
“暮雨沾轻裘,声色随性收。弦歌久,续盏酬,结客少年游;落花踏尽信马走,风盈袖。天地旋袂划星斗,白月隐辰宿。“
EG3D是一篇nVidia参与的基于单视角的2D图片,生成3D形状的工作,其生成的结果兼具几何和视角上的一致性。EG3D整个工作其实由许多部分和细节组成,文中由于篇幅,以及“科技论文”写作时的要求,对于大量的细节基本就是一带而过,这就导致理解这篇时会非常困难。为了透彻的理解这篇工作,首先需要了解NeRF,GAN,然后进一步要了解StyleGAN系列。因为以及其中用到的一些技术严格来讲横跨StyleGAN,StyleGAN2,StyleGAN3。
除了纸面的“contributions”,EG3D的代码库也已经很有学习价值了,其代码给出了一个非常先进的深度学习项目管线。后面许多的工作都沿用了他们代码的pipeline,例如Next3D,panic3D,pix2pix3D。
“工欲善其事,必先利其器。”
这篇blog会先大概从论文中的整个流程切入,然后直接解读一下代码。适合对3D生成感兴趣以及跟我一样不是很熟悉Python(或者说是“lack of skill”)的读者进行阅读。对于文中涉及到的StyleGAN系列知识,blog中不会过度的展开,感兴趣的可以自行查阅:
StyleGAN -> A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGAN2 -> Analyzing and Improving the Image Quality of StyleGAN
StyleGAN3 -> Alias-Free Generative Adversarial Networks
实际上EG3D的作者后面有Tero Karras的署名。我在炼丹里最喜欢的工作基本都是他的力作,例如PGGAN,StyleGAN3。其中后者的强度基本是给炼丹者一点小小的数字信号处理震撼,以及这一篇:Elucidating the Design Space of Diffusion-Based Generative Models,一个恐怖的diffusion实验报告,基本把diffusion里的各个部件都“测量”了一遍,然后给出了很多实践意义上的指导。
Overview
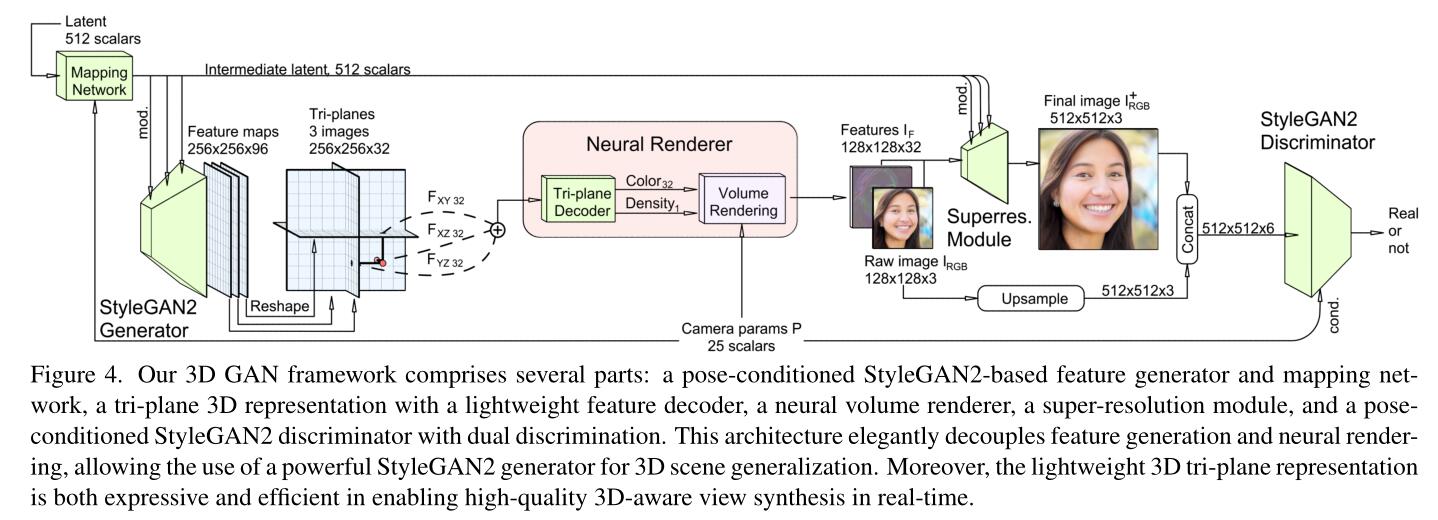
如图所示,EG3D描述了这么一件事:
- 给出一个服从告诉分布的Latent code $\mathbf{z}$,送进一个Mapping Network(在StyleGAN系列中,这一般是8层MLP,用来给编码用的隐空间“塑形”),和一个相机位姿$\mathbf{p}$一起构造一个联合分布。[Tips: 粗糙的阅读原文后,我们可以知道EG3D实验的重头戏是在FFHQ和AFHQv2 Cats两个images dataset,本质上就是高清的人脸和猫猫脸数据集。所以其本身是没有拍摄时相机的位姿$\mathbf{p}$这个label的,这个label其实是他们用其他工作的相机位姿估计器估计的,后面再玩GAN inversion时我们会再次提到。]
- Mapping后的结果,通过mod.(意为modulate,是StyleGAN中的一个称呼,其实就是用一种特殊的方式输入进NN里)送进StyleGAN的生成器。
- 在GAN的常规剧情下,最后会用一个输入通道为$C_i$,输出通道为3的卷积层将$C_i$个特征图映回RGB空间。但这里好像是取了其中间结果,即那$C_i$个特征图(图中的256×256×96)。
- 然后这个特征图被一个比较稀奇的“Tri-planes representation”给操作了一下,得到$F_{XY},F_{XZ},F_{YZ}$,然后这三个东西逐元素相加,被一个decoder解码,得到Color和Density的表示,之后在$\mathbf{P}$的条件下,进行体渲染。这个过程即“Neural Renderer”。
- 注意Color的维度是32,而Density的维度是1。所以其实它是render了32张图,每个图用相同的geometry。然后这个128×128×32的$I_F$,不知道怎么的,就可以计算出128×128×3的$I_{RGB}$,然后由给它超分了一下,得到高分辨率的图像。
- 由于超分是个复杂的非线性操作,为了保证前后的图片细节的一致性。小分辨率的图会被上采样,然后这两个东西拼到一起来让判别器去分类。这被称为“dual discrimination”。
- 于是整个管线就可以反向传播了。
上述概括是直接从图里得到了,具体实现还是得阅读EG3D。
Code Analysis
整个项目结构是很干净的:
1 | . |
这里./dnnlib下是一些常用的结构和类的实现,./gui_utils和./viz跟可视化和最后交互式的UI界面的呈现有关。./networks用于存放ckpt,./metrics是跟指标,质量评估相关的实现。./torch_utils里是从StyleGAN3中迁移过来的CUDA/C++扩展,./training里是具体的网络结构,损失函数,以及体渲染相关的实现。
我们一眼就能看出从train.py切入:
1 | if __name__ == "__main__": |
config setting
@click取代argsparse
我们注意到整个项目里,没有类似config的字眼,文件,文件夹出现,也没有熟悉的argparse和parser。这是因为EG3D用click来自定义了命令行参数。在train.py中的main()函数定义前:
1 |
|
用@click.command()来装饰main()函数,使用@click.option来定义各种选项。命令行中的关键字作为不定参数**kwargs输入进main():
1 |
|
我们发现了一个被频繁使用的类:EasyDict,它被定义于./dnnlib/util.py中。其中dnnlib大概是deep neural network libraries之意:
1 | class EasyDict(dict): |
这个类继承自Python原有的字典,重写了__getattr__, __setattr__, __delattr__三个魔法方法,从而允许我们可以直接用'dict.keys'的方式来获取其键值对,而不必写成'dict['keys]',从而增加代码可读性(我应该在之前自己的一个项目里用这个的)。
所以实际上main()函数的initialize config阶段,是先将输入的**kwargs转换为EasyDict,然后定义一个主要的config,即c。接着在c中嵌套子字典,如生成器,判别器的参数G_kwargs, D_kwargs。以及他们的优化器的属性G_opt_kwargs, D_opt_kwargs等等。
接着会继续在c里注册参数:
1 | # Training set. |
动态导入
