
在大一学年的时候,我有一门按照张禾瑞先生写的高等代数讲授的代数课。可是我当时没有太学明白,当时也没有试着将应用与之相结合,现在把它补回来也为时不晚。
Useful view
说到底,当时的我没能够认识到矩阵理论的重要。不然我在之前暑假翻开数值分析的时候,就不会略去最后那一章。尤其在代数课上学到特征值和特征向量时,我感到非常的不解,但现在回过头发现,其实不难。
一个矩阵对应着一个线性映射,这里的一个题外话:在我当时大一的时候,书上是这么写的:

如果当时以“拉伸,旋转,剪切”来佐为例子,会形象的多。例如:
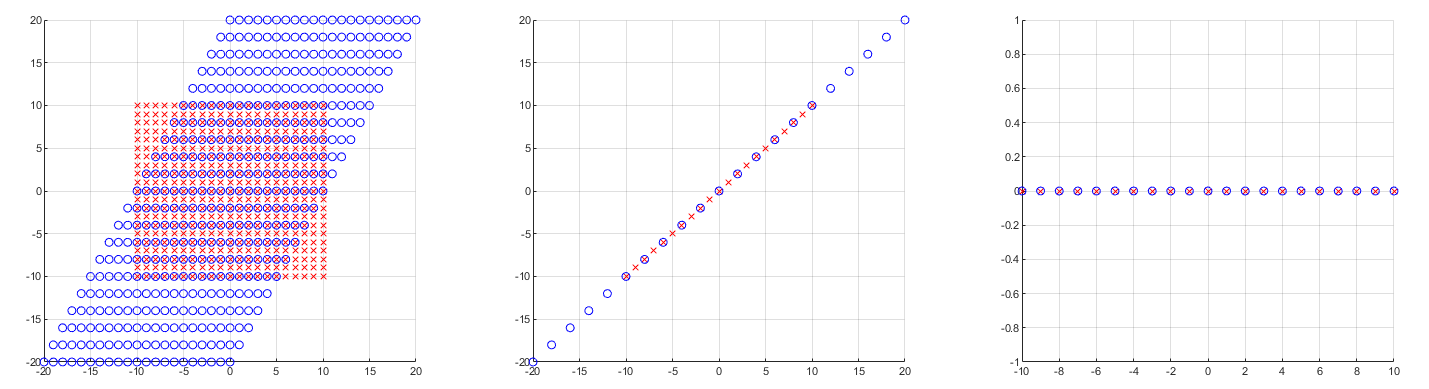
那么特征值实际上就是,如果对某个向量$\mathrm{\vec{v}}$做线性变换,而特别的是,这个线性变换相当于给$\mathrm{\vec{v}}$乘上了常数$\lambda$的标量。想象一个二维向量,如果以某种特别的方式拉伸它,那么它相当于长度变化了$ \lambda$倍;但是如果一个线性变换是旋转,那么就不可能让旋转某个角度后的向量满足上述关系。也就是说此时的实常数$\lambda$不存在(计算会发现它其实是个复数)。如果我们要求解出$\mathrm{\vec{v}},\lambda$,直接计算即可:
比如上图的例子,其矩阵$A=[1,1;0,2]$,特征值分别为1和2,那么相应的特征向量就被拉伸了。特征值和特征向量的求解可根据$Cramer$法则,直接求出使得$\mathrm{det}(A-\lambda I)=0$的$\lambda$。之后解这个齐次方程组,得到特征向量。特征向量非常有用,我们考虑一个有$n$个不同特征值的矩阵$A$:
那么以列向量$x_1,x_2,…,x_n$组成的矩阵记为$P$,我们发现:
矩阵$P$是可逆的,因为不同特征值的特征向量线性无关,所以$P$满秩。这个结论可以通过反证法来证明。于是我们就有:
这个过程即相似对角化,$\varLambda$是以各特征值为元素的对角矩阵。在刚学到高等代数时,乔老师指出它可以用来算矩阵的高次幂。实际上,它也完成了将一个矩阵进行分解的作用,也可以叫其特征值分解。将这个概念扩展,可得到“相似变换”,如果有可逆矩阵$P$使得$P^{-1}AP=B$,那么称$A$与$B$相似。这个形式实际上转换了“基的视角”,此时的矩阵$P$一般是两个基之间的过渡矩阵。但在这里我们仍然先关注于$B$是对角阵的情况。
实际上,特征向量和特征值很特殊,因为其余向量都在矩阵的变换中偏离了自己的位置,但它们没有。这使得它们是对该线性变换的一个很好的描述。这里我并没有补充关于线性映射,基的转换的背景。实际上我们可以给$P$乘上一个单位阵,这样,矩阵$P$的意义就变得明了,使得我们从朴素的那个规范正交基(1,0,0…,0,1,0…)过渡到由特征向量组成的基中。值得一提的是,同一个线性映射在不同基下的矩阵是不同的。
How to calculate?
