
现在是2022年了,通过任何一个途径来入门炼丹的人,大多只会念叨“交叉熵损失函数”,“均方误差损失”然后筛选丹方上炉开炼。很少有人在意……那些以前的理论了…大概吧。
Warm up
贝叶斯理论其实有着重要的地位,只是由于其较强的假设和实际操作的困难导致现在已经提及的不多了。故事的开始是这个熟悉的式子:
根据概率中的乘法原则,可以写作:
这在高中学到条件概率和大二上学概率论时往往会是一道练习题的形式,使用乘法原则代换后进行计算。但是它有着更深刻的用处,我们这里只关注“分类”这一任务,即构建一个分类器,或许在很后面我们可以有时间介绍这一原理在别的任务,比如“生成”上的应用。
分类任务阐述为,共$M$个类别$\left\{ \omega _1,\omega _2,…,\omega _M \right\} $和一个表示未知模式的特征向量$\boldsymbol{x}$(从此处开始我们要有意识的使用矢量符号 写的时候我发现逐个加\boldsymbol真的好费劲啊,算了算了),之后生成对应$M$个的条件概率$P(\omega_i|\boldsymbol{x})$,通过这些条件概率来判断该特征向量到底属于哪个类别。
在进一步叙述前,要注意到,最开始列写的贝叶斯公式实际上是考虑的离散型随机变量(A和B),对于连续型随机变量,我们知道我们可以用它的概率密度函数来描述它,即:
下面我们把这个式子改写成模式识别里常用的形式,$x$会是分类类别$\omega_i$,$y$是特征向量$\boldsymbol{x}$,为了简洁,概率密度函数统一用小写的$p$表示,概率则为$P$。注意到,分类任务中的$\omega_i$其实是离散的,所以:
等式左侧是我们要求的某一类的后验概率,$p(\boldsymbol{x})$是关于特征向量$\boldsymbol{x}$的概率密度函数,$P(\omega_i)$与$\boldsymbol{x}$无关,被称为先验概率。至于$p(\boldsymbol{x}|\omega_i)$,它被称为类条件概率密度函数,在这个理论框架里,它应该是已知的,如果它未知,可以由已知的数据集进行估算,这个我们后面再说。
这三者第一遍听可能会使得人很困惑,没关系,带入一个简单的情景(经典的鲈鱼和鲑鱼的例子,但我魔改一下)即可:
每天的渔获假设只有鲈鱼$\omega_1$和鲑鱼$\omega_2$,那么查阅历史数据可以知道每天捕捞上来的鱼里大概由多少是鲈鱼多少是鲑鱼($P(\omega_1)\approx N_1/N,P(\omega_2)\approx N_2/N$),这就是先验概率。这里假设每天捞上来的分布是一样的,不会有捞着捞着鱼没了或者鱼的年龄分布变了等情况。
假设分类器通过鱼的长度来进行分类(这太愚蠢了),那么它对于历史数据,是有一个对长度$x$的预期的,比如出现20cm的鱼的概率是多少,出现10cm的概率是多少,这就是$p(\boldsymbol{x})$。
至于$p(\boldsymbol{x}|\omega_i)$,它也是先验知识的一种,比如鲈鱼的长度大概是10~20cm,鲑鱼的长度大概是15~25cm,它们各自服从一个特殊的分布。
结合上述三个信息,我们就能计算出,当抽样出的长度为$\boldsymbol{x}$的鱼,是鲑鱼还是鲈鱼的后验概率。
显然,直觉告诉我们,后验概率哪种越大,那它就是哪种鱼。这种分类器也成为贝叶斯分类器,它在最小化分类错误概率上是最优的。严格的论述如下:
分类正确的概率$P_c$可以表述为:
求和符号里的联合概率可以写作:
所以分类成功的概率:
容易看出,如果按照下式选择分割区域$\mathcal{R} _i$,可以使得$P_c$最大:
所以此时$P_e=1-P_c$最小,由贝叶斯公式,上述的分割标准正好即选取最大的后验概率:
但最小化分类错误概率并不一定是最好的标准,因为它使得所有错误的重要性都相同。但有时某些错误会导致更严重的后果,基于此,另一个分类准则是最小化平均风险,我们要对所有分类错误的情况,根据其重要性来进行加权,构造一个平均风险来最小化它,这同样是一个选择分割区域$\mathcal{R}_i$的问题:
由于正确分类是不需要加权的,所以$\lambda_{kk}=0$,与最小化错误率类似的,为了使得$r$最小,我们可以如下选择分割区域$\mathcal{R}_i$:
此时积分和可以保证最小,由$\lambda_{ij}$构成的矩阵记作损失矩阵$L$。特别地,如果我们取:
此时:
我们发现它和最开始的最小化分类错误是等价的。
好了,现在那些迷迷糊糊的在为了表示多分类时引入的求和,积分符号该消失了。我们具体的举一个例子,看看会发生什么:
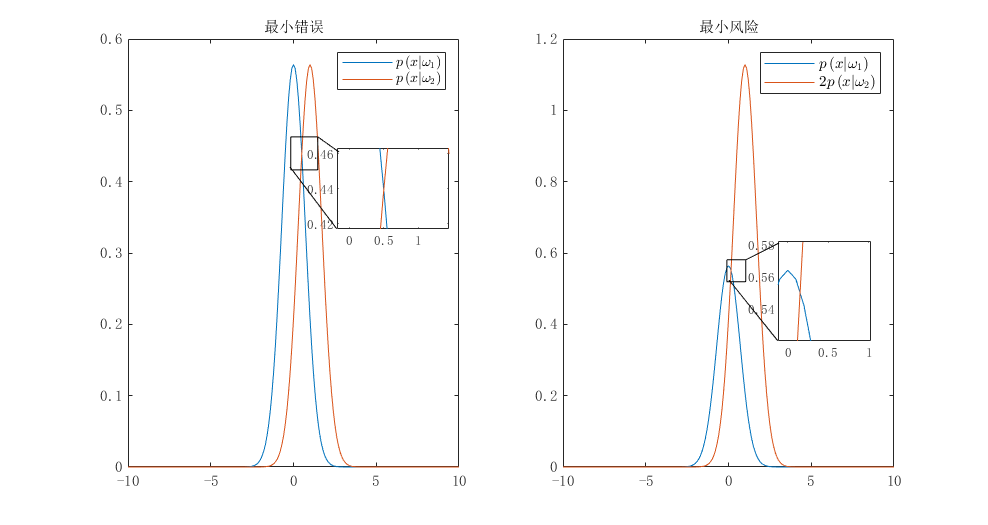
在某个二分类问题中,单个特征变量$x$的概率密度函数是高斯函数,两个类别的方差均为$\sigma ^2=\frac{1}{2}$,均值分别是0和1,即:
先验概率$P\left( \omega _1 \right) =P\left( \omega _2 \right) =\frac{1}{2}$,计算最小错误概率情形下的阈值$x_0$,当损失矩阵为:
计算最小风险下的阈值$x_0$
有了前面的铺垫,我们直接计算即可,先验概率相同,我们直接约去:
得最小错误概率下$x_0=1/2$,当是最小风险时,记住$\lambda_{ki}$的下标:
得$x_0=(1-\mathrm{ln}2)/2$,可以发现阈值向左移动了。为了便于记忆,我们可以只记$L$的下标,$\lambda_{ij}$指的是在分类$i$时错误$j$的权重,在这里,$p\left( x|\omega _1 \right)$在$p\left( x|\omega _2 \right)$的左侧,所以$\lambda_{12}$指的就是分类$\omega_1$时错判成$\omega_{2}$的权重,我们发现这里$\lambda_{12}<\lambda_{21}$,可以直观的理解成:把$\omega_2$错分成$\omega_1$更加严重。所以阈值一定会向左移,这样更不容易错分,或者“宁可把$\omega_1$分成$\omega_2$”。与计算的结果是相符的。
Gaussian
在刚才推导贝叶斯分类时,我们直接构造了分割方式$\mathcal{R} _i$,在上面举的例子里,它是一个一维的区域,如果进一步扩展,它会是一个超平面。理论上,我们也经常构造一些超平面来作分析,比如在对抗攻击中(PGD)。一方面是因为线性便于分析,另一方面是在一种广泛存在的现象中,决策面确实是平面。
首先,我们先引入关于决策面的语言,例如在之前的最小化错误概率中,特征空间被分割为了$M$个区域,区域$\mathcal{R} _i$和$\mathcal{R} _j$正好相邻,对于最小错误概率下,决策面可以写作:
在决策面的一侧,差值为正,另一侧为负。一般地,定义判别函数为:
其中$f(\cdot)$是一个单调递增函数,这是用一个数学中的等价函数来代替直接的概率,此时决策面的描述即写为:
引入$g(x)$是因为,很多情况下,涉及的概率密度函数不一定可知,它们或许很复杂,或许很难估计,有时直接借助$g(x)$来直接计算决策面可能更适合,采用这些方法计算的判别函数和决策面与贝叶斯分类无关,我们到时候再说。
现在我们来探究正态分布下的贝叶斯分类,在概率论中,我们知道一维高斯函数:
以及,二维的高斯分布函数:
至于更多维的情况下呢?我们think step by step,为了清晰,我们先选取$l$个独立的随机变量$x_1,x_2,…,x_l$构造一个随机列向量$x=[x_1,x_2,…,x_l]^{T}$。它们服从标准正态分布,根据一维时候的高斯分布和联合概率密度:
将指数部分进行整理,写成矩阵/向量形式:
之后,对于更一般的正态分布,我们可以通过一个变换:
随机变量的换元满足:
证明见《概率论与数理统计》茆诗松,$J$是雅可比矩阵。在上面的变换中:
所以,换元后的概率分布为:
注意到之前的变换,以及最初的标准正态分布$\boldsymbol{x}$:
所以我们发现,$Cov(\boldsymbol{y})$所指的协方差矩阵就是$AA^T$,它是一个实对称矩阵,记作:
最终我们得到了书上所说高维高斯分布:
注意,由于$\varSigma$是半正定的,这也就导致了高维高斯分布的截面始终是一个超椭球,在二维时是熟悉的椭圆。现在我们来探究高斯分布下的贝叶斯分类器,由于指数的出现,$f(\cdot)$最好选择对数函数$\ln(\cdot)$,此时每个类别都服从多元正态分布$\mathcal{N} \left( \mu _i,\varSigma _i \right) ,i=1,2,…,M$:
进一步,可以把判别函数里的二次型拆开:
下面我们进一步研究在二维情形下的分类情况,因为此时的几何直观比较强:
我们假设:
则二维情形下的$g_i(\boldsymbol{x})$可以写作:
Hyper Plane
我们不必研究协方差矩阵不为对角阵的情况,我们知道那只是将上式表示的二次曲线再作一下拉伸或旋转的变换。观察可得,对于决策曲线$g_i(\boldsymbol{x})-g_j({\boldsymbol{x}})=0$,二次项的符号决定了它是椭圆,还是双曲线,还是抛物线。
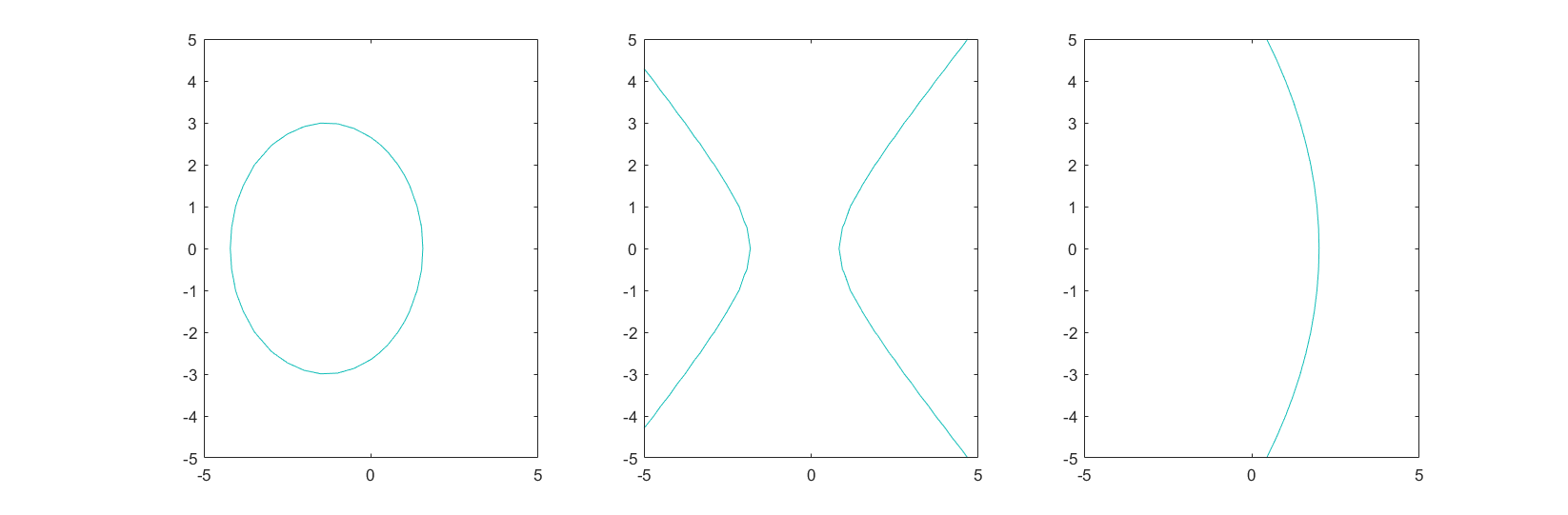
实际上,我们可以画出上面三个例子的真实分布:
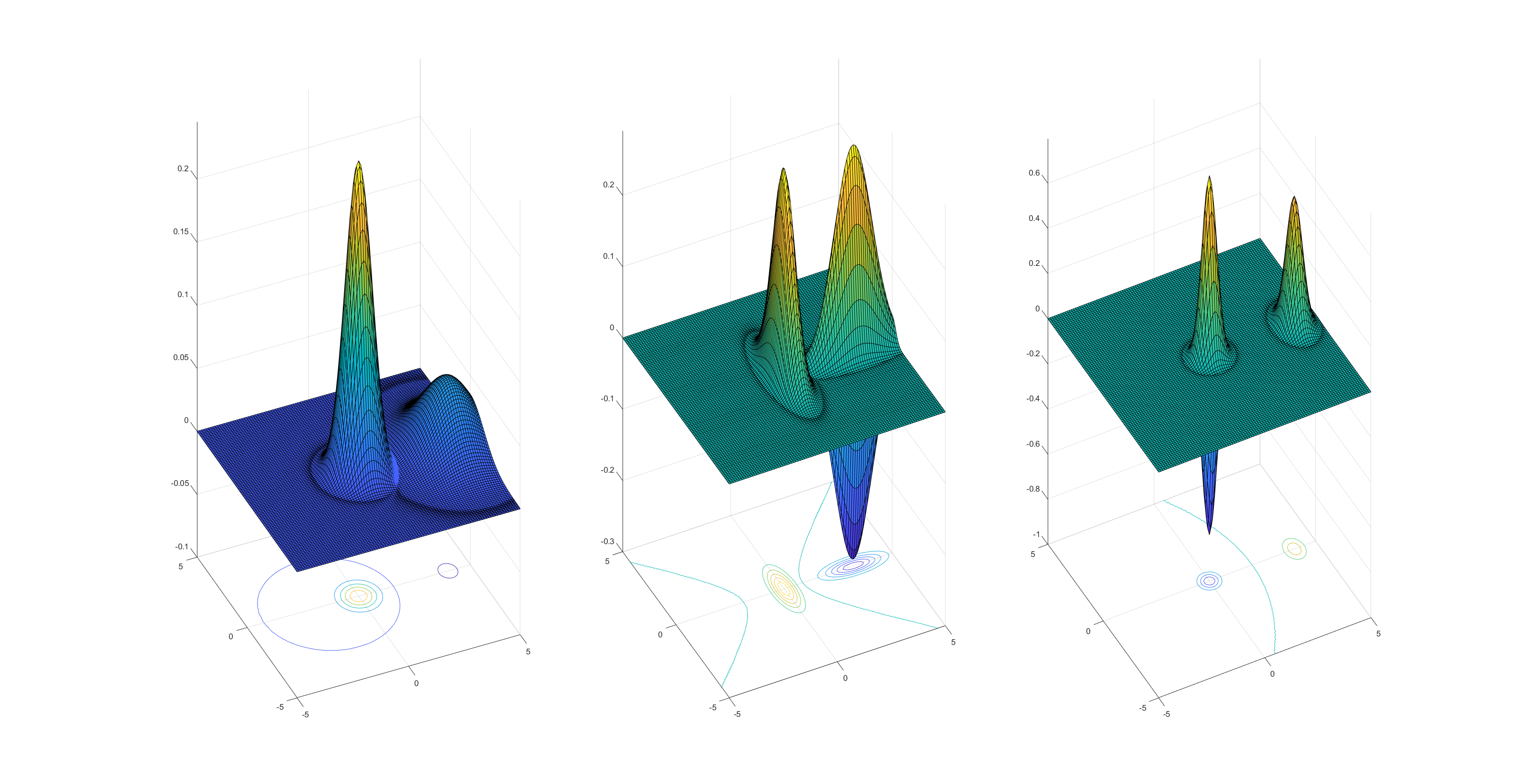
除了这三种情况以外,还有一种更加特殊的情况,如果所有类的协方差矩阵是相同的,那么自然二次项在决策曲线上会消失,二次项在计算最大值时不参与比较,同时$c_i$此时也是每一类都一样的,那么可以重新定义$g_i({\boldsymbol{x})}$为一个超平面:
此时的决策边界:
这样写比较繁琐,可以进行进一步的化简,以便后面的分析:
这个推导里要注意两点:就像$y=ax+b$可以提$a$写成$y=a(x+b/a)$一样,对于常数项$\ln \left( \frac{P\left( \omega _i \right)}{P\left( \omega _j \right)} \right)$在化简中也是这么操作的,如上式那么分子分母同乘$\boldsymbol{\mu }_i-\boldsymbol{\mu }_j$是为了凑出下一行里的$\varSigma ^{-1}$范数:$\left| \boldsymbol{\mu }_i-\boldsymbol{\mu }_j \right| _{\varSigma ^{-1}}^{2}$,这是一种约定俗成的习惯。
第二是要注意,不能错误的认为$x^TAx-y^TAy=\left( x-y \right) ^TA\left( x-y \right)$,实际上是$x^TAx-y^TAy=\left( x-y \right) ^TA\left( x+y \right) $。可以拆开验证一下,实际上这个式子即小时候经常遇到的$x^2-y^2\ne \left( x-y \right) ^2$的高维形式,但由于薄弱的数理基础,可能还是会犯这样的错误。
由$g_{ij}\left( \boldsymbol{x} \right) =\boldsymbol{w}^T\left( \boldsymbol{x}-\boldsymbol{x}_0 \right) $可以看出,此时决策面是过$\boldsymbol{x}_0$与$\boldsymbol{w}$正交的超平面。此时我们是假设各个分类的协方差矩阵都相同,实际上,这个条件可以更强:协方差矩阵均为对角阵(即协方差为0,方差均相同),此时可以有一些更有利的条件,例如此时$\boldsymbol{w}$退化为只与$\boldsymbol{u}_i-\boldsymbol{u}_j$正交,此时如果先验概率均相同,那么$x_0=\frac{1}{2}\left( \boldsymbol{\mu }_i+\boldsymbol{\mu }_j \right)$,如果此时一方的先验概率比另一方大,会导致超平面发生平移,例如当$i$的先验概率比$j$大时,实际上超平面会向$\mu_j$移动,这是符合直觉的,即先验概率大的或许后验概率也会大。