注意,我们发现,一些重要的配置,例如生成器和判别器的设置。我们好像仅仅只是写入了一堆字符串,并没有实例化什么类。实际上整个管线用./dnnlib/util.py中的如下的逻辑打包了动态导入(dynamic import)的过程:
1 | def get_module_from_obj_name(obj_name: str) -> Tuple[types.ModuleType, str]: |
我们跟随训练集初始化的代码来看一下上述四个函数是怎么做到从字符串里“召唤”实例的:
1 | c.training_set_kwargs, dataset_name = init_dataset_kwargs(data=opts.data) |
在main()中注册参数的代码中,有一个init_dataset_kwargs()函数:
1 | def init_dataset_kwargs(data): |
可以看看到init_dataset_kwargs()先整理出了一个数据集的参数,形式为字典。然后construct_class_by_name()接收字典解包(**)后的键值对。同时注意到class_name这个键的值为'training.dataset.ImageFolderDataset',现在输入的键值对继续被call_func_by_name()调用。
在call_func_by_name()中,'training.dataset.ImageFolderDataset'被输入进函数get_obj_by_name()。在get_obj_by_name()中,'training.dataset.ImageFolderDataset'才被真正输入到一个实际起效的函数:get_module_from_obj_name()。
简而言之,在get_module_from_obj_name()中,输入的字符串会先按照’.’分割为一个个"name_pairs",代表module_name和local_obj_name。例如'training.dataset.ImageFolderDataset'将会导致name_pairs包含:
1 | name_pairs[0]: ("training.dataset", "ImageFolderDataset") |
这些备选,之后函数尝试每个备选,以找到模块和对象名称正确的组合,通过importlib.import_module()来动态导入其他的.py文件(或者说是模块。)
1 | try: |
如果找到了,就返回此时的module和local_obj_name。
所以我们现在回到了:
1 | def get_obj_by_name(name: str) -> Any: |
在'training.dataset.ImageFolderDataset'这个例子下,此时的module就是'training.dataset'指代的python模块,obj_name就是'ImageFolderDataset'这个字符串。然后会通过get_obj_from_module(),来从'training.dataset'这个模块中,找到'ImageFolderDataset'这个类对象,最后返回。
所以call_func_by_name()中的func_obj = get_obj_by_name(func_name),其返回值就是一个Python函数,它一般是可调用的。所以最后的call_func_by_name()会返回func_obj(*args, **kwargs),于是就实现了动态导入并实例化我们需要的类的过程。在刚才的例子里:
1 | dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset', path=data, use_labels=True, max_size=None, xflip=False) |
实际上就等价于:
1 | dataset_obj = training.dataset.ImageFolderDataset(path=data, |
这种方式就可以避免在一些相关的.py文件开头,手动import大量模块。
launch training
DP与DDP的入门
按照常规的深度学习管线,配置好实验参数以后,就要开始定义一下输出目录,打log,以及写迭代用的循环体。同时由于这个项目所处理的模型,计算强度都很大,所以需要单机多卡的帮助。在main()函数的最后,我们进入了launch_training():
1 | # Launch. |
在launch_training()的第一行,有一个可能由于历史原因没有被移除的logger。这个logger在这里并不会有什么实际意义,接下来subprocess_fn()里的logger才是真正有意义的。
launch_training()里接下来会定义输出目录:
1 | def launch_training(c, desc, outdir, dry_run): |
输入中的outdir,是之前用@click.command()这种方式传入的保存路径,如./training_runs。假设./training_runs路径下有:
1 | ./training_runs |
那么第一个列表推导式是为了筛出outdir目录中所有文件和子目录中那些可以构成子目录的(即00001-desc1,00002-desc2,等)。然后用正则表达式^\d+匹配其中的数字,这些数字序列被.group()方法捕获,转换成整型,最后计算出此时应创建的实验log的序号(在之前的例子里为6)。最后与输入的desc拼到一起,得到run_dir。
然后这次训练的一般选项会记录进一个.json里,最后开始正式启动训练进程:
1 | # Print options. |
真正执行时,EG3D采用了分布式训练。由于本科的时候没什么机会使用多卡(我只有一次在2×2080ti上用nn.DataParallel()的经验,但这个方式现在已经不推荐了。),所以我其实不是很熟悉多卡时的pipeline。这次正好学习一下。当GPU数量大于1时,程序会以spawn方法来启动多进程,具体来说,是通过torch.multiprocessing.spawn()启动num_gpus个子进程。每个子进程都会执行subprocess_fn()函数,同时传递相同的参数c和temp_dir。temp_dir是一个系统临时开的位置,用于存储不同子进程之间的通信信息。注意,如果我们只有一张卡,那么会直接调用subprocess_fn(),rank记为0。在多卡时,args里并没有显式输入rank,此时的rank由程序自动分配,为0~c.num_gpus-1。
1 | def subprocess_fn(rank, c, temp_dir): |
在subprocess_fn()开头,我们再次看到了Logger。这个Logger的实现比我之前写的要高明的多:
1 | class Logger(object): |