现在我们关注特征值和特征向量如何求取,按照定义进行求解是复杂的,并且多项式当次数大于4时将没有显式的求根公式。实际上,QR分解可以用于计算特征值,在一定的条件下,也可以得出特征向量。
QR分解求特征值基于QR分解,它实际上是施密特正交化的另一种表示,我们知道,通过施密特正交化,我们可以把一组线性无关的向量转化为标准正交基。它的思路可以形象化的描述为“如果对于平面上的两个不共线的向量,我们总可以选取其中一个,归一化为单位向量,之后将另外一个投影的一个标量倍作为被减数,与第二个向量相减。至于这个标量倍,可以通过令减去后的两向量内积为零来计算”。这一论述可以扩展到$n$维。
设$\alpha_1,\alpha_2,…,\alpha_m$是$\mathbb{R} ^n$的一个线性无关向量组,这里$m\le n$,则正交化可以表述为:
这样$\beta_1,\beta_2,…,\beta_m$是正交的,再进行归一化就得到了一组规范正交基$e_1,e_2,…,e_m$。
那么我们现在考虑一个$m \times n$的矩阵$A=(\alpha_1,\alpha_2,..,\alpha_n)$,其秩为$n$,进行正交化后得到了$\beta_i$,我们将上式的系数用$k_{i,j}$表示,因为系数本身在下面并不重要。我们写作:
进行简单移项:
再进行单位化,使得$e_i=\frac{\beta _i}{\left| \beta _i \right|}$。所以上面的正交化写作即可写作:
所以对于矩阵$A$,就有:
注意到,由$e_i$构成的矩阵,是一个正交矩阵,我们把它记为$Q$,右边的是一个主对角线非负的上三角矩阵,记作$R$。所以实际上就是施密特正交化的另一种表示。这个分解是唯一的,我们在这里就不作解释了。
但是问题还没有得到圆满的解决,这个QR分解到底如何求解特征值呢?这有些复杂,为此我们先要补充两个基础知识:幂法和LU分解。
LU分解是高斯消元的另一种表达,是对矩阵$A$应用初等行变换,将其变为一个下三角矩阵和上三角矩阵的乘积,它要求$A$满秩,否则下三角阵的主对角线就不全为1了。直观来看,即:
依次计算即可得到$L$和$U$。上三角和下三角矩阵有些许性质,上三角矩阵乘以一个上三角矩阵,仍然是上三角阵,下三角一样。同样,上三角阵的逆阵也是上三角阵,这同样适用于下三角。
现在我们来了解一下幂法。幂法是一种求特征值和特征向量的数值方法。我们先观察一个现象:
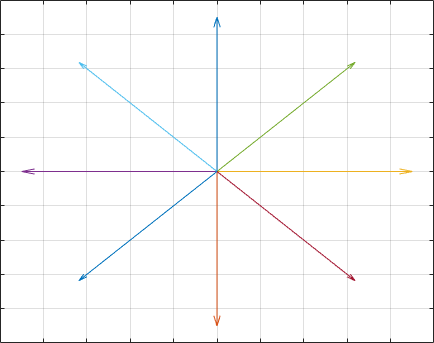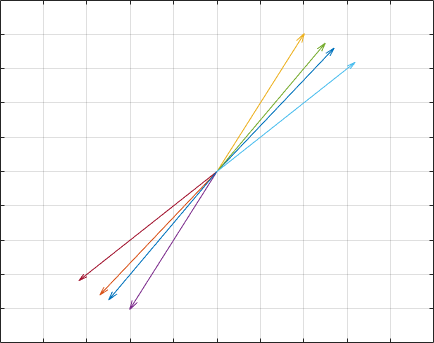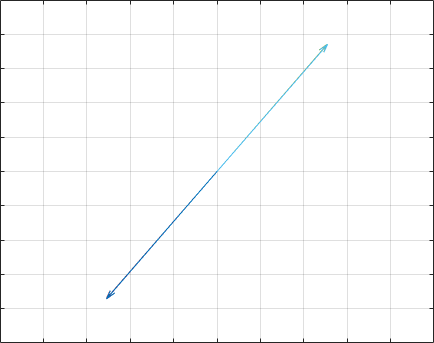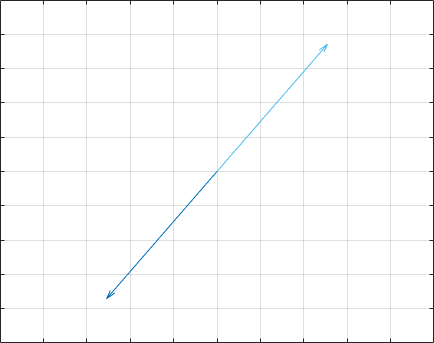
我均匀选取了8个单位向量,每次作用一个矩阵$[1,3;2,4]$,每次作用后对向量进行归一化。反复迭代了数次,发现它们被“富集”到了一个方向上。这并不是偶然。这个方向其实是”主特征值”(绝对值最大的特征值)对应的特征向量的方向。同样我们假设一个矩阵$A$,它有$n$个线性无关的特征向量。则我们每次选取的一个随机的向量可以写作:
当然,它在主特征向量的方向的分量$k_1$不能为0,否则就没有意义了。我们这里设定$\lambda_1$为主特征值,之后我们直接计算:
这就是幂法(Power iteration)