这里其实还有另一个角度,如果一开始不作$g_i(x)-g_j(x)$,直接从$g_i(x)$入手,我们甚至不需要展开它,会发现:
如果协方差矩阵仍然为某一标量倍的对角阵,那么上式的二次项直接等价为$\boldsymbol{x}-\boldsymbol{\mu }_i$的欧氏距离的平方,当协方差矩阵没这么特殊时,它也可以等价为一个距离的平方,这个距离叫作马氏距离,那么它有什么特殊的地方呢?
我们知道,实对称矩阵一定可以相似对角化,所以:
其中,$\varPhi ^T=\varPhi ^{-1}$,即正交矩阵,$\varPhi $的列向量即对应$\varSigma $的正交特征向量,那对于有着相同距离$c$时的情况,我们直接联立:
我们记线性变换$\boldsymbol{x}^{‘}=\varPhi ^T\boldsymbol{x}$,那么与$\mu_i$一起,得到的就是原始向量在特征向量上的投影,直接展开:
这就得到了一个超椭球体,可以想象,这与欧式距离产生的超球体有明显的不同。当我们对$x_1,x_2,..$赋予一个实际意义时,这样往往更有意义,可以考虑到不同特征间的相互关系,以及对不同的特征施加不同的尺度。下面做了一些可视化:
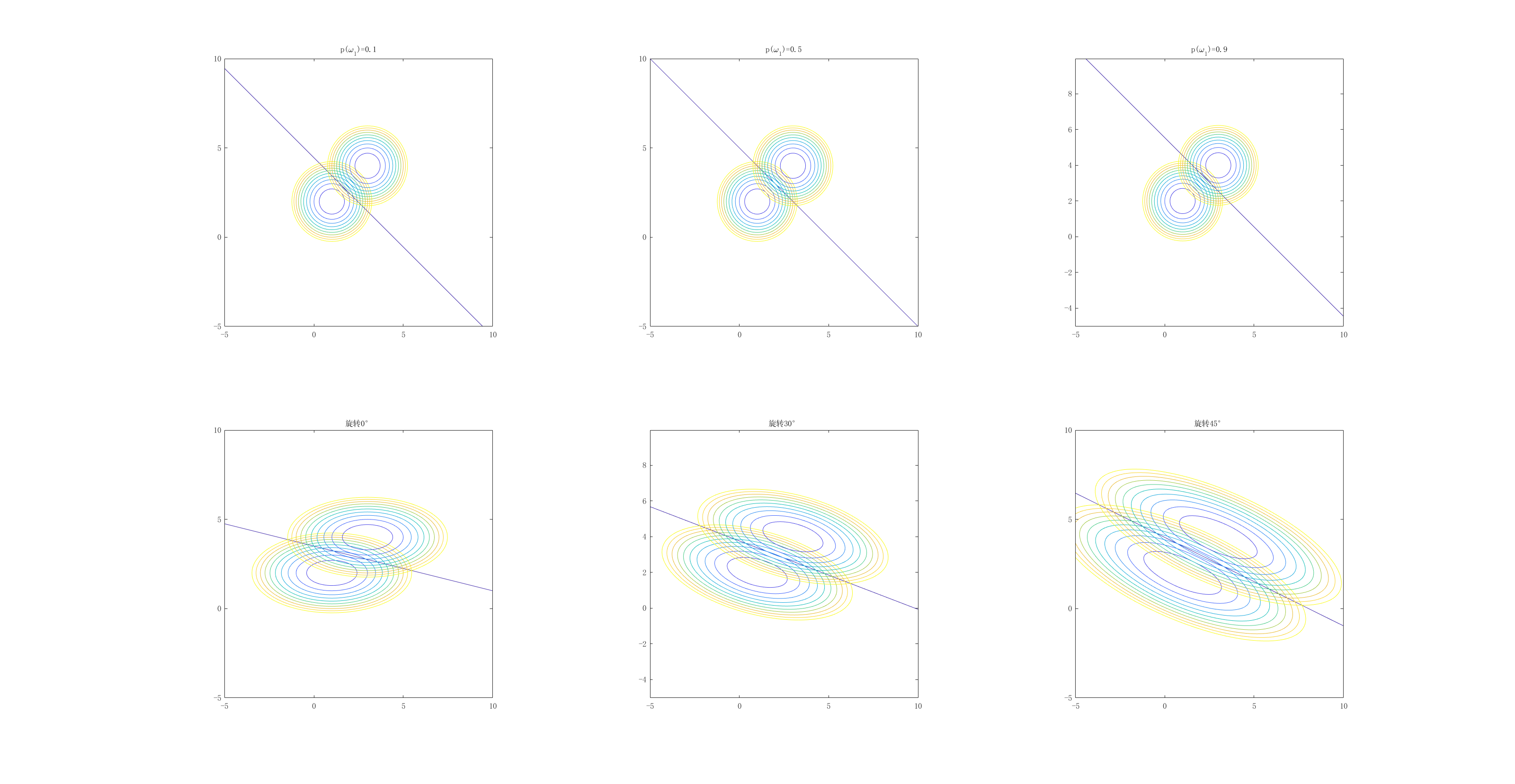
第一行展示了在协方差矩阵对角线相同时先验概率变化的情形,与我们的推断是一致的。第二行展示了非对角的协方差矩阵的情况。在这里我停留一下论述一个事实,由上图我们也能看出,非对角的协方差矩阵可以由一个旋转变换得到。实际上这已经是全部的非对角协方差的情形了,我们不该觉得其有什么特殊。实际上,还是归结于实对称矩阵的相似对角化,就像之前所说的$\varSigma =\varPhi \varLambda \varPhi ^T$,其中$ \varLambda$即拉伸变换,$\varPhi$是正交变换,它可以理解为某种旋转,而$\varPhi^T$由于满足$\varPhi \varPhi^T=I$,所以是对应的逆变换,相当于“转回来”。
End
在实际应用中,高斯分布被普遍的用来描述某种事物的分布,因此贝叶斯分类要不就是线性的,要不就是二次的。取决于对其协方差矩阵的假设,为了判断各自的协方差矩阵是完全相同还是不同的,常用最大似然估计。如果我们假设是线性的,那就会引入线性判别分析;如果是二次,那就是二次判别分析,这是下一篇要写的了。

