
“学习不能在一台抽象的计算机完成,必须针对一台具体的计算机来完成学习过程。”一方面是这学期开了这门课,另一方面是为考研作铺垫,所以整理一下这门课的知识。
首先这门课选择了一个经典具体的Intel 8086/8088来分析,先考虑8086。不同CPU寄存器设置等不尽相同,与之前central processing unit那篇实现的简单的单总线三级时序CPU不同,8086稍微复杂了一点点。
这门课十分具有我国特色,我在作总结时参考了三本教材:微机原理与接口技术(第二版)西安电子科技大学出版社,微机原理与接口技术(第五版)电子工业出版社,和王爽老师的《汇编语言》第三版。大概我在hexo d的时候只会写到前三章(以西电出版社那本为准),所以会长期更新。
Intel 8086 CPU
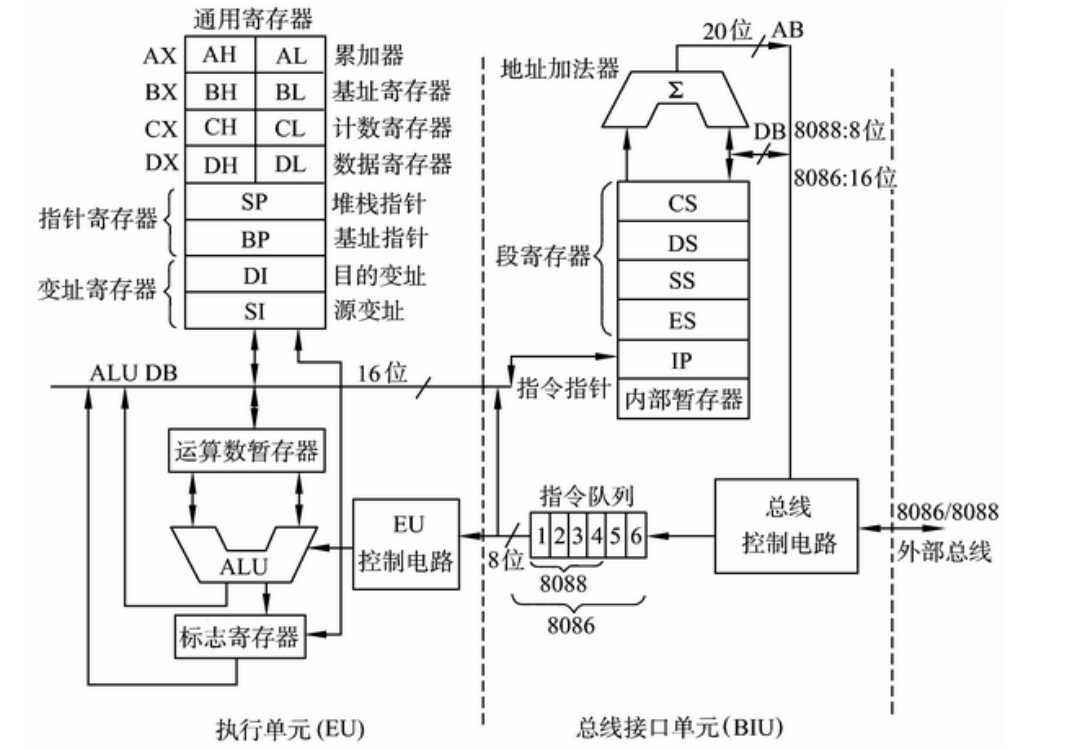
上图是大多数教科书中关于8086CPU的插图,从内部结构上看,它分为四部分:寄存器,控制器,算术逻辑单元,I/O控制逻辑,这四个部分在之前blog的toy model里已经被讨论过了。从功能结构上看,它可以分为两个独立的逻辑单元,执行单元EU(execution unit)和总线接口单元(bus interface unit)。这种划分方式和之前的讨论有所不同:
如插图所示,EU是用于执行规定的操作。BIU用于完成取指令,存取数据的操作。这里的这个指令队列,是一个新物件,在之前的简单模型中是没有的。一般来说,EU和BIU可以独立,并行执行。执行过程中,满足如下规则:
(1)指令队列无指令,EU处于等待状态。
(2)指令队列满了,EU没有访存的需求,BIU空闲。
(3)指令队列有两个空闲字节,BIU自动执行取指令
(4)EU执行时,需要取存储器或IO数据,此时BIU如果正在取指令,则等待BIU完成取指令周期(回忆之前的三级时序)然后再完成EU的要求。
(5)在EU执行转移,子程序调用或返回等指令,清空指令队列。
这五个规则基本刻画了整个执行指令的行为模式,这里不是重点。这样做有种流水线般的好处,可以取指令和执行指令同时进行,效率更高。而之前单总线的模拟里,我们只能串行的执行取指令,执行指令,这降低了计算效率。
之后是寄存器组,8086CPU一共有14个16位的寄存器,哦对,8086CPU的机器字长是2个字节,16位。按功能可分为8个通用寄存器,4个段寄存器,2个控制寄存器。第一个和最后一个感觉可以顾名思义,但中间的这个“段”给人不知所云,在介绍后面的内容时我们要先对这个概念有所理解:
我的一个朋友经常用“segmentation fault”来形容他身陷囹圄的状态,当然他是从编译器里学来的这句话,这里的segmentation就是“段”,放到8086里来说,8086内部用两个16位地址合成的方法来形成一个20位的物理地址,或者叫有效地址(EA)。
我们揣测一下当时人们的思路,reinvent下这个思路:这里所有的寄存器都是16位的,寻址能力只有64(1K=$2^{10}$)KB。不知怎么的我希望寻址能力 能到达1MB($2^{20}$),直接取出来的地址显然不行,一个直接的思路就是用两个地址,分别代表低位和高位,来表达一个高位地址:
这里这个高位地址称之为段地址,低位称之为偏移地址。但我们不应错误的认为内存被划分为了一个个段,实际上内存并没有被分段,段的划分只来自CPU。如果编程需要,若干地址连续的内存都可以看作一个段,偏移地址的长度也是16位,所以一个段的长度为64KB。
这一过程在BIU的地址加法器那里完成,总之当我们要指出一个物理地址时,我们需要一个段地址和偏移地址,自然,它们会由两个不同的存储单元(寄存器或存储器)提供。有了这个铺垫以后我们给出这8个通用寄存器,结合英文名进行记忆更有效:
| 寄存器 | 功能 |
|---|---|
| AX(accumulator) | 一个很常用的寄存器,完成乘法和除法时的累加,就像计组里booth乘法时的那样 |
| BX(base register) | 它常用于地址寄存器来给出一个偏移地址 |
| CX(count register) | 它用于循环语句中的计数 |
| DX(data register) | 它用于…寄存数据…… |
| SI(source index) | 源变址寄存器,提供源操作数的偏移地址,见于字符串操作 |
| DI(destination index) | 目标变址寄存器,提供目的操作数的偏移地址,见于字符串操作 |
| SP(stack pointer) | 堆栈段的偏移地址(栈顶),其默认段地址由SS(在后面)提供,它会因为出栈入栈而变化。 |
| BP(base pointer) | 它只是给出一个堆栈段的“基”偏移地址,默认地址同样SS提供,它大概是不变的(base之意)。 |
其中AX,BX,CX,DX也可以拆成两个8位寄存器来用,高位记作H,低位记作L。但要注意,在CPU按8位寄存器调用时,例如AH和AL,两者是无关的。例如在加法时,不能错误的认为,使用AL作加法,如果出现溢出,会自动进位到AH中。由于设计上的原因,只有BX可以作为地址指针,来给出偏移地址。这就是为什么要有另一组寄存器(SI,DI,SP,BP)的原因。接下来是4个段寄存器。
| 寄存器 | 功能 |
|---|---|
| CS(code segment) | 用于存放当前执行程序的段地址 |
| DS(data segment) | 用于存放当前数据段的段地址 |
| ES(extra segment) | 用于存放当前附加数据段的段地址 |
| SS(stack segment) | 用于存放当前堆栈段的段地址 |
可以看出,段寄存器都负责记录一个段地址,但它们记录的对象并不一样。实际上可以把CPU划分为三个区域:程序区,数据区,堆栈区。根据这些寄存器的名字,可以看出三个区的默认段寄存器为CS,DS,ES。这些里面更细致的细则在各种汇编指令时再提,实际上可以看出,段寄存器与表示逻辑偏移地址的寄存器的隐式关系,如CS:IP,SS:SP,DS:BX,DS:SI,DS:DI,DS:imm。