Logger会直接将标准输出流和标准错误流重定向到自身,这样,如果Logger指定了一个可以写入的file。那么在write()的时候,文本就会同时写入这个file以及控制台。所以每个子进程都会有各自独立的log.txt。也就是说,任何print()的东西都会被记录下来。
然后会有这么几行代码来初始化多进程的环境:
1 | # Init torch.distributed. |
怎么说呢,这几行代码基本就是多卡通信的API调用。由于掌握其API背后的原理和实现实在是超出了我能力范围,所以此处就不作解析了,权当咒语“咏唱”来看待吧。
但即使我们不熟悉不同GPU通信的底层实现,我们还是可以建立一些“high level”的认识:
当我们在讨论并行计算时,有“模型并行”和“数据并行”两种方式。前者是说模型特别大,需要将模型拆分到多个GPU里。古早时期的AlexNet和现在的大语言模型的训练就是这个思路,但这于我而言也是“beyond reach”的存在。
所以我们更多的还是考虑数据并行,也就是说将数据分发给多个GPU,每个GPU保存模型的一个副本。
坊间传闻,这种数据并行的方案有两种。DP(DataParallel)和DDP(DistributedDataParallel),DP只允许一个进程,不同GPU的梯度汇总到GPU0(即rank=0的那块设备),然后进行反向传播来更新参数,再将参数广播到不同的GPU里。这会导致负载不均衡,因为GPU0的使用率和内存消耗会更高。
以及,这种实现实际是单进程多线程的训练,会受到Python中的全局解释锁(GIL)的影响。这个机制导致Python解释器一次只会执行一个线程。虽然GPU上实际进行前向和反向传播是底层库(如CUDA库)驱动的,不会受GIL的影响。但在汇总梯度和更新权重时,由于GIL的存在,一次只有一个线程可以工作,也就是其余GPU的线程会被阻塞,从而影响性能。(实际上GIL的存在其实导致了多线程的dataloader直接失效,我们熟悉的num_worker机制其实是多进程。)
所以在DDP中,程序开辟了不同的进程,每个进程分配独立的资源和设置(如优化器)。在各进程的梯度计算完成后,各进程将梯度汇总平均,然后再由GPU0广播到每个进程中。由于初始时刻也会将模型参数都广播一遍,所以各进程中的模型参数始终一样。由于每个进程相当于独立的程序,包含独立的解释器和全局解释锁,于是就可以绕过GIL的限制。这样就可以让负载均衡,同时并行度更高。
在PyTorch中,DP可以通过修改几行代码为
nn.DataParallel()来实现。DDP就略微复杂了,PyTorch提供了torch.distributed.launch()和torch.multiprocessing.spawn()两种方式来启动。EG3D使用的是后者,也是PyTorch文档推荐的启动方法。
准备工作都具备了,下面就可以开始进入训练的循环体了:
1 | training_loop.training_loop(rank=rank, **c) |
(注意,这里输入的是解包后的c,这样在training_loop()的定义里就可以直接写出有哪些参数了,以增加可读性。)
1 | def training_loop( |
training loop
training_loop()的实现,集成了很多技术。
1 | # Initialize. |
最开始的几行对torch进行了一些初始化,不是我们关心的重点。
1 | # Load training set. |
没用过sampler?
在构造训练集时,这里其实构造了一个比较古怪的流数据。如果读者不是很清楚dataloader,sampler,dataset这些torch里构建好的机制,可以参考这篇blog。事情的古怪之处是,这个用construct_class_by_name构造的类,实际上是一个Map式数据集,然后这个Map数据集用一种类似Iterable的方式来__getitem__,为了防止多进程时,不同进程读取同一张图片以及多个进程计算了相同图片的梯度这种矛盾,它实现了一个无限循环的采样器:
1 | class InfiniteSampler(torch.utils.data.Sampler): |
然后将这个sampler和刚才构造的Map式数据集,用torch的dataloader封装一次,取其迭代器。这样每次next()就可以得到图片和其对应的”labels”,这里的”labels”就是估计出的位姿矩阵。“labels”本身是一个1×25的向量,其前16个元素对应一个4×4的相机外参;后9个元素对应一个3×3个相机内参。如果不熟悉这里的读者可以参考这篇NeRF的blog,里面给出了相关推导。
1 | # Construct networks. |
然后接下来就开始构造网络本身了,在EG3D中,这里具体构造的是哪个网络由train.py的267~268行给出:
1 | c.G_kwargs.class_name = 'training.triplane.TriPlaneGenerator' |
稍后我们具体分析其计算过程时,要去找对应的类实现。
“持久化”的用处
然后是几行非常巧妙的代码:
1 | # Resume from existing pickle. |
可能有人会疑惑:“这不就是读了个pkl么?有什么巧妙的。”,实际上巧妙的原因并不是因为读取保存格式为.pkl的checkpoints。是因为在EG3D的代码库里,每一个神经网络(继承自torch.nn.Module)的任何类,实现时都被这么一个装饰器装饰了:
1 |
|
这个装饰器函数意为“持久化”,其定义是:
1 | def persistent_class(orig_class): |
这个装饰器将会巧妙的利用Python中的pickle模块,完成一个很有意思的功能。我们先关注这个装饰器的实现,它会传入一个类,比如一个定义好的神经网络类,然后返回一个Decorator类。这个Decorator类继承自原来的类,并且有一些新的属性和方法,特别是其中的__reduce__,这是Python专门给pickle模块预留的一个魔法方法,用来规定反序列化时的规则。是Python用来给用户提供一个复原相对复杂的object的方式。如__reduce__所示,其最后会返回一个tuple,元组的第一位是“_reconstruct_persistent_obj”,代表__reduce__会使用这种方式来复原这个object。第二位是所需要的参数,在这里是meta。
那么这个装饰器具体做了什么呢?我们从头来看。当我们传入一个类orig_class时:
1 | orig_module = sys.modules[orig_class.__module__] |
orig_class.__module__是这个类所在模块的字符串,sys.modules是Python基础库提供的一个字典,其键为模块名,值为模块对象。所以orig_module被赋值为orig_class所在的模块,然后_module_to_src()函数会利用inspect库返回此时这个模块的源代码:
1 | def _module_to_src(module): |
这个源代码orig_module_src最后会写入Decorator类里,作为类内成员,最后在调用__reduce__时用在meta这个字典里。所以当我们反序列化时,会使用这个自定义的__reduce__方法,调用_reconstruct_persistent_obj(meta)。重建的这个函数为:
1 | def _reconstruct_persistent_obj(meta): |
这里面的关键在于_src_to_module()函数,其从此时模块的源代码中复原这个模块:
1 | def _src_to_module(src): |
此时会将一个不可能重复的module_name强制转换为ModuleType类型的module,作为sys.module的键,最后用exec()执行给定的源代码,将其加载到新创建的模块module里,最后返回module。
得到了此时的module以后,meta里还存放着需要还原的类的class_name,于是通过查询module.__dict__即可复原这个orig_class。
我们跳到training_loop.py中的第394行~409行,我们可以发现程序逻辑上会将training_set_kwargs和[('G', G), ('D', D), ('G_ema', G_ema), ('augment_pipe', augment_pipe)]都dump进.pkl文件中。所以再读取这个.pkl时,就会按照写入这个.pkl时的各种类的实现,来复原此时的G,D等对象。
所以,假设此时我们正在开发一个炼丹项目,我们按照上述逻辑运行,得到了一个.pkl的存根。过了几天,我们可能修改了这个项目里,例如GAN中生成器的结构,不管是输入参数还是网络结构本身。此时我们读入这个pkl,往往会得到matching error的报错。但由于刚才的Decorator类,其类中记录了之前这个网络的所有定义(包括输入参数,源代码等),新的__reduce__所返回的tuple,是按照之前Decorator继承来的父类(即原来的模型)来的,所以这就可以让我们在不修改当前代码的情况下,直接读取在开发过程中版本不相同的checkpoints。
构造循环体
然后的代码负责记录了一下此时的网络结构,打印进log里:
1 | # Print network summary tables. |
这里用到的misc中的print_module_summary()是一个自行编写的函数,其中用到了torch中的hook机制来捕获各个子模块的参数量和输入输出形状等信息,其实就是Kera里model.summary()的平替。
实际上,后来一个非官方的包torchsummary也可以做到这一点了。
然后又是设置一个数据增强的管线:
1 | # Setup augmentation. |
这个管线其实是来自于这篇论文,也是nVidia的工作,简单来说就是教我们如何给GAN做数据增强(想象一下,我们好像不能那么鲁莽的将一些augmentation推广到GAN的训练中,比如翻转,这会导致网络生成翻转后的图像)。所以这里就实现了一种自适应机制的augmentation。这里就不展开了。
一般来说,在一些别的任务里,我们一般会把aug放在dataset的实现里,例如在__getitem__里写一些分支判断。但在这里,如上面代码注释所示,这里的augment_pipe实际上也是一个继承自torch.nn.Module的,一旦调用它会自动运行forward方法。这个增强管线实际上会在loss类中的run_D()里被调用,然后大显神威。
然后下面的这段代码块会将此时模型的参数(不管是随机初始化的还是从resume里读进来的)都广播到各个进程中,保证参数最开始都一致。
1 | # Distribute across GPUs. |
然后接下来,是确定训练过程的一个settings。实际上是对训练GAN的一个封装。在我们刚接触GAN时,我们往往会实现这样的伪代码:
1 | for epoch in range(cfg.epochs): |
这样即可实现“交错”的训练生成器和判别器,然后有时候,由于训练判别器比训练生成器容易的多,所以可能我们会进一步在上面的代码里加个判断分支,例如每$k$个mini-batches再训练一次判别器。在EG3D的代码里,对其进行了更“厚实”的封装。
具体来说,在training_loop里,我们只会看见一个可迭代对象“phase”,以及“loss”的设置。loss一般是继承自基类Loss的StyleGAN2Loss,其有run_G,run_D,accumulate_gradients方法。在accumulate_gradients中实现了loss每一项的具体计算。而上一层级里的“phase”是来确定accumulate_gradients方法里计算哪些项的。例如对于生成器,我们计算G_main,根据此时的批次,我们考虑是否计算G_reg;对于判别器,我们考虑计算D_main,D_r1等。
我们先继续走完training_loop的流程,然后就能切洋葱切到EG3D的计算过程了。所以不要心急。如上文所示,我们会将训练生成器,判别器时的配置,都打包成一个字典,作为一个列表的元素。如果没有正则化(至于这个正则化具体是什么,我们先按下不表),那么phase里可能只会有Gboth,Dboth,也就是长度为2的列表。根据有没有正则化的设定,最多会有四个字典作为列表元素,即Gmain,Greg,Dmain,Dreg。
1 | # Setup training phases. |
然后,进入第260行的while True循环,就可以发现训练的核心部分:
1 | # Fetch training data. |
首先先砍瓜切菜从数据集里拿图片phase_real_img和相机位姿phase_real_c(这里的c既可以理解为condition)。然后图像被缩放到[-1, 1],分成batch_gpu批(phase_real_c也是分成batch_gpu批)。这里batch_gpu就是一块gpu同时计算的数量,可以理解为单卡时的batchsize,只不过此时真正的batchsize一般会是batch_gpu * num_gpus个。这里用的是split()方法,也就是其被分成若干子批次的列表。
然后GAN采样用的随机变量all_gen_z和all_gen_c被创建,注意他们在创建时都需要满足最后的列表长度与phases一致,这样就可以后面用zip来合并了。例如假设all_gen_z是大小为[4 * 32, 100]的张量,其中4是phases的长度,32是batchsize。