可以发现,它可以求出主特征值和主特征向量。那么当我们想求解矩阵所有的特征值和特征向量时,能否扩展?答案是肯定的。我们只需要让$k_1$等于零即可,这是可以办到的,只要我们求解出$x_1$后进行正交化即可。然后继续进行幂法。这就回到了前面说的QR分解。但值得注意的是,施密特正交化在数值上并不稳定,这引出了修改后的正交化算法和$Householder$算法,但不是这里的重点。
那么我们之前说的利用QR分解求特征值,指的是一个怎样的流程呢?完整的表述是,它先从矩阵$A_0=A$开始,进行QR分解:
从另一个角度看,它构造了一个相似变换
最终的$A_k$将收敛到一个上三角阵,上三角阵的主对角元素即$A$的特征值。
经过前面对幂法的铺垫,我们可以对为什么根据QR分解反复构造相似变换可以给出所有的特征值有一个直观的理解。前面说的是对一个初始向量应用幂法,得到一个特征向量后,应用正交化的方法得到第二个正交于第一个特征向量的向量,继续幂法……而QR分解有一种将两个事情并行运算的感觉。
我们下面用对称正定的矩阵$A$来给出此时QR分解的收敛性证明,重点是体会幂法在其中的作用。选择对称正定阵是因为它特征值恒正并且互不相同。以及由于对称性的保持,最后的$A_k$会收敛到一个对角阵。
首先,$A$是对称正定的,可以被相似对角化,即$A=P\varLambda P^T$,这里要注意实对称矩阵的特征向量是正交的,所以满足$PP^T=I$。同样,$P$满足LU分解的条件,可以写作$P^T=LU$。对于$P$,一个常见的QR分解可以被执行:$P=QR$。我们从$A^k$入手:
同时,由QR分解推导得,$A^k$也可以写作:
我们将$P$与$P^T$分别列写,对矩阵进行构造:
注意$L$是一个主对角线为1的下三角阵,所以矩阵$\varLambda ^kL\varLambda ^{-k}$会有如下情形:
我们又一次见到了幂法,所以中间那项趋向于单位阵,$A_k$就写作$A^k=QRR^{-1}R\varLambda ^kU=QR\varLambda ^kU=P\varLambda ^kU$,同时,$A_k$还等于正交矩阵$Q_i$和上三角阵$R_i$的连乘积。所以$Q_i$的连乘积趋近于$P$,这也使得$Q_k$趋近于单位阵。所以对于之前的相似关系:
最后的简化完全依赖于$A$是实对称阵,同时上面的$\varLambda ^kL\varLambda ^{-k}$也需要特征值保持正定。但这一过程已经足够用来体会QR分解求特征值与幂法的关系。更一般的证明可以参考相关资料,大体的思路是通过一些矩阵变换的技巧来辅助证明,这和我们的主题有些偏离。我们通过对特殊情形下的QR分解进行分析,为特征值的数值求解有一个大体的概念,这就够了。
Application
现在我们对特征值和特征向量的概念和计算有了初步了解,假设我们已经有了趁手的计算特征值和特征向量的方法,现在关注于他们的应用。
但在应用前我们发现,真实情况下方阵是罕见的,以及对于一些简单的统计数据,每一列往往也和我们我们所指的基向量不太一样。我们先解决不是方阵的情况。我们思考一个方阵,它作为一个线性变换,是将$n$维映射到$n$维,这两个空间是同构的。但当非方阵($m \times n$)时,是将$m$维映射到$n$维。此时是不可能存在例如$Ax=\lambda x$这样便利的关系的。一个朴素的想法是,希望$A_{m\times n}x_{n\times 1}=\sigma u_{m\times 1}$另一个空间里有这样的向量$u_i$来有这样的结构,此时$\sigma$即为奇异值,后面会更加深入的分析$\sigma_i$。
