言笑晏晏。
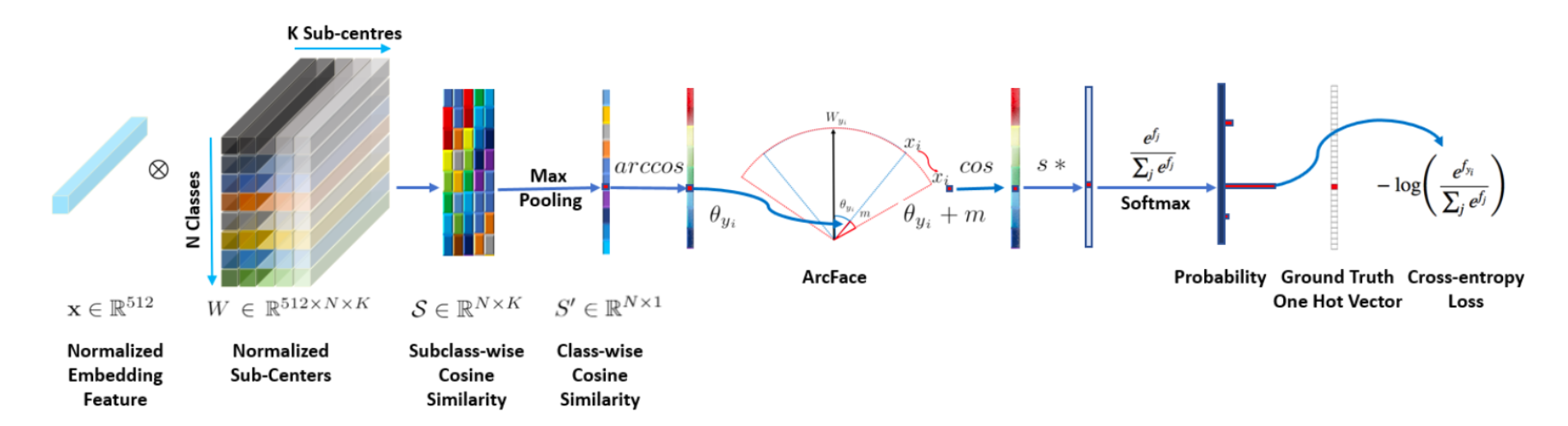
总之它是一个成熟的分类网络,那样对于任意一张“wild-image”的人脸输入,它会有不同的“响应”。MICA里继续用几层layers将ArcFace计算出的特征向量再映成FLAME里的形状系数:
如果我们进入MICA中的demo.py,会发现identity.npy保存的是FLAME的形状系数,即上面的$\boldsymbol{z}\in \mathbb{R} ^{300}$。demo.py还会输出出kpt7.npy和kpt68.npy,这里的人脸关键点并不是估计出来的,它的来历和上一篇blog里讲的从RingNet里提取出的固定的embedding里抽landmark是一样的,是从FLAME中预标定好的对于不同landmark的顶点索引中查出来的。是一个象征意义的三维的landmark。而我们朴素意义上的“landmark detection”一般发生在裁剪图片的时候,例如:
1 | app = LandmarksDetector(model=detectors.RETINAFACE) |
这里的kpss就是我们以为的那种用NN估计出的二维的landmark,这个的功能和上文的ArcFace,已经完善的部署在了insightface或face_alignment库中。
在后文中会用多种方式获得,并多次使用landmark。landmark在曾经应该是为了帮助人们进行人脸识别,表情识别。在以前依赖手工特征的时候,这很有用。但现在这两个任务已经基本宣告“closed”了,那么在这两个管线里,“landmark是用来对齐不同knowledge的一个载体”,往下看就知道了。
接下来就到了Metrical-Tracker的环节:
1 | python tracker.py --cfg ./configs/actors/xxx.yml |
Metrical-Tracker和MICA其实指代的是同一篇工作,只不过前者是后者的一个扩展,他们编写了一个基于python的仓库来实现对视频中的人头进行“tracking”。在INSTA原文中的表述是:
To this end, we use the analysis-by-synthesis-based face tracker from MICA [61], based on Face2Face [51] using a sampling-based differentiable rendering. We refer to the original paper [51] for more details. We extend the optimization with two extra blendshapes for eyelids and iris tracking using Mediapipe [34]. In contrast to MICA, we also optimize for FLAME shape parameters, with regularization towards MICA shape prediction instead of the average face shape as in Face2Face [51]
这里所谓的“analysis-by-synthesis-based”只是一个名字,最早是因为通过2D图像来估计3D的人脸,这个操作本身是病态(ill-conditioned)的。于是就有了将3D模型与一组用于渲染的参数一起优化,来使渲染出的照片更接近真实图片。这个思想就被称作“analysis-by-synthesis”,放在现在看来已经很平常了。
于是我们可以从tracker.py开始阅读,这是一个行数挺多的类。但在此之前我们会注意到在global里有:
1 | mediapipe_idx = np.load('flame/mediapipe/mediapipe_landmark_embedding.npz', allow_pickle=True, encoding='latin1')['landmark_indices'].astype(int) |