然后all_gen_z的列表推导式的意思是:从all_gen_z.split(batch_size)中进行遍历,遍历得到的每个列表元素为大小为[32, 100]的张量。此时列表的长度为4,同时会对在这个返回列表里的张量元素再作split(batch_gpu),这样长度为4的列表的每个元素,就是长度也为batch_size/batch_gpu的子列表了。all_gen_c道理也是一样的。
然后我们发现phases(长度为4的列表)和all_gen_z,all_gen_c会一起遍历。phases遍历的元素phase自然是之前讨论的不同的训练阶段,如Gmain,Dreg。phase_gen_z和phase_gen_c会是刚才说的“列表元素中被切分的张量所形成的子列表”。所以在计算loss的时候,又嵌套了一层for循环+zip,作为loss计算时传入的参数。backward被封装进了loss.accumulate_gradients里了,所以接下来就是根据梯度来更新权重。
细心的话可以注意到第158行,160行,即生成器G和判别器D一开始就是requires_grad_(False)的,也就是说一开始就不会计算梯度。而只有到了第282行~285行要计算梯度时,才会把这个阶段对应的module(生成器或判别器)的梯度追踪标志打开,这样可以减少不必要的内存和显存开销。
在更新权重的那个部分,我们可以发现,和我们在DP与DDP部分说的一样,程序使用torch.distributed.all_reduce()来进行梯度同步,将平均后的梯度赋值给此进程下的模型参数(里的梯度)。
注意,赋值的那个for循环,更新的其实是param中的grad。param其实是一个列表生成式产生的列表,它并不是phase.module.parameters()的复制,而仅仅是一个引用。
while True的剩下的部分,执行的就是一些常规的操作了,基本就是更新一些训练时的计数器啊之类的:
1 | # Update G_ema. |
所以我们发现,所有的计算过程,比如用了哪些loss(约束),都打包进了loss.accumulate_gradients,下面我们来看一下这个accumulate_gradients()函数。
accumulate gradients
在解释这个部分之前,我们需要形式化的认识一些GAN的损失函数。因为EG3D其实是styleGAN2的直接应用,而styleGAN2已经是一个非常成熟的GAN了,里面有些事情我们可能并不知道。在loss.py中,我们可以看到这样的代码结构:
1 | class StyleGAN2Loss(Loss): |
我们可以看到各种loss,他们根据此时的phase以及相关的配置,进入不同的分支,然后计算完毕后backward计算梯度。而生成器和判别器的调用和逻辑被打包进了run_G和run_D,这是下一个层级需要分析的内容。
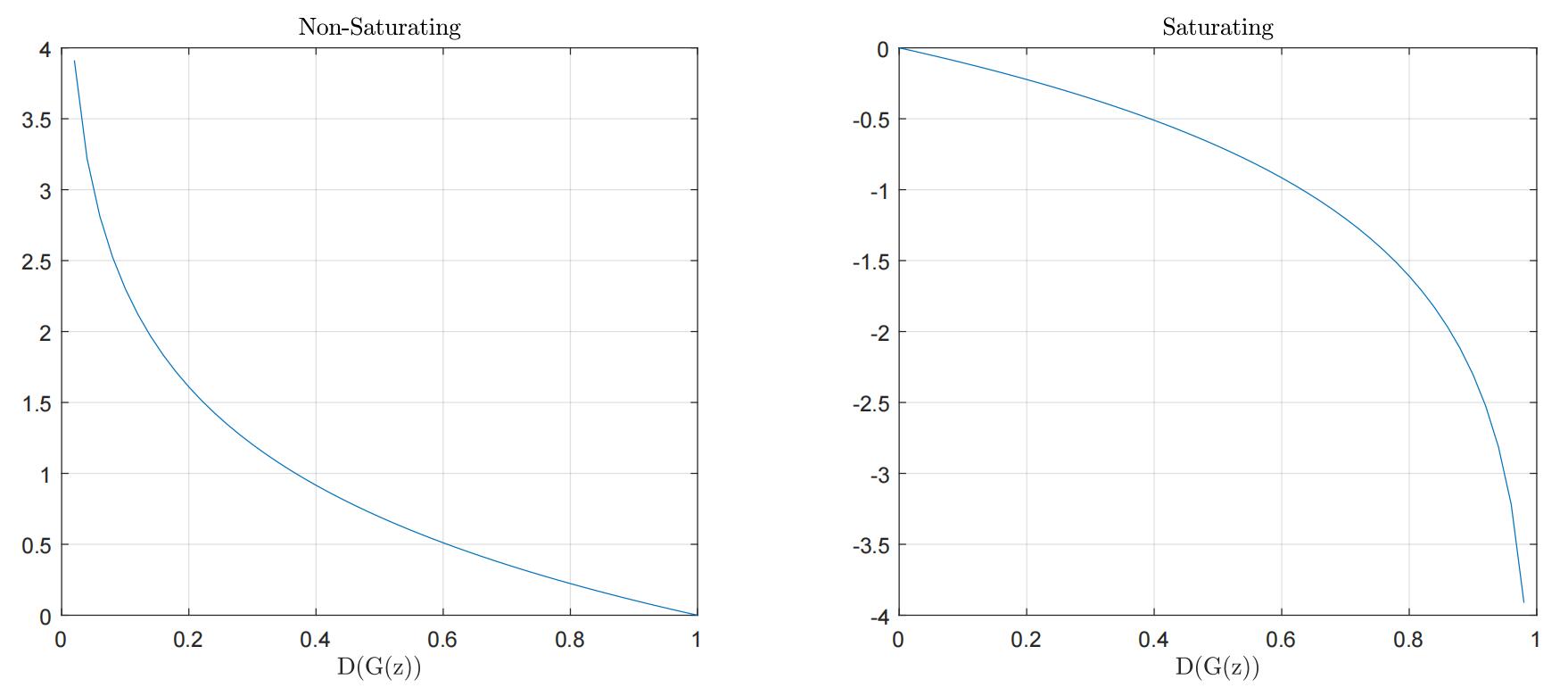
Non-saturating or saturating
首先,GAN最初的损失函数可以写作:
这个式子是将GAN的训练写成了一个极大极小的优化过程,但这样的写法不好引入后面要说的各种正则项。所以我们将其写成更一般的写法:
在原文中,可以会看到一种说法,叫作非饱和(non-saturating)的生成器损失,它其实指代的就是上式中的$L_G$,饱和(saturating)的写法是:
这两者的不同之处在于,由于判别器往往会比生成器训练的快,所以一开始生成器生成的图片,大概率都会被判别器判为假。所以这导致$D(G(z))$往往很接近0。考虑$\log \left( 1-x \right) $的导函数$-\frac{1}{1-x}$,会发现此时导数值近似于1。同时注意到,如果$x$如果接近1,此时的导数值(的绝对值)会很大。
而朴素意义上,我们想要的是在训练早期,有一些大的梯度值;在训练后期,有一些小的梯度值。这种损失下刚好与我们的初衷相违背,尤其在$x$接近0时,导数值有上界。所以我们称这种损失为饱和损失。
而当非饱和时,此时关心的是$-\log x $,其导函数为寻常的$-\frac{1}{x}$,所以在初期,$x$接近0时,可以提供一些比较大的导数值,所以称其为非饱和;然后在末期,$x$接近1时,导数值会很小,符合我们的想法。
这样操作自然会导致梯度爆炸的隐患,所以在training_loop.py的295行,misc模块中的nan_to_num函数中实现了一次截断(clamp):
return torch.clamp(input.unsqueeze(0).nansum(0), min=neginf, max=posinf, out=out)
R1 regularization
还有一项技术是R1正则化,这个是2018年在Which Training Methods for GANs do actually Converge里系统讨论的。这个技术并不是那么好理解,我们这里就挑着说了。EG3D里用的R1正则化(其实也就是styleGAN2用的),是对判别器的在真实数据分布上的梯度进行惩罚:
有人可能会联想到机器学习中的L1,L2正则化,于是会疑问:“这里不是二范数吗?为什么叫R1?”,其实这里的1只是一个角标,在那篇论文原文里,R2指的是对判别器在生成数据分布上的梯度进行惩罚,所以和取几范数无关。
为了更好的理解这个正则化,我们需要在动力学视角下再审视一下GAN。我们知道,炼丹的核心是梯度下降:
其形式上,其实和一个离散化的动力系统是一样的,或者说是欧拉法解微分方程,$\theta$最终会在其参数空间里留下一条轨迹。在有些时候我们可能不会关心这个轨迹,但再GAN中,我们面临这样的极大极小的博弈,此时考察这个轨迹可以带给我们一些很好的认识。
对于GAN,我们认为其系统由两部分参数组成:$\theta=(\theta_G,\theta_D)$,所以此时GAN的更新就是下面的交替使用梯度下降的过程:
如果我们考虑一个,很简单的一维的GAN。具体来说,我们要拟合的样本分布,仅有一个样本点,即0。而生成器的参数为$\theta$(一个标量),判别器的参数为$\phi$(一个标量)。生成器不管输入什么,都只输出当前的$\theta$。而判别器采用一个最简单的线性决策的机制:$\phi \cdot x$。
这个玩具GAN的机制非常巧妙,基本符合了我们对GAN的一些想象:最开始的时候,生成器不知道要生成什么数字,判别器由于也没有经过训练,不知道0是真实样本,所以会对输入的数乘上$\phi$来作为输出。理想情况下,生成器会慢慢往0生成,然后由于0乘任何数都是0,最后判别器也无法区分所接收到的“0”是真实数据还是生成器生成的0。
由于这个GAN最终拟合的是一个只在$x=0$处有值的分布,这是一种奇异函数,常用于信号与系统学科中。又叫狄拉克函数,所以这个玩具GAN也叫Dirac-GAN。