现在先给出最后两个控制寄存器:
| 寄存器 | 功能 |
|---|---|
| IP(instruction pointer) | 给出下一条指令的偏移地址,与CS结合使用 |
| PSW(processor state word) | 记录各种标值位 |
实际上,IP的另一个名字就是PC(program counter),在计组和toy model里我们都见过它,PSW我们也在学加法时见过他,当时我们是关注它记录ALU的状态,实际上还有别的功能,用到再说。它有时也叫FR(flag register)
总的来说这里有许多记忆的内容,实际上是因为我们把8086从具体的电路中抽象了出来,比如为什么CS和IP联合使用,是因为电路确实是这么连的。
brief introduction of assemble language
下面我们开始介绍汇编语言,这是连接机器语言和高级语言的重要一节。与高级语言一样,汇编语言中同样可以定义变量。变量应该有五个属性:段地址,偏移地址,类型,长度,大小。变量类型有以下五种:
| 类型 | 长度 |
|---|---|
| DB(定义字节变量) | 8位(1字节) |
| DW(定义字变量) | 16位(2字节)(1字) |
| DD(定义双字变量) | 32位 |
| DQ(定义长字变量) | 64位 |
| DT(定义很长的变量) | 10字节 |
西电教材里的7个例子很好形容了变量的规则:
1 | VAR1 DB 12H, 0A5H, 18+20, 50/3, 0, -1 |
假设VAR1的偏移地址是0000H,存储器分配图为:
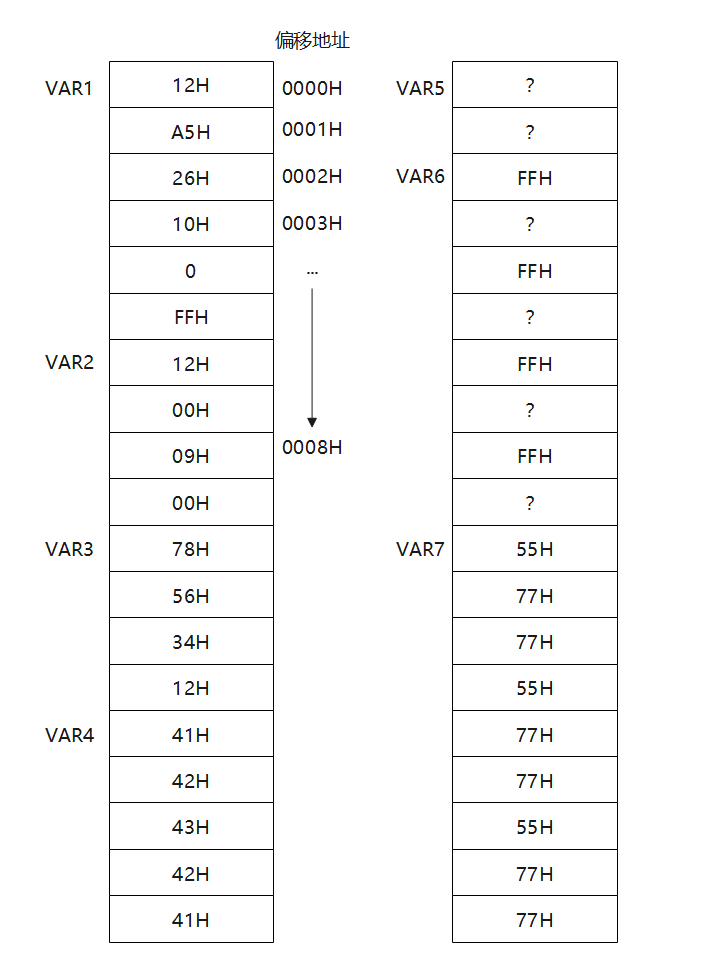
下面我们根据上面的VAR1~VAR7复习一下一些琐碎的知识。首先我们可以声明一个常数或多个,一个时就与C语言中的int a类似,a是一个整型。当有多个常数时,类似一位数组。当有多个时从低位到高位依次存储。值得注意的是-1,我们知道计算机中以补码来存储,那么-1的原码为10000001,补码为11111111,所以是FFH。
对于VAR2中的$,它在这里的意思是当前的偏移地址,所以这里为08H+1=09H。VAR3,定义的是一个32位变量,12345678H先存低位再存高位。特别指出,对于VAR4,注意第一个声明是8位DB,而’A’,’B’,’C’等ASCII码一个字母即代表8位。此时相当于DB ‘A’, ‘B’, ‘C’,所以按顺序低位到高位存A,B,C。当定义变量类型为DW时,相当于DW 4142H,所以低字节低位,高字节高位,就像12345678H一样。VAR5中出现的?代表先占位。VAR6和VAR7中的DUP为重复次数。
下面我们要关注指令操作和数据的存放位置,即数据的寻址方式。与计组不同的是,我们同样需要依托于一个实际存在的指令来给出数据的寻址方式,即MOV指令:
1 | MOV DST SRC |
这条指令将源操作数所指出的数据传送到由目的操作数所指定的地方。继而就会有不同的寻址方式。下面我们先重点关注寻址方式,一些其他细节会在专门介绍MOV指令时给出。