这里就是为了引入Mediapipe的起手式,Mediapipe是Google做的一个非常成熟的机器学习管线,可以支持许多感知上的任务,比如在姿态估计,手部估计等等。其最后上线的模型一定是被Google的工程师精心调优过的,而且也是在Google的大规模私有数据集做出来的,所以结果是有保障的。
实际上,我们更习惯的face_alignment库也可以检测上下眼皮(eyelids),但不能检测虹膜(iris)。以及face_alignment可能检测上下眼皮的准确度稍逊于Mediapipe(Google力大砖飞的操作在MoveNet里我已经体会过了,他们为了让做瑜伽时候的姿态估计准一些,爬了YouTube上几乎所有的瑜伽视频),所以在整个管线里整合来自三处的landmark进行监督(Mediapipe,face_alignment,RingNet)可热闹极了,下面我们会提到。
首先,Mediapipe在dense模式下,是预测478个关键点。后10个分别就是左眼虹膜和右眼虹膜,即left_iris_mp和right_iris_mp。由于他们是Mediapipe版本更新后追加的,所以是后10个:
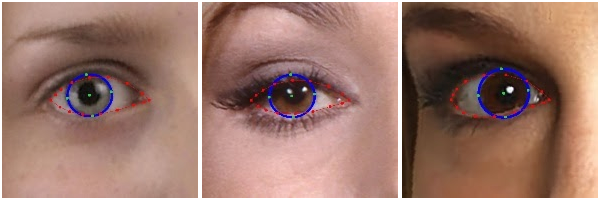
上图的五个绿色点,就是对虹膜的定位。
而left_iris_flame和right_iris_flame对应五个FLAME模板上的顶点,这十个FLAME上的顶点的位置,在拓扑上对应着上面虹膜检测的那五个点。他们的作用往后会看到。
我们先说回来tracker.py的逻辑:
1 | class Tracker(object): |
第一步是先self.prepare_data(),这一步的核心基本是从视频和输入的identity.npy里生成每一帧的图片和landmark:
1 | class GeneratorDataset(Dataset, ABC): |
基本逻辑是先用ffmpeg对视频进行抽帧,然后对每一帧的图片进行处理,分别用face_alignment和Mediapipe提取landmark和dense landmark。当然,在这之前会通过bounding box对输入图片进行裁剪(self.config.crop_image默认为True),bounding box当然也是用face_alignment库给估计的。这些数据会按如下结构存下来:
1 | subject |
有了存好了的图片和两款landmark,接下来self.prepare_data()会再实例化出来一个dataloader来读数据。代码里叫作ImageDataset,但它传出来的不止有image:
1 | def __getitem__(self, index): |
它会把之前在MICA里处理得到的identity.npy也一并取出来。
然后在初始化tracking的self.initialize_tracking(),会对所选取的“关键帧”(一般就是第一帧,或者你从这段视频中截取用来计算identity.npy的那一帧)进行一下“预热”。这里最关键的是要进行一次self.optimize_camera来大致先优化出相机系统,至少得保证人头能比例合适的打在显示屏上。同时,在self.optimize_camera里会调用一次self.create_parameters对参数进行初始化:
1 | def create_parameters(self): |
这里罗列的就是tracker对每一帧要优化的所有参数。其中look_at_view_transform是PyTorch3D提供的计算相机外参(w2c)的接口,但这里只输入了dist(可以理解为相机半径),没有输入角度等,所以就是初始化了一个旋转矩阵$R$和平移向量$t$:
$R$里的负号大概是因为在PyTorch3D的坐标系规定下,世界坐标系转相机坐标系有一个沿Y轴顺时针转90°的事情,右手定则一下可知方向为负,所以有两个-1。
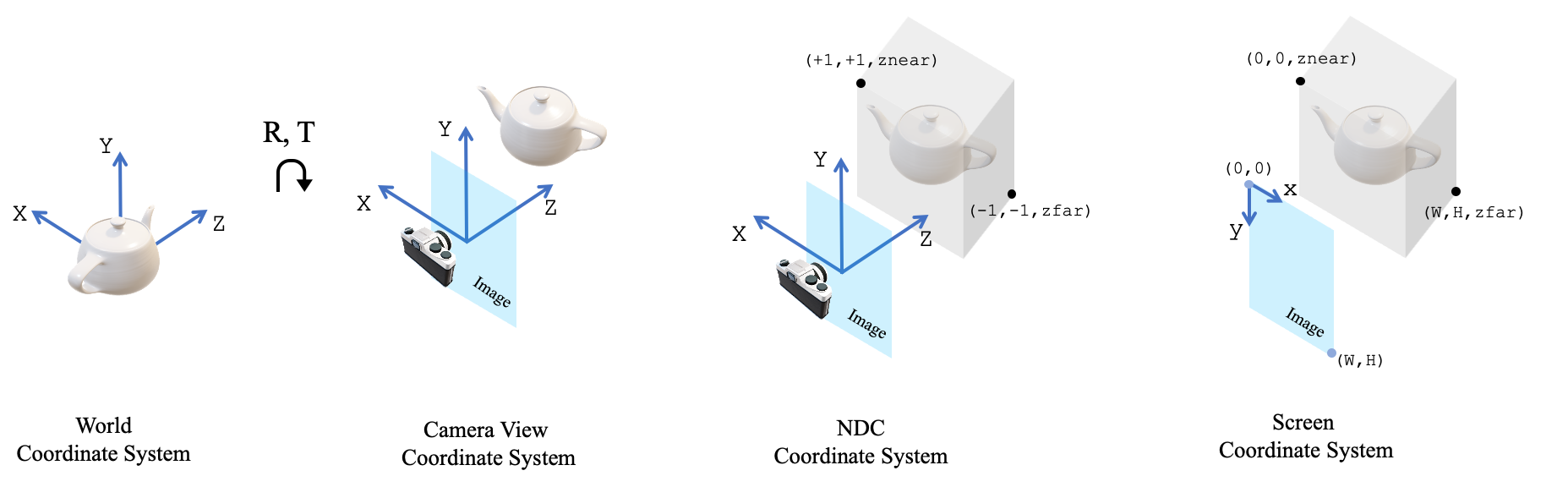
principal_point是相机系统中的$(u_0,v_0)$,用于锚定图像中心。