所以在这个特别的GAN中,$L_D$和$L_G$可以写成更特殊的形式。由于真实样本只有0这个点,所以$L_D$的一项直接变成常数了。以及生成器的输出一直是$\theta$,所以也不需要写$z\sim p_{gen}$这样的采样了和令人头大的期望符号了:
注意这里的$\sigma(\cdot)$,这是我们熟悉的sigmoid函数,用来把值……放到0~1之间的。一般在写$D(x)$的时候都默认最后有一层softmax了,这里需要强调一下。
此时梯度交替下降的过程也可以约化为(考验高中求导):
所以$\theta=(0,0)$是这组系统最合理的解,或者说是博弈的平衡点。但遗憾的是,实践表明,朴素的GAN的训练过程做不到这一点,他们会一直转圈,很难收敛到$(0,0)$:
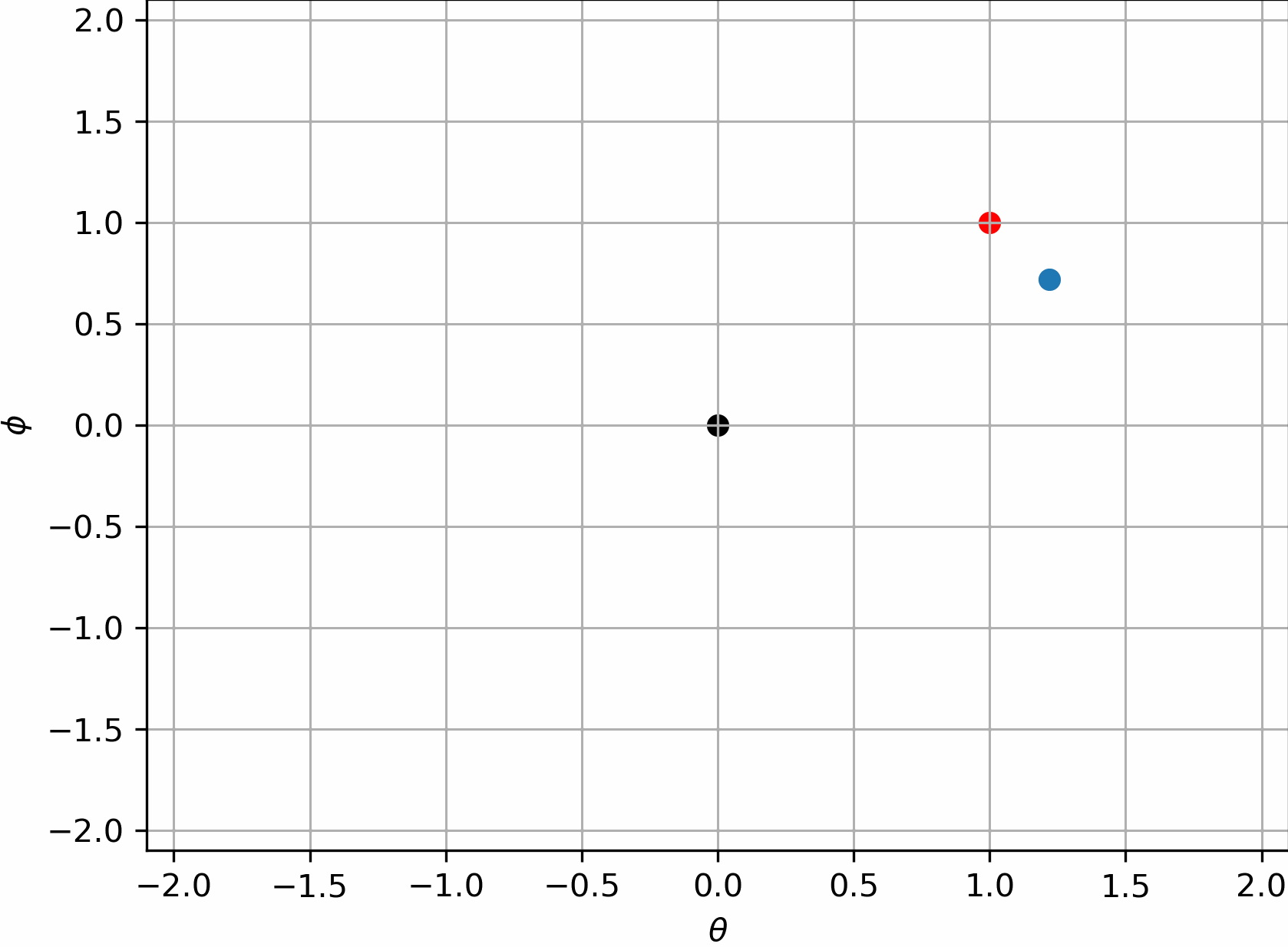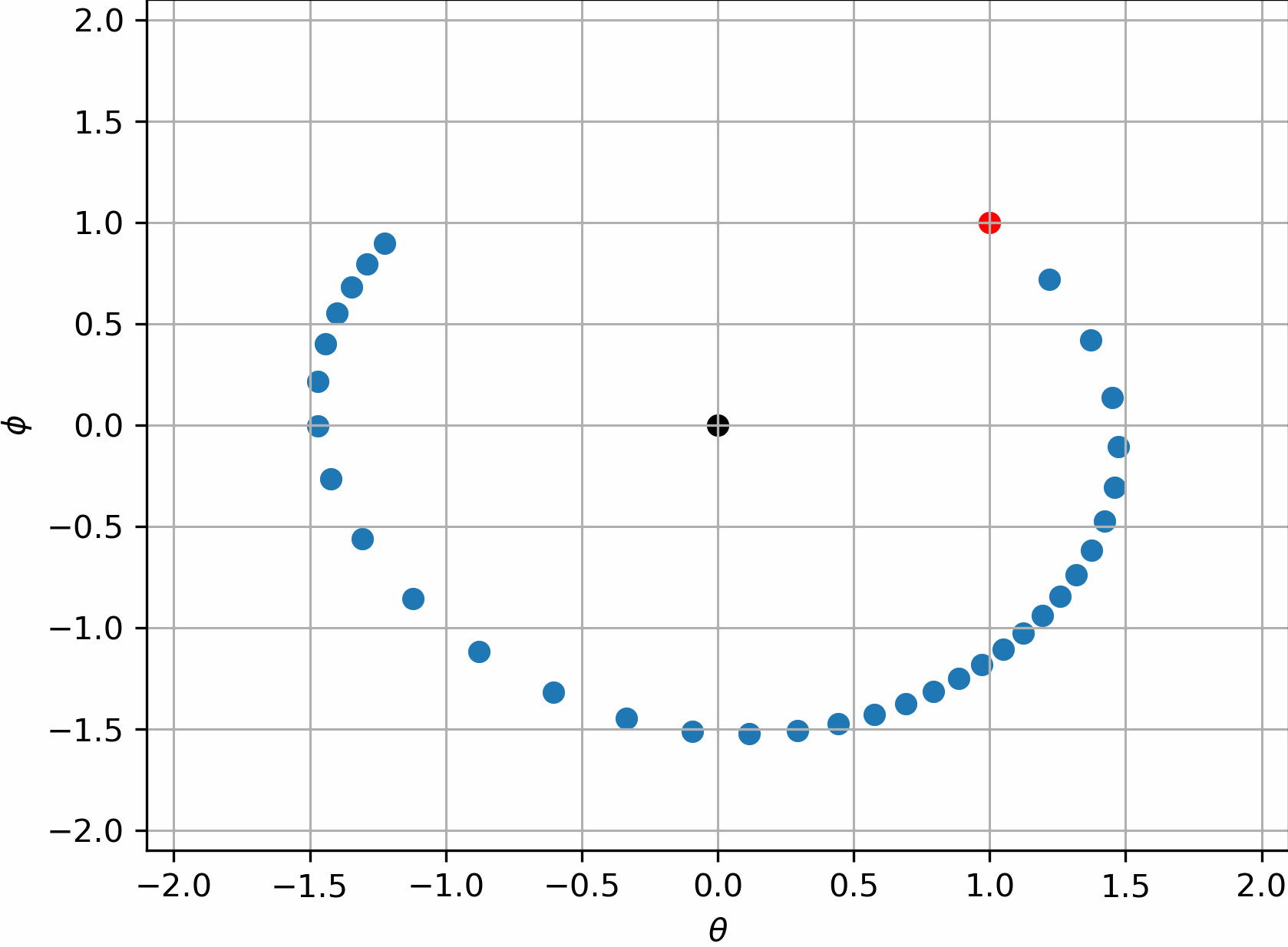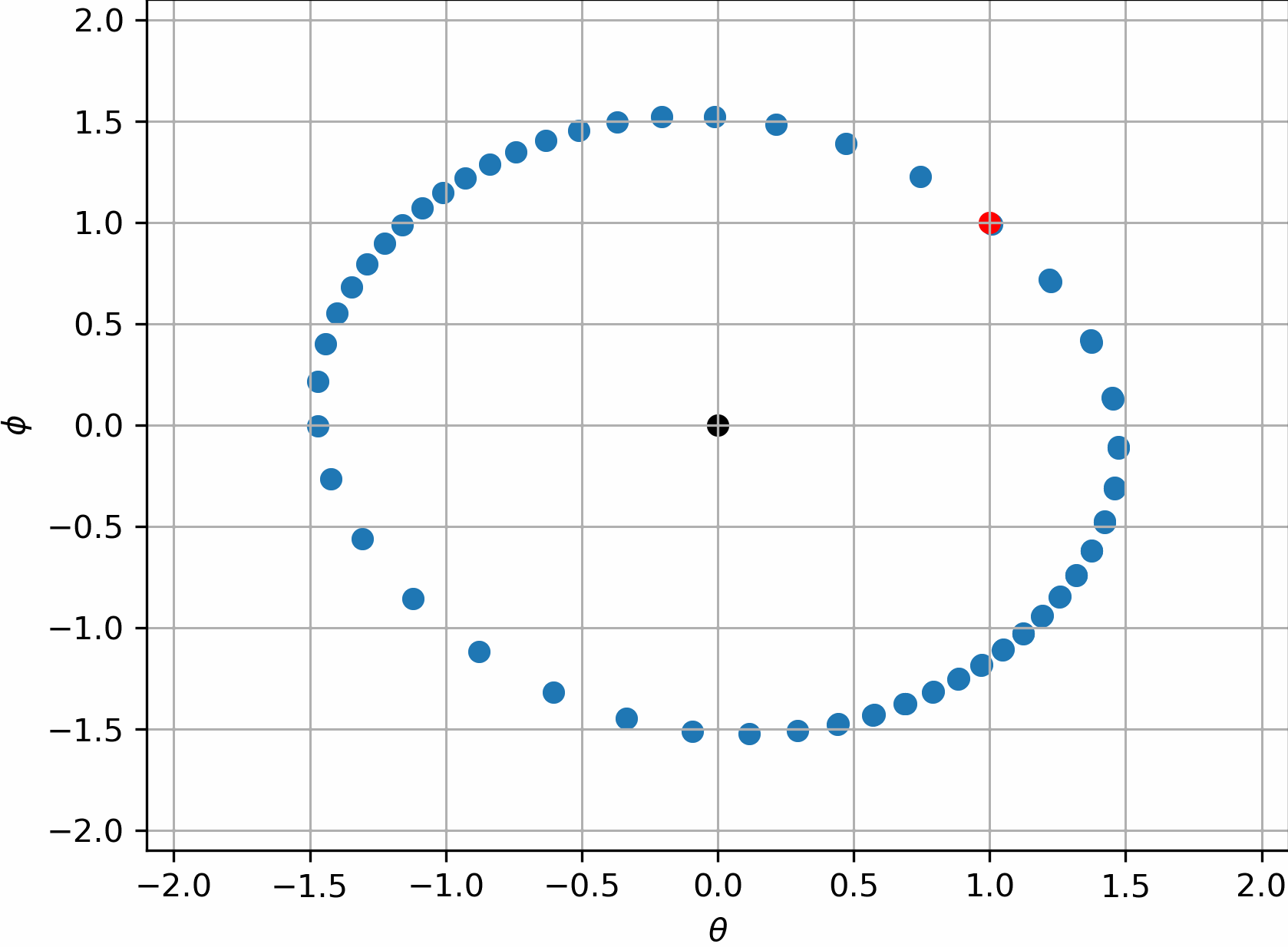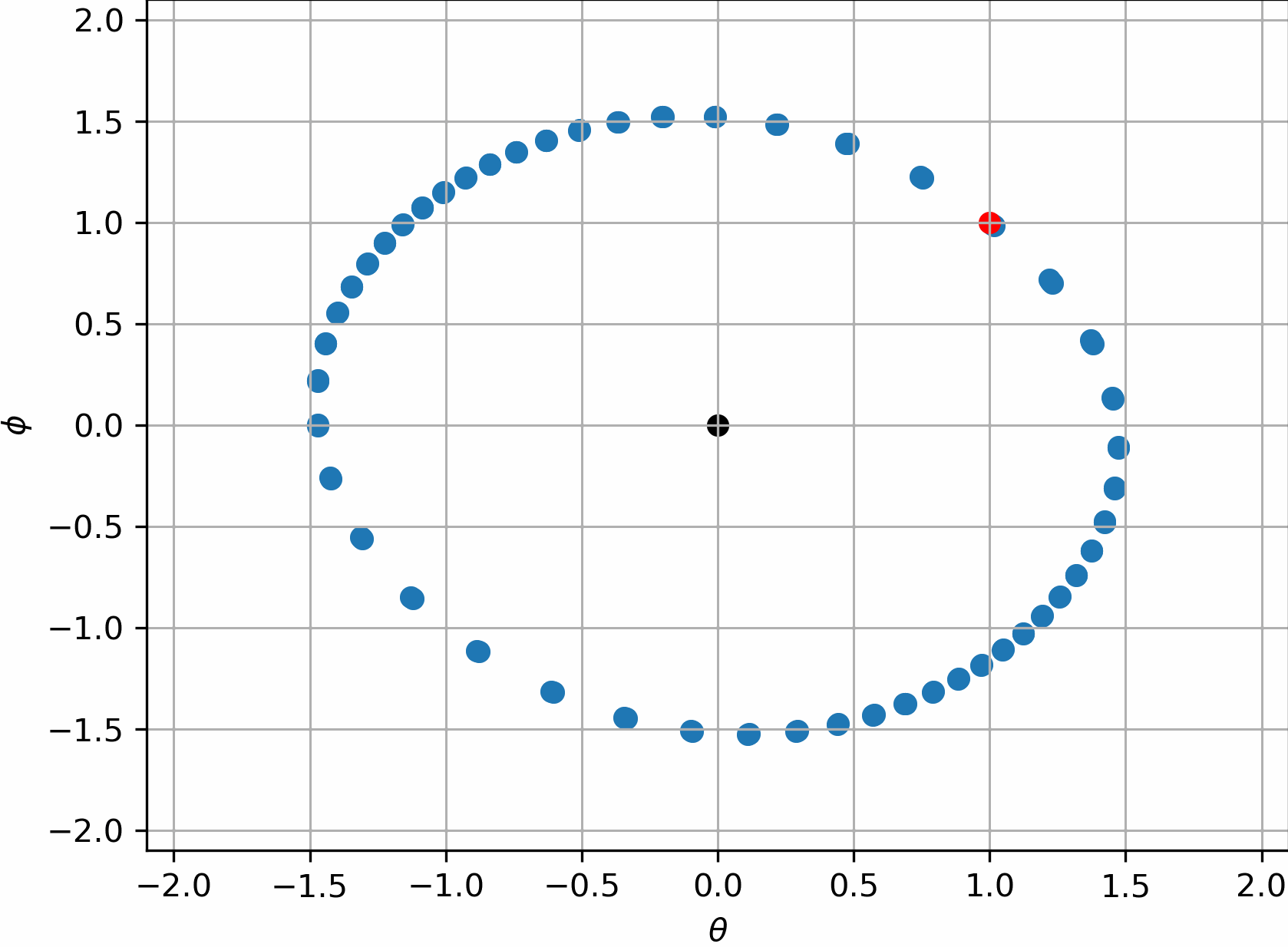
有趣的是,我们是可以说明它没法收敛的。假设在$(0,0)$附近的一个去心邻域内作泰勒展开,$\sigma(\cdot)$函数的泰勒级数为:
对这个邻域内的$\nabla _{\theta}L_G\left( \theta ,\phi \right) ,\nabla _{\phi}L_D\left( \theta ,\phi \right) $作泰勒展开,发现此时这个动态过程变为了:
整理上式,我们注意到了如下差分方程:
熟悉差分方程的解法的话,我们会知道这代表一个三角函数的周期解,即只要初值不是0,就会一直震荡下去。
但如果使用R1正则化,即此时的判别器损失为:
此时我们会发现:
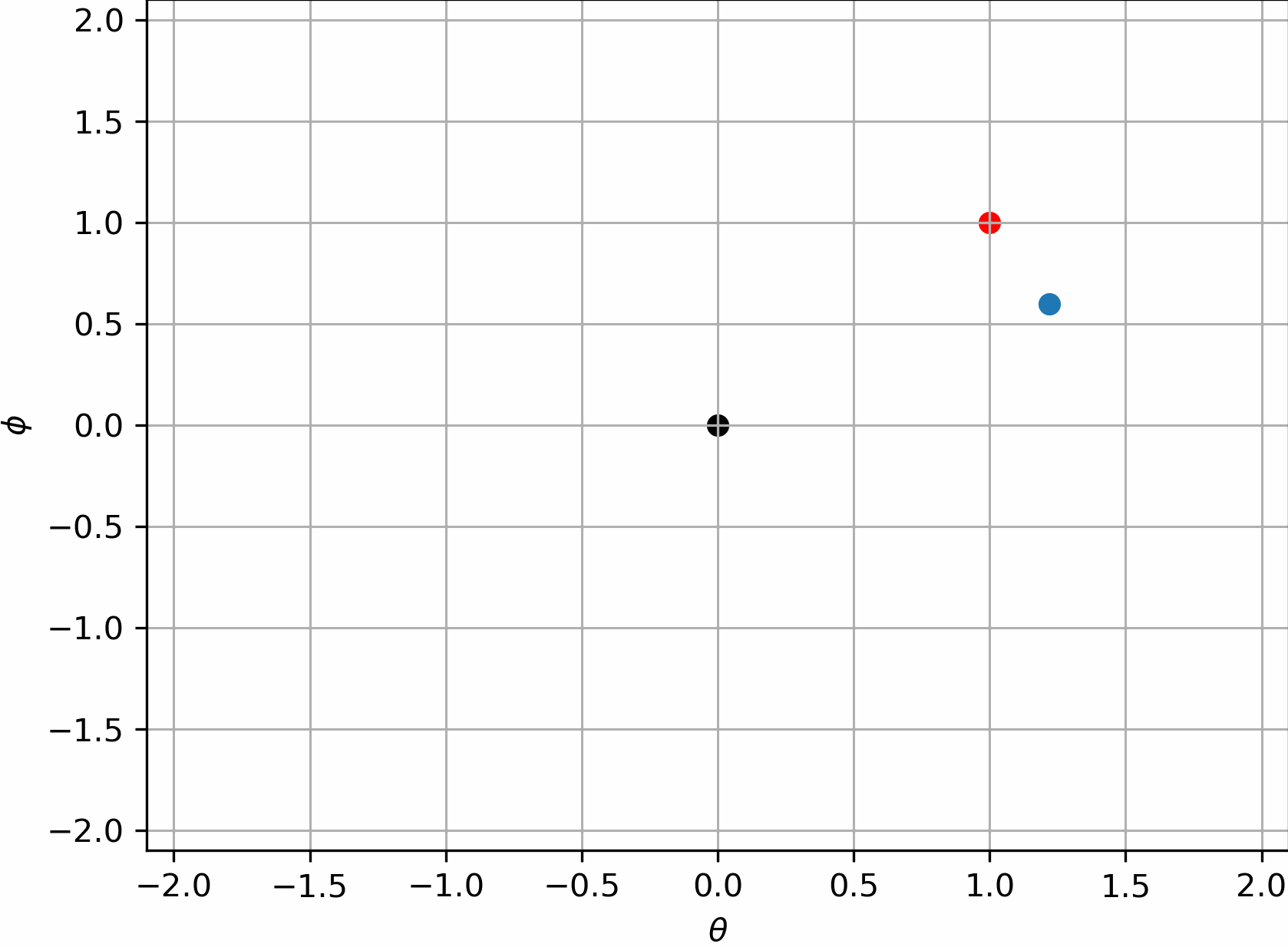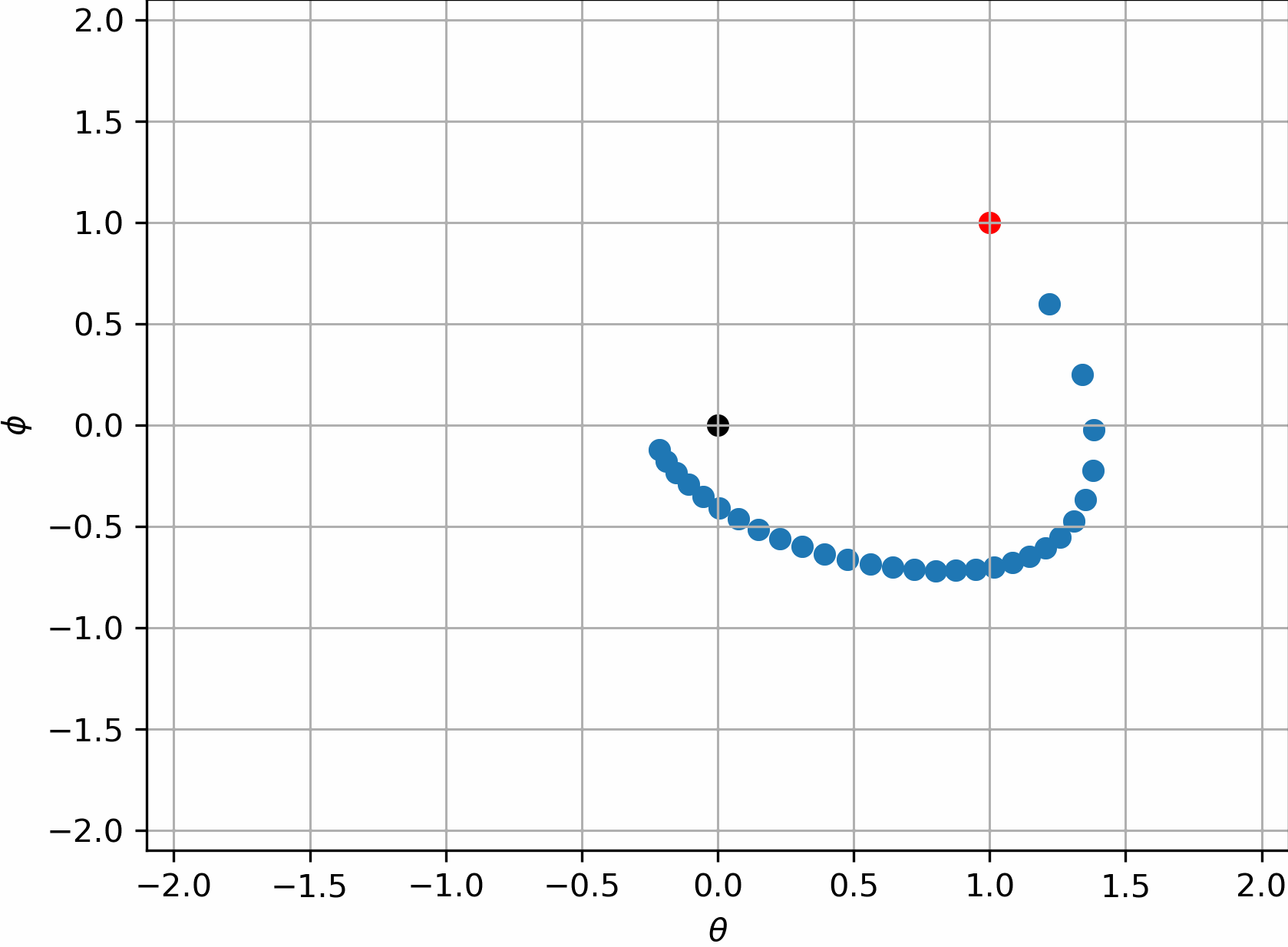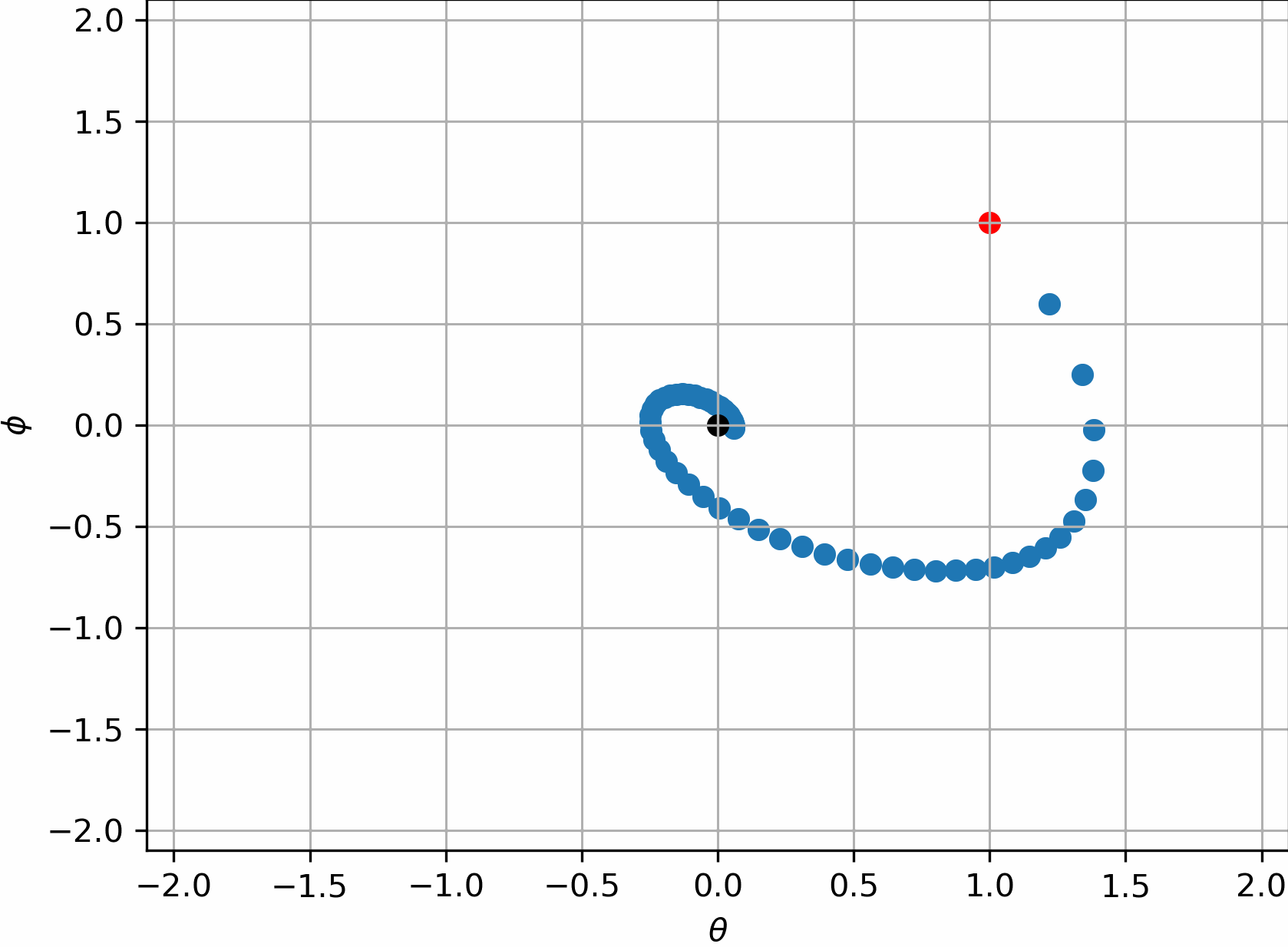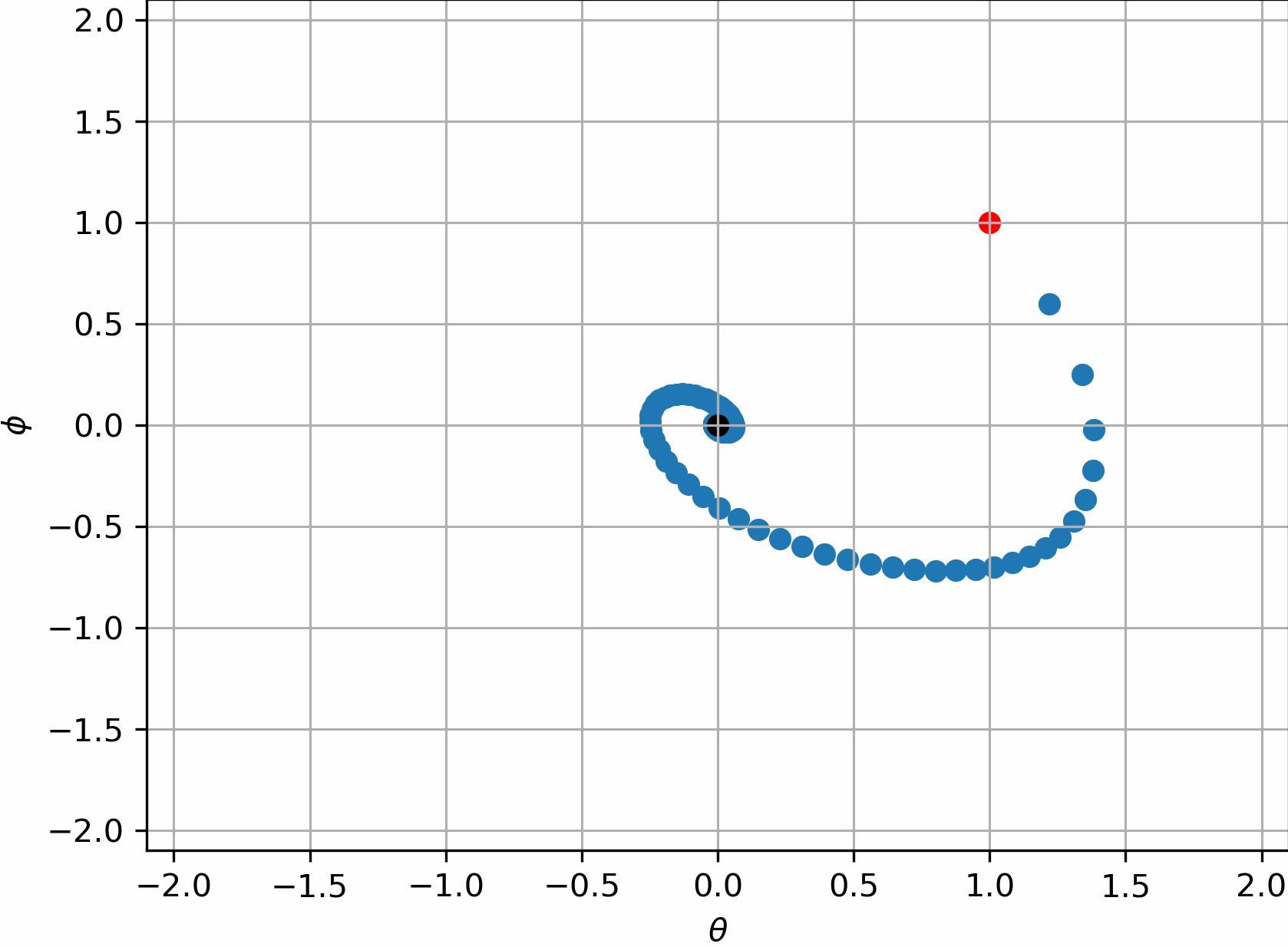
这个系统得以收敛了。是不是很神奇?
上述的玩具实验其实带来了许多丰富的观察,我们注意到,让判别器不要“更新的那么快”,会有助于GAN找到更合适的状态。这其实就是R1正则化的目的,因为判别器往往要比生成器“厉害”的多,在Dirac-GAN中,我们看到的那种圆形轨迹,实际上可以理解为生成器每次的“进步”,都完全被判别器“看破”了。于是就导致,每次判别器都在“割草”,每次生成器都在徒劳无功的“白给”。两边都没有任何进步。
同时,考虑在不施加正则化时,在$(0,0)$附近泰勒展开时,判别器和生成器之间类似三角函数般的周期性波动。其可以理解为是在稳定解附近的“震荡”,通过R1正则化,可以减少这种“震荡”。这同样是为什么现在成熟的GAN技术都必备权重滑动平均(EMA)的原因。
详细的收敛性证明可以参见18年那篇论文原文,这里就不讨论了。其实如何丝滑的训练GAN,在18~21年很受讨论。有着许许多多的GAN,但好像现在只有R1正则化成为了标配。可能是得以于其实践简单的原因。
Density regularization
这个正则项与上一个相比,可真是容易理解多了。以及这个正则项应该是第二版论文里才写进去的,第一版里应该是没有的。这个密度正则项就像一把刻刀,说的是如果我现在已经把整个体素场隐式表达好了,我希望相邻之间的体密度不要相差很大。这样可以保证后面几何形状的光滑和现实。
For each generated scene in the batch, we randomly sample points x in the volume and also
sample additional ‘perturbed’ points that are offset with a small amount Gaussian noise δx. Our density regularization loss is an L1 loss that minimizes the difference between
the estimated densities σ(x) and σ(x + δx).
这个其实是传统计算机视觉中常用的全变分,只不过当时是用来处理2D图片里的一些low-level任务,这里取其思想用来雕刻高保真的几何了。
但在loss.py的StyleGAN2Loss的实现里,还有两种可选的密度正则化方式monotonic-detach和monotonic-fixed,这两种无论选哪一个,原来的密度正则化都会执行。这两种的意思好像是多加一个沿z轴负半轴的方向令体密度单调递减的约束,但正文里也没提,issues里和各种平台也没人问,鉴定为是废案。
“EG3D”
经过前面的,前置知识以后,我们终于可以开始分析EG3D本身了。然而这里的细节也有好多,我们逢山开路吧。在拆开介绍各种细节之前,我们需要将最开始的那个pipeline分成三个部分,然后进行一些比较“high-level”的概括:
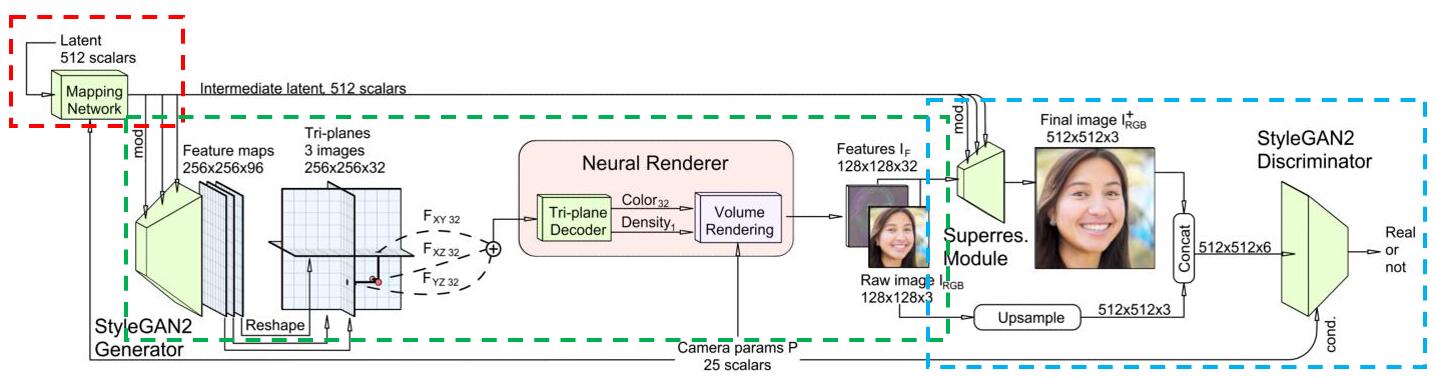
红色的部分是映射网络(Mapping Network),绿色的部分是生成器,蓝色的部分是判别器。下面我们按照这三个部分来展开。我们要意识到,这里的生成器虽然画的很复杂,但本质上还是生成一张2D图片。只不过和普通的2D GAN直接生成图片不同,这里是生成一个隐式的3D表示,然后按照体渲染的路子,表征出一张2D的图片。所以这会导致下文中的“生成器”有着不同的涵义,一个意思是绿色框所标记的,整个这个产生2D图片的部分;另一个是单纯的图中的那个StyleGAN2 Generator。
Mapping Network
我们从StyleGAN2Loss中的run_G入手:
1 | def run_G(self, z, c, swapping_prob, neural_rendering_resolution, update_emas=False): |
我们可以发现,就像StyleGAN2一样,我们都是先“mapping”然后再“synthesis”,但这里有两个分支,一个是swapping_prob,另一个是style_mixing_prob。
pose swapping regularization
swapping_prob是EG3D里的设置,它说的是“我们在训练时,要以一定的概率,将输入进Mapping Network的相机姿态替换成另一个随机的相机姿态。”
we randomly swap the conditioning pose in P with another random pose with 50% probability during training.
这个机制并不显然,我们应该意识到三个问题,①怎么替换的?②为什么要替换?③相机姿态为什么要输入进Mapping Network?