那样即是:
下面将$X$改写成$V$矩阵,这样从符号上与现行的一致。即$AV=U\varSigma $。实际上,刚才的$x_i,u_i$他们都应该是正交基。这一点是很自然推出的,因为当我们想计算$V$和$U$时,我们往往想从$A$出发。容易构造$AA^T,A^TA$,它们各自是$m \times m$和$n \times n$对称半正定方阵,它们一定可以走之前特征值和特征向量的流程,同时它们的特征向量是正交的。
我们从$A^TA$出发,它的特征向量组为$v_1,v_2,…,v_n$。我们这里默认$v_i$进行了归一化,后面会发现这样带来了好处。同时,我们注意到$Av_1,Av_2,…,Av_n$也是正交基。(注意,这里其实特征向量组可能不到$n$个,这取决于$A^TA$的秩。但这不影响它们被变换后仍为正交基):
如果我们将$Av_i$进行标准化,我们会发现:
此时对$v_i$标准化的好处就出来了,同时我们也知道之前猜想的$\sigma_i$实际上就是$\sqrt \lambda_i$。这样我们发现,前面$AV=U\varSigma$中应用标准正交基的好处,由于$U$是正交阵,它可以直接写作:
这就是大名鼎鼎的奇异值分解(Singular Value Decomposition),如果用$AA^T$重走刚才的分析流程,是完全一样的。即$U$是$m$阶正交矩阵,是$AA^T$的特征向量,也称为$A$的左奇异向量。$V$是$n$阶正交矩阵,是$A^TA$的特征向量,即右奇异向量。更重要的是,它揭示了线性变换的一个重要性质:
任何一个线性变换,都可以通过先旋转,再拉伸,再旋转来得到。
它的一大应用是进行主成分分析,简单来说,奇异值最大的,就是主成分。这里略去了对主成分分析的一些推导,简单来说这两者最终都归结为了对$X^TX$作特征值分解。主成分分析中最出名的例子就是鸢尾花数据集。
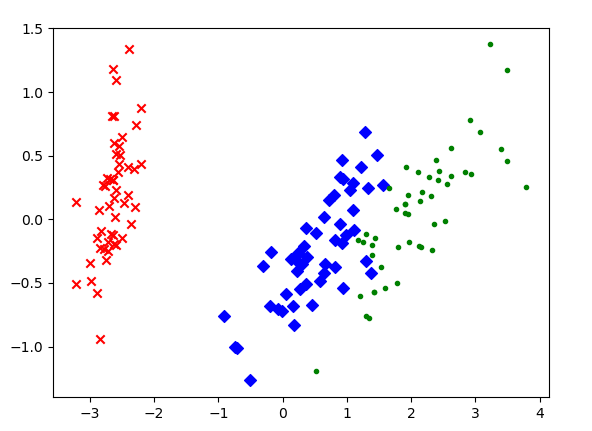
可以看到,$x$轴在分类中很有帮助,实际上$\sigma_1=4.23,\sigma_2=0.246$,这也解释了为什么但用$y$轴很难分类。这个例子很好的说明了对统计量的分析。
另一个用处是压缩,例如图像压缩和去噪,例如对Lena图(256×256)进行压缩:

可以发现,当选取的奇异值从大到小达到100时,lena图就很清晰的展现了出来。
End
在最开始学习高等代数的时候,我遇到了很多困难,我并不习惯于代数的语言,我只是一个来自小镇的依托直觉和可视化解决全国卷一数学的普通学生(而且我解决的并不好)。我现在仍然能回想起当时被$m \times n$支配的恐惧,和那些读了半天都读不懂的话。相较我的同学们,我比较愚笨,上高中,排列组合,化学反应原理,受力分析啥的我接受的往往都很慢;大学里,当他们讨论什么东西的证明,编程,指针,平衡二叉树,我在旁边思路是跟不上的。所以我的考试成绩也不是很靠前,但是这不重要,rank不rank1或者前不前5%人还不是活着。无非是以后衣着是否光鲜或鼎食是否奢华。回想起两年前刚报到,到现在,别人一遍能学明白的,我多学几遍就好了。“故余虽愚,卒获有所闻。”