这里的matrix_to_rotation_6d,指的是2019年的CVPR中的一篇文章,对深度学习中如何学习“旋转”的一个结论。这个6D的说法是,考虑一个旋转矩阵,只优化它的第一列和第二列一共6个参数,所以叫6D,然后第三维用施密特正交化解算出来:
但据一些网上的评论,优化这个跟优化四元数也差不多。然后我们可以看一下self.optimize_camera里的优化逻辑:
1 | self.cameras = PerspectiveCameras( |
PerspectiveCameras是PyTorch3D中将相机系统进行封装,便于执行透视变换的一个类,旋转矩阵,平移向量,焦距等都作为可优化的参数。然后根据此时的flame系数(表情,形状,姿态)匹配出lmk68和lmkMP,前者还是之前RingNet里的那个,后者原理一样,但后者的那个连接Mediapipe和FLAME之间的embedding应该是他们自己做的。
这两个pipeline或多或少都对标准的FLAME的调用进行了修改,仔细看代码会体会到,比如有的禁用了某些参数,有的返回值有一些差异,以及不同管线里选取的基向量的数量也不同。
总之拿到了这两个landmark以后,调用PerspectiveCameras里的变换,就能计算出在screen space里的坐标了,然后再和之前在生成数据集时,从2D image里预测出的landmark作比较,然后梯度下降,借此更新FLAME的系数。这种做法本质上就是用预训练好的landmark检测器来对齐2D image和FLAME上的关键点。
而且事实上,这样做能成功的原因是FLAME当时在做这个参数化模型的时候,就用的是在$r=1$的轨迹上的相机来单位化的。所以在用R, T = look_at_view_transform(dist=1.0)来给定相机初始位置时,基本也能得到一个大差不差的人头。这也是FLAME里坐标的量级在:
1 | v 0.065016 -0.010475 -0.049408 |
这个范围的原因。
这里我们其实注意到了一个细节,self.flame在输入时:
1 | _, lmk68, lmkMP = self.flame(cameras=torch.inverse(self.cameras.R), |
关于FLAME的姿态,只输入了眼睛和下巴,以及self.eyes和self.jaw在初始化时实际上是:
1 | self.eyes = nn.Parameter(torch.cat([matrix_to_rotation_6d(I), matrix_to_rotation_6d(I)], dim=1)) |
所以他们用的其实是那个6D表示,并不是FLAME/SMPL中常用的轴角式。而且缺少了颈部和根结点。
FLAME里一共应该有5个结点,一个rot,一个neck,一个jaw,一个left-eye,一个right-eye。
我们可以在FLAME.py中FLAME的forward方法里看到,neck和rot已经按缺省时初始化为单位阵处理了。同时由于这里用了6D表示,在lbs.py里也有相应的修改:
1 | # rot_mats = batch_rodrigues(pose.view(-1, 3), dtype=dtype).view([batch_size, -1, 3, 3]) |
另一个在原版FLAME上的改动是对于self.eyelids,虽然在优化相机时没有输入它,但在后面正式开始优化时,眼皮的系数也会送进去。原版的FLAME并没有规定用参数来驱动眼皮,所以这里的操作是load进两个.npy文件,一个是l_eyelid.npy,另一个是r_eyelid.npy。这两个都是大小为[5023, 3]的numpy array,只不过在大部分的索引下值都为0,只有在对应眼皮的位置的值不为0,同时在FLAME的forward里,用:
1 | # Use linear blendskinning to model pose roations |
来将LBS后的顶点的眼皮处进行进一步修饰。所以eyelids其实就是学习两个参数来放大和缩小那几个特殊位置的结点。
在self.initialize_tracking的最后,会执行一次self.save_canonical,会将在关键帧下“校准”后的形状系数存下来。但很烦的是它在保存时用的是trimesh.Trimesh,用这个库来组织.obj,保存纹理坐标什么的比较费劲。建议换用PyTorch3D里的save_obj。