1.立即寻址(immediate addressing)
操作数就在指令中,作为指令的一部分存放在内存中。
1 | MOV AX, 34EAH |
将34EAH直接送入AX中。
2.寄存器寻址(register addressing)
如果操作数在寄存器中,那么源操作数和目的操作数都可以采用这样的寻址方式,不是所有的寄存器都可以,后面说MOV指令时再给出。例如:
1 | MOV AX, 1234H |
第一条即立即数寻址,之后AX会变为1234H。第二条指令使用寄存器寻址,将高位的12H给到AL,所以最后AL也为12H。
后面依次是五种存储器寻址,即我们前面讨论过的那个1MB的空间,此时就不能像前面那两种那么方便了,因为前面不管是立即数还是寄存器,都是在CPU内部的。这里自然就需要那一套段地址和偏移地址来给出在存储器中的地址了。
3.直接寻址(direct addressing)
1 | MOV AX, [3E4CH] |
“[]”内给出的是被访问内存单元的逻辑偏移地址,此时逻辑段地址隐含在DS中。对于第一条,即将物理地址为(DS)×10H+3E4CH的数据读入AX中。第二条即将BL的8位数据写出到(DS)×10H+1234H的内存单元中。注意第三条,第三条给出了一种“段超越”的写法,此时的物理地址即从默认的(DS)×10H+1234H变成了(ES)×10H+1234H。这个段超越并不是任意的,下表给出了8086在存储器读取时的默认段和可段超越的选项:
| 存储器存取方式 | 约定段 | 可超越使用的段 | 偏移量 |
|---|---|---|---|
| 取指令 | CS | 无 | IP |
| 堆栈操作 | SS | 无 | SP |
| 源字符串 | DS | CS,ES,SS | SI |
| 目的字符串 | ES | 无 | DI |
| 用BP作基址 | SS | CS,ES,DS | 有效地址 |
| 通用数据读写 | DS | CS,ES,DS | 有效地址 |
显然,存储器的读和写不能同时进行,所以源操作数和目的操作数均为存储器的指令是非法的。
4.寄存器间接寻址(register indirect addressing)
此时偏移地址通过间接的方式给出,即地址被记录在一个寄存器中。
1 | MOV DX, [SI] |
根据上面的叙述,这里的寄存器只能是BX,BP,SI,DI。
5.寄存器相对寻址(register relative addressing)
在其他一些材料中也称其为基址/变址寻址,它引入了位移量这一概念。当寄存器为BX,BP时称为基址寻址,寄存器为SI或DI时,称为变址寻址。
1 | MOV CX,36H[BX] |
这种方式可以很方便的寻找一维数组存储在内存中的操作数。
6.基址变址寻址(based indexed addressing)
此时基址寄存器是BX或BP,变址寄存器是SI或DI,最后的有效地址是BX或BP的内容+SI或DI的内容+位移量,例如:
1 | MOV AX, 8AH[BX][SI] |
这种方式在寻找二维表等复杂的结构时比较方便。
7.基址变址且相对寻址(based indexed relative addressing)
这种方式是上面两个的缝合:
1 | MOV DL, [BX+15][DI+8] |
8.隐含寻址(hidden addressing)
在一些教材中这并没有被当作一个特别的寻址方式,所以有的教材是7种寻址方式。隐含寻址指的是操作码中本身隐含了操作数的地址。如书上举的MOVSB。一个类似的例子也出现在计组中,指ADD自动暂存在ALU的累加寄存器中,在这里也就是AX。
MOV
转移地址的寻址方式此处略去,因为内容不多且日后可以和JMP指令合并记录。上面我们介绍的8种寻址方式,实际上是从单纯的“数据寻址”来阐明一些规律,我们更侧重于“有这样的寻址方式”,而不是“如果我选定特定的两个单元,这样写可不可以”。后者需要专门了解MOV传送指令:
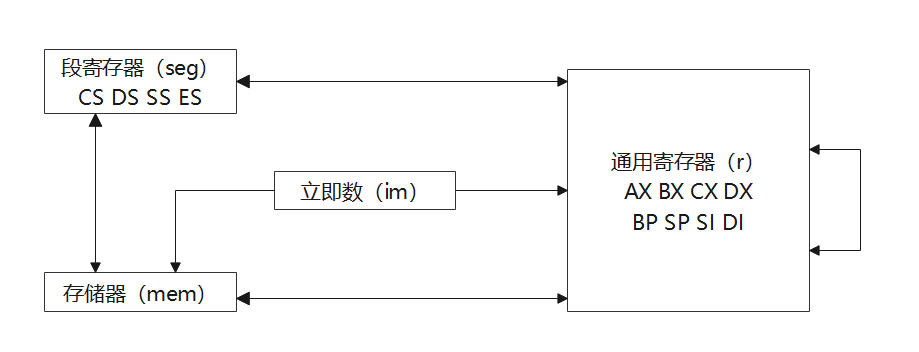
从上面8种寻址我们一定得到一个观念:不管什么时候,确认一个物理地址都需要段地址和偏移地址。把这个记住,我们下面来看MOV指令的几个要点:
①目的操作数不允许用段寄存器CS,当改变CS后,会让一个新的段成为当前代码段,而此时的IP仍然是之前代码段的下一条指令,这会导致一些奇怪的事情。
②目的操作数不允许是立即数,一方面是因为立即数只是一串数,它不是变量不能被赋值。另一方面是立即数一般来自指令内部,不可更改。
③立即数不能直接送至段寄存器,如果需要,需通过其他寄存器转送(注意上图的双箭头回路)。这一点各种论坛上有许多讨论,实际上如果看硬件布线,立即数所在的指令队列和段寄存器组是畅通的,网络上的看法是:英特尔开发者在早期出于操作码字长的考虑,没有加这条不必要的指令。
④不允许两个存储单元之间直接传送数据,这里的存储单元指的是存储器(RAM/ROM),如果需要,需通过寄存器转送。这是好理解的,因为总线同一时间只能进行读和取一种操作(对于外部)。
⑤源操作数和目的操作数不可以同时为段寄存器,电路设计上它们没有互联。而且段寄存器储存的都是不同属性的基地址,这样做没有意义。
⑥源操作数和目的操作数的数据类型必须相同。例如MOV AL,BX是错误的。
End
我先在这里标个End,但这篇不知道啥时候能End。“给岁月以文明,而不是给文明以岁月。”昨天晚上路过海棠社团招新,才有一种“妈呀,我要毕业了。”的感觉。我的大学生话还只剩不到两年,只有在这种土埋半截的时候,我才能放下那些内卷,加分,保研,来满足智慧生命的好奇心。我现在看着一些课本,已经不再考虑诸如“这门课几学分,要考多少分才够。”,而是完全沉浸在logical的精彩里。我还有太多事情没有做,我在图书馆翻到了一本30天自制操作系统,非常的amusing。我想阅读pytorch的源码,了解一下我之前蹉跎岁月无脑炼丹后面到底是什么机制。我想,现在距离我回到家乡穿上外卖服,还有些时间,应该还够用。