对于①,这两行代码给出了答案:
1 | c_swapped = torch.roll(c.clone(), 1, 0) |
c作为输入进来的一批相机位姿,在这里维度应该是[B, 25],所以roll的目的是将它在第一个维度上向右循环移动一位。这样就可以打乱相机位姿了,因为用随机数采样生成相机位姿,会比较复杂,比如应用拒绝采样,不如这样简单。然后下一行代码会从打乱后的c和原始的c中,进行选择,从而实现了以一定的概率来打乱姿态。
对于②和③,我们要从Mapping Network开始说起。Mapping Network本身只是一个8层MLP,它最初是在StyleGAN中引入的。这个操作的动机是为了在无监督的条件下解耦一些数据集里的特征,比如,在此之前的GAN,都是直接将生成的高斯噪声直接送入生成器,那本质上是要将一个高维的高斯分布揉成数据集需要的样子。但数据集的分布往往不可能那么的“对称”,所以在这个揉搓的过程中,许多的属性(attributes)/特征(features)会耦合在一起,但如果用一个映射网络对高斯分布进行映射,理论上就有了调整分布的机会。我们一般将Mapping Network输出的结果记作$\mathbf{w}$,映射后张成的空间记作$\mathcal{W}$(intermediate latent space)。
实际上StyleGAN的实验表明,确实只需要8层MLP这样的机制,加以反向传播,就可以自动学到解耦的特征。这可能是神经网络的一种偏好,这让我联想到物理里的“最小能量原理”,可能解耦的特征可以让这个系统变得更简单,于是优化就往这个方向优化了。
所以在EG3D的问题中,他们关注的是在生成高保真的3D人脸时,由于人在面对镜头时往往会下意识的微笑。这使得相机位姿和“微笑”这个属性,耦合在了一起。所以要将相机姿态也输入Mapping Network来解耦。
那么为什么,EG3D里又引入了一个奇怪的“替换成另一个相机姿态”的机制?我们需要来看一下相机位姿在不同部分的作用,在Mapping Network里,相机位姿是一种“condition”,它会导致生成器部分生成的3D表达的变化;在生成器部分,相机位姿只是单纯在对刚才那个3D表示作体渲染时的角度;在判别器部分,相机位姿也是一种“condition”,告诉判别器当前图片是从哪个角度拍摄的,作为判别器判别的依据。
所以如果输入给Mapping Network的相机位姿和输入给生成器作体渲染的位姿一直正确且一致,那么整个模型就会意识到一个省事的办法:只要保证生成的这个3D表示在特定位姿下渲染出来的是张人脸就好了。这会导致平凡解的产生,如原文在附录里所描述的:

原文将这种现象称为“广告牌(billboard)”,还是很生动形象的。
所以他们就采用将输入给Mapping Network的位姿进行随机打乱这样的措施,来实现一种正则化。在测试时,输入给Mapping Network的位姿其实是固定的,然后通过改变体渲染时的位姿,来得到一个比较有一致性的效果。因为位姿多少都会影响输出的$\mathbf{w}$里的一些除去位姿以外的属性,比如背景。
style mixing regularization
这一个风格混合的正则化来自于StyleGAN,实际上Mapping Network计算得到的$\mathbf{w}$,并不是一口气就输入进后面的网络的。出于特征解耦的目的,以及在深度神经网络中“浅层一般是结构(低频)信息,深层都是细节(高频)信息”的原教旨主义,$\mathbf{w}$会被切分成若干块,每一块送进不同层级的Synthesis block。这在代码中的体现是:
1 | def forward(self, ws, **block_kwargs): |
所以所谓style mixing,就是为了让$\mathbf{w}$不同维度之间尽可能解耦,“切断”他们的相关性。这个一个机制就是说,对于一个高斯噪声$z_1$计算出的$\mathbf{w}_1$,再生成一个$z_2$对应的$\mathbf{w}_2$,然后将$\mathbf{w}_1$和$\mathbf{w}_2$作交叉。这样,就隐式的给模型创造了一个“$\mathbf{w}$的各个维度越解耦越好生成”的偏置。
Truncation trick
在作推理时,当我们运行Mapping Network时,传参里会带一个--trunc=0.7。这是一个在StyleGAN最后被提及的一个小巧的trick。它的基本思想是考虑到数据集分布不均衡,有些采样密度比较低的区域生成器可能学习的不是那么好。为了提高生成图像的平均质量,在采样时考虑$\mathcal{W}$空间里分布的质心$\mathbf{\bar{w}}$,然后对采样一个$z$,计算出的$\mathbf{w}$,线性插值一下:
这里的$\psi$就是上面的截断系数。
Generator
在生成器的部分,要先用StyleGAN2的backbone,这个backbone的实现细节我们就不展开了,我们重点要关注这个tri-plane representation。
Tri-plane 3D representation
如果抛开代码,前置知识,这个”三平面表示“其实是EG3D最为影响深远的一个技术。后面的许多工作都沿用了这一点。在此之前,有一些工作,例如$\pi$-GAN,是纯隐式表达整个3D场的。也就是说如果到了要做渲染的那一步,你想计算$N$个点的颜色和体密度,需要直接计算$N$次生成器的前向传播,这样会很慢。另一种是完全显式的给出体素网格(但这种一般都是data source是3D object的情况了,和我们现在讨论的不完全一样。)但这种的占的空间又很大(几个GB都不止)。
所以EG3D里提出了这么一个”hybrid“的方案。StyleGAN2的生成器backbone会计算出一个256×256×96的特征图,我们可以认为3D场的信息被存储在了里面。举一个极端的例子:如果此时backbone输出的不是96张特征图,而就是一个,可能,1000×1000×1000×4的Tensor。那么我好像可以直接输入一组$(x,y,z)$,去这个Tensor里查,得到RGB和体密度(也就是完全给出体素网格,先不考虑光场)。但现在的输出是256×256×96的,被编码后的表示,我们需要将其解码出来。
所以三平面表示天才的地方在于,它是一个对偶的思路。它将96张特征图每3个分为一组,每一组里的3个特征图,分别看作三个正交的平面,然后从这三个平面构造的坐标系下去”查询“。这话非常不好理解,我们可以举个例子。假设我现在想查询的点的坐标是$(0.5, -0.75, 0.4)$,然后我有三张256×256的特征图。由于这三张图片分别充当了当前坐标系下的XY,XZ,ZY平面:
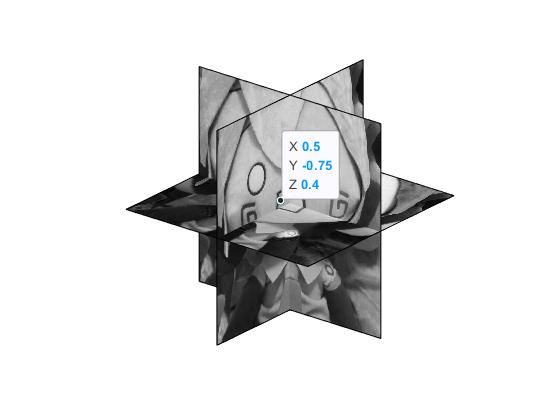
所以我们可以直接根据相应的坐标,找到各自平面的特征图上所对应的值。例如$(0.5,-0.75)$,我们将其对应到XY平面上,可以得到一个索引,比如$i=20,j=-15$,那么我们就可以找到XY平面上对应的特征图里,其$[20,-15]$所对应的值,作为$F_{xy}$,同理得到$F_{xz},F_{yz}$,如果坐标不那么圆满,就双线性插值一下。之后将$F_{xy},F_{xz},F_{yz}$加起来,作为一个小解码器的输入,然后解码后得到RGB和体密度。这种办法的好处是,得到的这些特征图,作为在给定$\mathbf{w}$下的3D场的一种隐式表示,只需要计算一次。后面synthesis函数里的use_cached_backbone,self._last_planes等选项就是这么做的。所以它在时间和空间上都取得了一个权衡。
为了更好的理解这个过程,我们现在追踪一下相关代码。在./training/triplane.py里,TriPlaneGenerator类的synthesis方法里:
1 | def synthesis(self, ws, c, neural_rendering_resolution=None, update_emas=False, cache_backbone=False, use_cached_backbone=False, **synthesis_kwargs): |
代码先根据此时相机外参和内参,计算出该位姿下,所要求分辨率下,光线的原点ray_origins和方向ray_directions。然后,之前mapping计算得到的ws会输入进synthesis网络里,计算得到planes。
planes最开始是[B, 96, 256, 256],然后被处理成[B, 3, 32, 256, 256]。然后进入了这一行:
1 | feature_samples, depth_samples, weights_samples = self.renderer(planes, self.decoder, ray_origins, ray_directions, self.rendering_kwargs) |
于是我们跳转进./training/volumetric_rendering/render.py里,ImportanceRender的forward方法:
1 | def forward(self, planes, decoder, ray_origins, ray_directions, rendering_options): |
在这里我们可以看到光线按照原点和方向进行了采样,然后进入了run_model:
1 | def run_model(self, planes, decoder, sample_coordinates, sample_directions, options): |
这里的self.plane_axes是一个[3, 3, 3]的常数张量,由如下函数定义:
1 | def generate_planes(): |
这里,每一个3×3的矩阵,可以这么来理解:前两行是它代表的平面,第三行可以看成是前两行叉乘的结果。例如第一个矩阵的第一行是[1, 0, 0],这代表x轴的单位向量,然后第二行是[0, 1, 0],是y轴的单位向量,所以这个矩阵代表XY平面。其实这个第三行,乃至这个矩阵的出现非常奇怪,可能是为了凑一个可逆矩阵,来和后面的代码匹配上。
如果第一行和第二行线性无关,那么第一行与第二行叉乘的结果必然也和他们线性无关,所以张成的矩阵满秩。
所以这个常数张量代表了XY,XZ,ZX平面!这显然是个错误,置顶的issues里讨论了这一点,但这个错误其实没有那么的严重。
出于保证论文复现性以及重新训练的成本,作者们并没有在main-branch里修复这个问题,他们开了一个新分支fixed_triplanes,然后社区里有热心群众重训了ckpt。
然后我们来看sample_from_planes(),注意此时输入的sample_coordinates已经是通过光线原点,光线方向,采样得到的坐标点了(世界坐标系下)。
1 | def sample_from_planes(plane_axes, plane_features, coordinates, mode='bilinear', padding_mode='zeros', box_warp=None): |
注意这里的plane_axes是刚才讨论的[3, 3, 3]的张量,plane_features是之前计算出来,处理成[B, 3, 32, 256, 256]的那个。然后在这里这个plane_feautures又被揉搓成[3×B, 32, 256, 256]了,然后这个时候的coordinates维度是[B, M, 3],这里的M是每条光线上需要采样的数量和一共发出的光线数的乘积。
然后全体坐标会被缩放一下,缩放倍数是(2/box_warp),在生成人脸和猫猫头的数据集里,box_warp都是1,所以就是为了把坐标放大一倍。这样做是因为下面两行用到的torch.nn.functional.grid_sample接收的是[-1, 1]的输入,而原始的坐标的范围是[-0.5, 0.5]。
然后这个project_onto_planes()就是为了将3D的坐标投影到2D平面上,但由于这里所说的平面都是XY,XZ,YZ这样的,所以其实只要一顿索引+切片就好了。但作者可能为了严谨性和普适性,还是要用矩阵乘法来向量化实现一遍(所以就有了上面的generate_planes()):
1 | def project_onto_planes(planes, coordinates): |
由于有3个平面,所以coordinates沿着新增加的一个维度进行广播,最终形状为[3×B, M, 3],然后输入的planes(这里其实是上一层函数里的planes_axes,[3, 3, 3]),计算一下其逆阵,也沿批处理的维度广播一下,变为[B, 3, 3, 3]的,为了批量的进行矩阵乘法,再将第一维合并进去得到[3×B, 3, 3]。最终用torch.bmm()批量相乘,乘完以后得到形状为[3×B, M, 3]的结果,切片只取前两位。
这个事情其实非常奇怪,尤其是这里求个逆阵,可能是想符合数学上的坐标变换时的某种形式:
但其实这完全没有必要啊,这三个用坐标轴定义来的矩阵都非常简单,而且是正交阵,其逆阵就是其转置。整个project_onto_planes()的操作其实完全就是想:
来得到相关坐标的索引,可能就是因为这块的冗余,导致他们最开始放的那个版本,这个地方投影投错了。实际上,如果返回去看generate_planes()的定义,你会发现如果在project_onto_planes()里不求planes的逆,结果就正好能表示XY,XZ,YZ平面了。
所以回到sample_from_planes(),现在坐标已经处理好了,而在整个网格里进行采样的这个过程,torch里正好有个torch.nn.functional.grid_sample可以负责,总之这个函数就封装了按照计算得到的2D投影去查特征图,然后双线性插值的过程。所以这个函数接收[3×B, 32, 256, 256]的planes和[3×B, 1, M, 2]的坐标,托广播机制的福,可以直接向量化的采样到[3×B, 32, 1, M]的张量,然后permute将其调整为[3×B, M, 1, 32],然后reshape成[B, 3, M, C]。这就是采样出的output_features。第二个维度上的3就是原文中的$(F_{xy},F_{xz},F_{yz})$。
然后回到run_model(),下面就是这一行:
1 | out = decoder(sampled_features, sample_directions) |
这里的decoder,就是一个很小的decoder,它的定义是:
1 | class OSGDecoder(torch.nn.Module): |
这只是两层MLP,相比而言朴素的NeRF需要8+1层MLP来表征,这确实省下了不少(因为相当一部分工作在StyleGAN2的生成器backbone里做了)。值得注意的是这个解码器并没有使用ray_directions,颜色并没有随角度变化,我推测这一是为了保持多视图上的一致性,二是对于猫猫头和人脸,确实没有什么Non-Lambertian的东西需要建模吧。
然后[B, 3, M, C]的sampled_features,其沿着3的那个维度求平均,然后形状变为[B, M, C],然后准备对特征进行解码,先调整形状为[B×M, C]以符合Linear的传参要求,然后输出的维度为[B×M, 1 + 32]。然后再复原回[B, M, 1 + 32],然后选取33维里第一个那个是体密度,其余的都是RGB。
太好啦,终于计算得到体密度[B, M, 1]和RGB表示[B, M, 32]了。然后你是不是这时候才发现,“你这RGB是不是不太对啊,你这根本就不是RGB啊?”,别急。我们现在还在ImportanceRender的forward里:
1 | out = self.run_model(planes, decoder, sample_coordinates, sample_directions, rendering_options) |
先拆开,准备光线追踪。体密度从[B, M, 1]->[B, num_rays, samples_per_ray, 1],RGB从[B, M, 32]->[B, num_rays, samples_per_ray, 32]。然后光线追踪是从这句进入的:
1 | rgb_final, depth_final, weights = self.ray_marcher(colors_coarse, densities_coarse, depths_coarse, rendering_options) |
这里的self.ray_marcher其实实现的比较简洁,通过看ray_marcher.py的实现可以知道和原版NeRF基本是一样的,但从代码的痕迹上可以看出参考了Mip-NeRF,但不涉及任何光锥。所以这里就不展开了。我们主要关注一下输出中的rgb_final。是的,你想的没错,它的维度还会是[B, num_rays, 32],那个光线追踪只是单纯的数值积分,没有引入什么“着色”的机制。
于是我们终于又回到了triplane这里,得到了:
1 | feature_samples, depth_samples, weights_samples = self.renderer(planes, self.decoder, ray_origins, ray_directions, self.rendering_kwargs) # channels last |
这里的feature_samples,然后它被整理成了一张图片的形状:
1 | # Reshape into 'raw' neural-rendered image |
然后,选取特征图的前三个通道:“你们分别就是R,G,B啦!”
1 | # Run superresolution to get final image |
然后这一坨,其实分辨率只有128×128,确实不太够看。于是就送入了一个超分网络提升到512×512。至此,已成艺术。
“其实feature_image中的前3个成员最开始并没有意识到什么,他们跟其他29个通道一样都是一坨浆糊。但可能是冥冥之中使命(梯度)的召唤,他们开始变得有意义。人生又何尝不是这样?”——佚名
Tri-plane intuition
好的,我们大概知道这个三平面表示怎么计算了。但是,为什么我总感觉这个表示有些没头没脑呢?这个事情应该有个逻辑啊。或者说,有个背后的直觉啊。我最开始审视这个方法的时候,我想到了大一上的工图。
为了找到答案,我有在网上搜索一些,但鲜有人提这回事。我翻到了EG3D一作在油管上上传的一个视频,发现他居然也是拿三视图说事,然后一句带过了。
这背后的灵感可以从稀疏网格和张量分解里窥探一下。我们输入$(x,y,z)$,往往想知道一个辐射场$\mathcal{F} _{\left( x,y,z \right)}$处的特征(体密度,颜色)。但如果我本就把voxel的这种归纳偏置带出来,建立一个稀疏的可学习的网格,这样就可以省去用MLP去”synthesis”,可以直接在这个网格上查。如果需要,再用一个规模小很多的MLP去提取一下。这最早是Plenoxels先成功实现的。
而网格作为一个3D张量,倒也不需要表征的那么稠密,可以使用张量分解技术,这样我们只需要学习更小数量的元素就好了。例如CP分解(Canonical polyadic decomposition),给定$\mathcal{A} \in \mathbb{R} ^{I_0\times I_1\times I_2}$,其可以被表达为:
这里$\mathbf{a}_{0,r}\in \mathbb{R} ^{I_0},\mathbf{a}_{1,r}\in \mathbb{R} ^{I_1},\mathbf{a}_{2,r}\in \mathbb{R} ^{I_2}$,可以理解为将一个稠密的张量,分解为若干向量组的外积。用matlab,randn三个向量,求取张量积
可以看见这是一种有充沛表征空间的表示,$R$个这样的比较稀疏的表示(或者说“子空间”)加起来,逼近$\mathcal{A}$,是一种非常合理的操作。这种分解方式也不唯一,TensoRF在此基础上引入了更一般的VM分解(vector-matrix decomposition)。
在EG3D中,我们没有直接从网格/向量开始优化,换句话说,我们没有确定张量分解的分解方式。我们直接从StyleGAN2生成器的backbone里得到了特征图的表示,假设它是一种富有表现力的结构,那么通过3个3个一组,然后每3个张成一个子空间。最后将采样得到的$(F_{xy},F_{xz},F_{yz})$取平均,即求和。
直觉来讲,求和确实是一个比求积更“稳定”,变化更“少”的操作。所以最近的一篇工作k-planes里认为应该求积,并且用局部响应的图示来说明了一下。EG3D的作者回答时也说当时是出于简单考虑。
上面的代码分析里,我们知道求和后的张量,最后输入解码器时的“通道数”为C,所以在那两层MLP里,这些每个子空间里采样得到的张量和,就近似上面的CP分解一样,“求和”在了一起。最终作为一个3D场的表示。这基本就是我认为的“三平面表示”背后的直觉了。
值得注意的是,其实这一节里提到的那三个工作,应该都是在EG3D以后出现的,所以不得不佩服于EG3D作者们当时的洞见。
Discriminator
判别器这里并没有很多的内容,只是一些很小的改动。我们可以看一下run_D:
1 | def run_D(self, img, c, blur_sigma=0, blur_sigma_raw=0, update_emas=False): |
为了防止多视角歧义,将低分辨率RGB图进行上采样,和超分后的图并在一起作为6通道的输入,送入判别器。(如果是真实图像,那就模糊一下,然后再拼在一起。)
这里的blur其实也比较有来头了,最开始引入是在StyleGAN3,当然也不排除在此之前人们就这么用,来防止NN过分拟合高频部分了。
Trailer
写了这么多,就为了这时候呢。
EG3D是一项大工程,所以它的Requirements做的很好:
- 1–8 high-end NVIDIA GPUs. We have done all testing and development using V100, RTX3090, and A100 GPUs.
尤其当它提到,在这些显卡上测试了以后,就最好用这些显卡来跑,我在autodl上随便拉的是一个4090,然后我就吃到了这个。
老老实实在单卡3090上就可以玩了捏:
其脚本还提供了不同的风格向量之间插值的功能:
可以看到最后的结果在性别,肤色上丝滑的过渡。
但这些都是随机数摇骰子的结果,EG3D并没有提供更多样化的condition的操作。毕竟GAN没有diffusion那么好”manipulate“,就像小说《诗云》里,“李白”得到了整个汉字的排列组合,但也找不到里面哪些是比李白更好的诗一样。
但别急,我们遇到的问题没有那么富有思辨,我们可以用GAN inversion这项技术从$\mathcal{W}$解算出某张图片对应的$\mathbf{w}$。具体来说使用的PTI(Pivotal Tuning Inversion),这个PTI基本就是先微调风格向量,然后再微调一下生成器。
有一个非官方的仓库将其与EG3D整合在了一起。但是,让它运行起来还是花了一些功夫的。
首先,对于我们随手找来的一张图片(wild image),需要进行预处理。需要在Deep3DFaceRecon的库的基础上进行操作。在安装这个库的时候,我们一定要敏锐的注意到yml文件里用的是python3.6,和tensorflow 1.15.0,这在我愉快的开箱即用时产生了多米诺骨牌效应,具体来说:
我在一台有3090的服务器上安装了这个环境,然后我发现,我一顿conda env创建的环境好像把默认的cuda给卸了,然后我发现我不能用GPU。因为30系及以上的卡用的安培架构,cuda版本必须在11以上,新装的cuda是10.几。然后我以为我可以纯CPU的作inference,但那里面好像在某一步需要一个光栅化的东西,于是我只能推倒重来换成2080ti。
非常害人,当时我又开了一台3090的实例,然后发现我一load预训练的pkl怎么就爆显存,哪都排查了一遍,比如pkl丢包,僵尸进程,torch-cuda版本等,然后发现换台机器就没事了。所以autodl上的有些卡可能已经超出使用寿命了,要当心。
然后我又卡在了nvdiffrast那里,先是缺依赖,又说[F glutil.cpp:338] eglInitialize() failed Aborted (core dumped),然后在issues里找到将所有dr.RasterizeGLContext换成dr.RasterizeCudaContext,然后我居然发现我没有后者?于是我又卸了重来了一遍,发现原始仓库导向的那个库是旧的,作者说了更新指向了但我不知道为什么还是指向旧的。
于是这么一顿奇幻漂流以后,终于把预处理的部分搞定了。预处理基本就是两步,一,将这个图片里的人脸裁剪出来;二,估计相机位姿出来。根据我的测试,第一步的裁剪非常重要,裁剪对inversion后的结果影响最大。
然后就可以愉快的进行PTI了。我选取了FFHQ数据集里的数据,2077捏人面板和游戏内的截图:






但上面gif最后的结果是微调风格向量后的,接下来第二步微调生成器,我好像一调,超分的功能就受损了。下面是最终的结果:
可以发现,对于FFHQ上的真实人脸,效果是最好的。对于虚拟合成的女V,其五官生成的也很标志,但可能头发确实过于抽象了,没法生成出那种卷的效果来。至于强尼银手的那个case,我感觉可能是光影的原因。但这也是事实意义上的”单视图三维人脸重建“,所以还是很好玩的。
以及最后我还进行了一个经典的OOD测试,我直接把一张动漫图片输入进去(如果老老实实走预处理的流程,其实根本就进不来,因为动漫头像上不会被arcface里的模型检测出人脸,也就不会有detection.txt,于是也就中断了。但为了搞事,直接把一个算好的位姿和图片张冠李戴也不是不行。)








以及还有一些比较好玩的功能,例如把人变年轻:
把人变老:
变换性别:
改变表情(主要是笑脸与否):
这个是一个比较老的GAN里的把戏了,只不过这个能无痛在3D-aware GAN里做出来还是挺新奇的。
End
”薄凇缀霜洲没落朽,料峭撩盏叩销离忧。千山叠寒飞雪渡头醉深笑幸否,未道好梦枕休醒我光阴久。“