优化相机只会被调用一次,后面反复被调用的是self.optimize_color,
1 | def optimize_color(self, batch, pyramid, params_func, pho_weight_func, reg_from_prev=False): |
这个函数是优化的主体,为了让tracking更准,输入的不止是当前帧的图像,其实是当前帧图像的高斯金字塔。这是一个常用的技巧,通过从多尺度下的优化来获得更精确的结果。在每个层级下,都进行一轮的优化。
注意这里进行了对虹膜的优化,这就是之前left_iris_flame,right_iris_flame,left_iris_mp和right_iris_mp的用处了,虹膜直接就可以从Mediapipe的dense landmark和FLAME的顶点拓扑里查表查出来了。于是预训练好的Mediapipe中的虹膜检测模型,就可以“监督”现在复原的FLAME准不准了。
这里有一处细节,在优化的时候,对于形状系数,我们使用的是self.shape,而最开始的identity.npy是作为self.mica_shape存在的,其只作为正则项:
1 | losses['reg/shape'] = torch.sum((shape - self.mica_shape) ** 2) * self.config.w_shape |
也就是说每一帧的shape还是会有轻微差别的。
我们注意到,与原始图像做loss的“color loss”(或者叫感知损失),其预测出的图像是由:
1 | albedos = self.flametex(tex) |
这样获得的,F.grid_sample在之前的blog里已经用过许多次了,我们这里是要探明一下这个self.flametex(tex)。这个机制其实是FLAME后续更新的,我们可以在FLAME官网里下到一个叫TextureSpace.zip的东西,里面有一个1.2GB的文件FLAME_texture.npz。这个文件是通过用FLAME拟合FFHQ数据集,从而得到一个纹理空间,也就是我们想要的UV map。和处理表情,形状时一样,也进行了主成分分析,得到了表示纹理空间的各个基。用Python打开这个文件,可以看到里面压缩着['vt.npy', 'ft.npy', 'tex_dir.npy', 'mean.npy']这四个数组,vt就是我们熟悉的作UV映射的纹理坐标,形状是[5118, 2];ft用于描述一个面的三个点,对应着哪些纹理坐标,大小为[9976, 3];tex_dir就是得到的关于纹理空间的基向量,大小为[512, 512, 3, 200],200即是主成分的数量,在Metrical-tracker这个项目里只取了前140个。然后mean就是所谓平均脸,大小是[512, 512, 3]。

左侧就是那张平均脸的纹理图,右侧是前12个纹理空间上的基向量。
实际上优化当前帧下的纹理是最耗时的,如果我只是想要形状和表情,要不要这个纹理的监督其实有点“subtle”。但由于管线的这一部分本身是为了做face tracking的,所以也是很正常的。
这里有一个关键的事情是,第$i+1$帧的参数是从第$i$帧优化出来的参数里微调过来的,这是很自然而且方便收敛的。
优化完每一帧,都会把那一整套我们关心的参数存下来:
1 | def save_checkpoint(self, frame_id): |
文件后缀为.frame,以及在该帧下的FLAME拓扑(用LBS计算出的顶点们)也会被存下来,存成.ply。同时还会存一些杂七杂八的东西,不过不是很重要。
注意在存的时候,还多存了一份opencv约定下的相机,实际上后面最后用到INSTA里的也是opencv版的,很多框架之间的相机坐标系并不一样,有时候会很烦:(图源自)
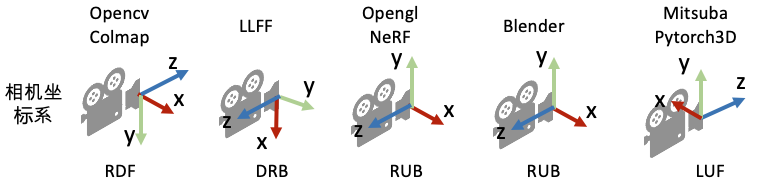
据此,在一些民间群里延申出了一张梗图:
因为很多时候,比坐标系变换更迷的事情是:“我根本不知道我所在的仓库用的是哪个coordinate systems!”
至此,文件结构成了:
1 | Subject |
最后的那个video.avi是tracking结果的可视化:
最左边是对齐后的图像,第二个是FLAME的纹理空间拟合出的结果,第三个是landmarks。其中绿色的可以理解为“gt”,因为他们是用Mediapipe和face_alignment估计出来的。红色的是预测出的landmarks,通过计算出顶点位置后,用一些embedding查表查出来的,然后最右边就是此时的FLAME拓扑了。
这里需要指出一些事情,首先,这个tracker最后输出的6D表示,不能无缝衔接到最主流的那个FLAME类和lbs.py的实现里。其次,这种tracking并不是对我们理解的FLAME的真实还原,这么说的是因为,在我们想象中的FLAME表示里,应该是人头发生旋转,比如旋转rot和neck来做出姿势,而相机始终是不变的。但这里其实我们没有建模FLAME里的rot pose,这是因为估计的结果是为了训练NeRF(instant-ngp)方便,所以这里其实是认为人头不曾转动,是相机的角度在转,变换上是等价的。另外,FLAME中的neck pose被忽略了,这个也比较微妙,因为后面在作face parsing的时候,脖子的部分其实就被截掉一块了。
然后就来到了INSTA下的重新组织数据集的环节,第一步是从那些*.frame里拆解数据,调用dump_frame:
1 | def dump_frame(payload): |
在dump每一帧时,也会把每一帧的FLAME系数都储存下来:
1 | def dump_flame(flame, frame_id, output): |
要注意到最后存下来的是相机外参的逆(c2w),相机内参由另外一个函数来储存,用第一帧中相机内参的结果来代表所有帧下的相机内参。最后外参连同内参划分训练,验证,测试集后储存成.json。
到这一步,所有关于相机系统,FLAME系数的预处理已经完成了。接下来就是处理对齐(切割和裁剪)后的图像,一般来说是要把人头从背景里抠图(matting)出来,然后有时候想去掉脖子以下(下至肩膀)的部分,所以会用语义分割(semantic segmentation)得到哪个部位在哪,然后作“解析”(parsing):

将人从视频的每一帧里扣出来的用的是RobustVideoMatting(RVM),然后语义分割是通过一个在CelebA-HQ上训练BiSeNet的仓库实现的。这两篇工作都来自于那个还能叠积木的时代,大概是经过了马普所人员的检验,所以就这么用了。
最后,INSTA的数据格式就是:
1 | Subject |
实际上最后一部分的parsing和文件结构里要存meshes只是INSTA的需要,从普适的完成单目视频重建来看的话,倒也不需要。在INSTA里想在“脸部区域”维持FLAME的几何先验(因为FLAME里没有头发,把全部pixel都这么做会让效果劣化),就这么一个loss,至少十年功力:
因为实现这么一个loss,就需要在预处理的时候多导出每一帧时的mesh和seg_mask,将光线投射的终点与标准mesh光栅化后得到的深度作对齐。我根本不知道怎么在instant-ngp的框架下体面的实现这个功能,还有那个在canonical space下来做BVH(bounding volume hierarchy)的操作。很遗憾,以前花大量的时间炼没用的丹来着,现在已经到Gaussian Splatting的时代了,不知道什么时候能学一手这些。
Point-Avatar
说实话,我应该一开始就follow这篇工作的预处理管线的,因为这个管线更注重于提取做单目视频重建的信息,运行起来没有优化一整套,以及这里是直接用DECA的结果(再稍微平滑一下),所以会快很多。
在Point-Avatar之前,这个组还有一篇叫IMavatar的工作,数据预处理的管线是继承过来的。在其仓库的./preprocess下写的很清楚,而且环境和一些需要下载的东西准备好了以后一键启动preprocess.sh就好了,写的很清楚,比INSTA要跳转好几个仓库要清晰。
首先,用ffmpeg抽帧,然后用一个现成的抠图网络MODNet来分割出人头来。有趣的是MODNet实际上是刚才提到的RVM正文里的baseline。
其主体是用DECA来估计一整套参数。DECA在上一篇blog里提到了,用Encode-Decode的范式实现了从单张图片里估计FLAME系数和相机参数。这里我们着重剖析一些细节:
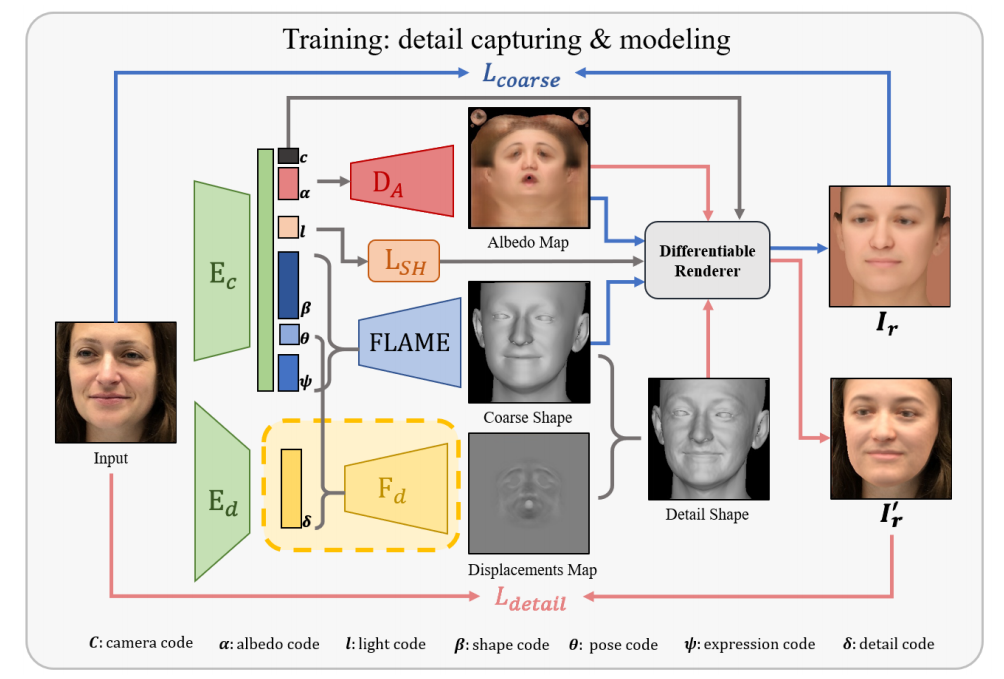
我们再回顾一下DECA的管线,通过$\mathrm{E}_{\mathrm{c}}$我们可以从图像中得到一些属性的latent variables,所以IMavatar预处理的第一步是运行/demos/demo_reconstruct.py来得到这些隐变量,或者说叫“code”(编码)。这里形状系数shape code $\beta\in\mathbb{R} ^{100}$,表情系数expression code $\psi\in\mathbb{R} ^{50}$,这两个是“straight-forward”的,可以直接带入FLAME。然后这里的pose code $\theta\in\mathbb{R}^{6}$,并不是$\mathbb{R} ^{15}$。因为DECA里忽略了眼球和脖子的旋转(6+3),在DECA的FLAME.py的构造方法中:
1 | default_eyball_pose = torch.zeros([1, 6], dtype=self.dtype, requires_grad=False) |
在forward的时候,对neck和eyeballs保持了缺省:
1 | batch_size = shape_params.shape[0] |
以及通过考察lbs.py,可以知道这里pose就是用的轴角式表达。
这里还剩一下一个比较奇怪的camera pose $c\in\mathbb{R}^3$,如果我们检视大多数$c$,一般第一个值是9.0~10.0,然后第二个和第三个值很接近0。这个说起来比较复杂。我们注意到在前面的$\theta$里,我们是建模了根结点的旋转,或者叫全局旋转的。这是符合我们想法的,所以相机外参的旋转默认为一个单位阵。但这并不意味着$c$就是相机内参,但它确实也和相机内参有关。事情是这样的,我们输入给DECA时的图像并不是对齐的,一般情况下:

比如输入512×512的图像,我们会先利用人脸检测器把人脸给裁下来,得到只含人脸的子图。这张子图的大小在DECA是224×224,标定原图和子图上的三个点,在./decalib/datasets/datasets.py中可以导引出一个齐次变换:
1 | src_pts = np.array([[center[0]-size/2, center[1]-size/2], [center[0] - size/2, center[1]+size/2], [center[0]+size/2, center[1]-size/2]]) |
比如在上面的图中,人头的比例基本是不变的,所以要做的其实就是一个剪切(shear)变换,这种情况下estimate_transform最小二乘出来的就是:
1 | tensor([[ 9.7807e-01, 3.1584e-16, -1.2275e+02], |
然后变换和裁剪的过程会由skimage.transform里的warp完成,就得到了右图。
所以DECA对latent code的获得是从右图来得,而FLAME模板里的坐标,范围一般在±0.1周围。然后,$c$的目的在于对这些坐标进行变换,使其变换后可以贴到原来的那个图上。我们以landmark2d为例,最终的目的是让得到的landmark2d和原图可以像下图那样匹配:

我们考察最左边的关键点,其$x\approx155.2$。而其本身从verts, landmarks2d, landmarks3d = self.flame(...)里投影出来的时候,约为$-0.0772$。在deca.decode里,这个landmarks2d在从FLAME里出来以后,会先进行util.batch_orth_proj,然后又有个transform_points。在这个函数里面有两个很奇怪的操作:
1 | def transform_points(points, tform, points_scale=None, out_scale=None): |
point_scale是[224, 224],h和w都是512。所以整个过程是:
为了优化上式中的$t$和$s$,其中$\mathcal{S}$和$\mathcal{C}$是刚才估计出来的那个齐次变换的逆:
1 | tensor([[[ 1.0224e+00, 2.0415e-16, 0.0000e+00], |
可以看到$\mathcal{S}\approx1.0224, \mathcal{T}\approx125$。我们可以忽略掉$c$中的$t$,它的预测值其实是$0.004187$。那样我们直接带入$x=-0.0772$,就可以得到$s\approx9.46$,这回答了为什么$c$中的第一个元素总是接近9~10。
总之我们现在对deca.encode出的东西有了充分的认识,然后下面在这个管线里要进行的是optimize.py,这里我们会发现,在这个脚本的入口,手动规定了内参:
1 | parser.add_argument('--fx', type=float, default=1500) |
跟这个内参对应的是代码里会将相机据原点的距离先给成torch.tensor([0, 0, -4]).float().cuda(),这是INSTA预处理管线里的四倍。这个有点一言难尽,这是因为在optimize.py里顶点什么的规模也都被乘4了。我不知道作者是不是在IMAvatar的时候就这么写了,我也不是很好说明这么写的意义是什么。只是在PointAvatar里,由于最开始是初始化一个半径为0.5的球面点云,所以将FLAME的顶点们乘四倍正好想凑个单位球也算是合理……吧?我不知道在这种优化的情景和规模下,以factor=4来scale或者不scale……变化会很大吗?
1 | # CAREFUL: FLAME head is scaled by 4 to fit unit sphere tightly |
由于在DECA里已经估计了人头的全局旋转,所以这里对于相机外参的处理是只学习平移向量$\mathbf{t}$,旋转一直是一个单位阵。所以在IMAvatar和PointAvatar中,其实并不存在“cam pose”这一概念。在这两篇工作中,人头的变形和旋转,都是将固定的,基于FLAME的点$x_c$输入进MLP中,来解算出实现“变形”的属性:
$x_c$在IMAvatar中是用Ray Marching技术,找到的点;而在PointAvatar里,则就是点的坐标本身。$\theta,\psi$分别是FLAME的姿态和表情系数,这些是显式的输入,在训练时可以通过预处理后的数据中获得,在测试时可以手动设定新视角和表情。$\mathcal{P},\mathcal{E}$是用MLP计算出的blendshape,$\mathcal{W}$在这里专指对某个特定的$x_c$而言的关于不同结点的权重,也是用MLP学到的。$J(\psi)$指的是在有$B_E\left( \psi ;\mathcal{E} \right) $修正下估计出的结点位置,这一步在实现上是通过维护一个标准FLAME模板得到的。相比于INSTA的那种做法,我个人更喜欢这种方式来实现变形。虽然这种变形本质上也是炼丹炼出来,但就是个人情感上更好接受。
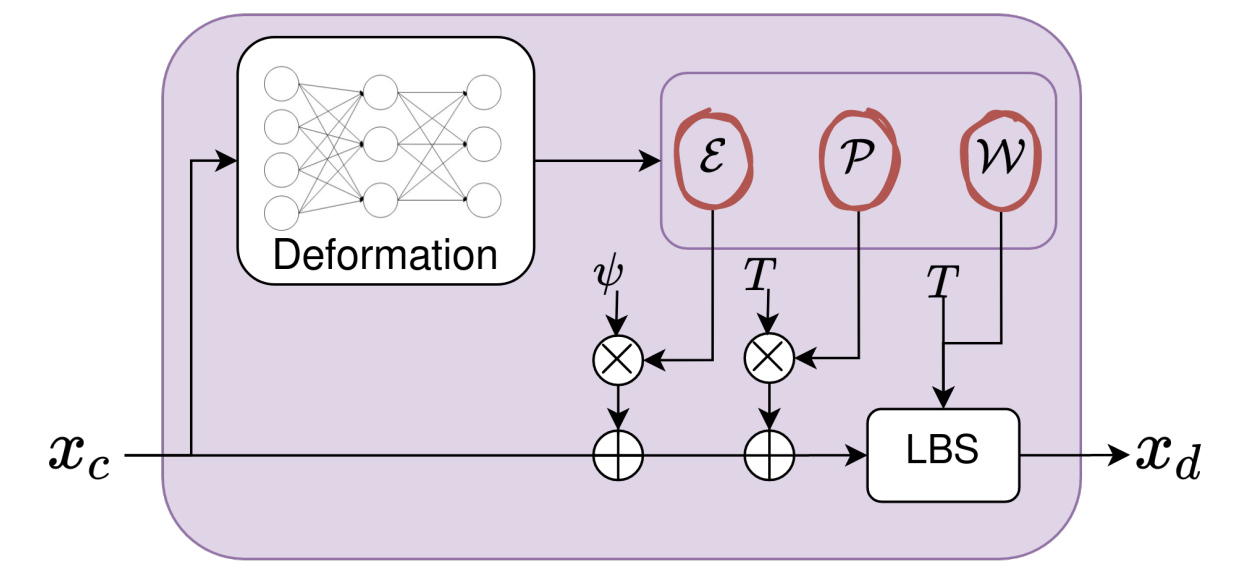
这个操作相比于标准FLAME的变形(Morphing),可以称其为“Implicit Morphing”,因为相比于标准的,回归出来的$\mathcal{E},\mathcal{P},\mathcal{W}$,我们在这里需要用learning-based的方法来给FLAME中没有的点“reassign”那些属性。
说回optimize.py本身,optimize.py的优化的目标主要是相邻帧之间的系数变化不要太大,以及通过landmarks之间的损失来对齐$\mathbf{t}$:
1 | landmark_loss2 = lossfunc.l2_distance(trans_landmarks2d[:, :len_landmark, :2], landmark[:, :len_landmark]) |
然后其实就结束了,虹膜检测和人脸分割虽然在IMAvatar的预处理里实装了,但在IMAvatar和PointAvatar里其实没有用到。总之最后的数据集结构就是:
1 | subject |
其中code.json里记录着DECA对每一帧的估计结果,flame_params.json是通过optimize.py以后进一步处理后的参数,deca目录下实际上是空的,大概是中间结果给删了。
Discussion
这就是这两个工作的预处理管线了,我想在这儿再提及一下这两个管线里都用到的关键点损失(keypoints error):
我们已经知道了,$K\left( \theta ,\psi ,\beta ,t \right)$是从FLAME中“mapping”出来的关键点,然后$K_{\mathrm{target}}$是用一些预训练好的模型,不管是Mediapipe里的detector还是face_alignment库的landmark detectors。用这种loss来抽先验,然后进行优化是非常直接的想法,可能在之前人脸的一些领域这个loss已经被当成司空见惯的佐料了,优化的时候加点进去刷刷点。但我想说,这种思想非常的有用,有用到它直接开辟了3D生成的一种新的方法:从预训练的diffusion中抽先验。
只不过这一子领域实在是发展太快了,他们现在大概也不是只用这个简单的loss了。
我推测SDS loss并不是噪声的L1或L2范数的原因,是因为在diffusion model中的噪声信号的另一个诠释就是其分布的对数概率密度函数的梯度。这个梯度的方向具有一定的指导意义,所以直接相减取noise residual就好了。不过这里说这个太跑题了。
所以为什么要干巴巴的写出这么一篇blog呢,因为有一天晚上下班回家,我发现GAMES Webinar有个直播,最后里面有段话:
“所以我觉得对于刚入门的同学来说,可能一些知识上的积累,要远比于快速的卷一两篇paper可能更重要一些吧。所以当你有了这些经验和知识以后,可能现阶段你卷不过那些更senior的老师同学,但未来某一天你可能有一些新的任务新的工具出来之后,你就可以快速的应用过去。”
这大概就是全部了。
End
“若是从未启程的故事,能够有结局的话,残留枯枝也会绽放吧。”

