
上学期计算机组成有个线上实验平台,尤其最后补全一个单总线CPU非常好玩。当时其实不是很懂,赶紧做完了就交了,但是看那个电路动起来还是很激动,隔了两个月,这几天有点时间,查了查资料整理一下。
当时,没有好好的学数电,学到计组也是急忙为了考试。直到在这个logisim仿真平台上作出这个演示以后,才发觉“这真精巧”。这同时也感谢logisim平台和HUST的线上实验,让我可以在不花费学习成本在Verilog上也可以体验较为完整的一个流程。
现在记录这个,并不能让我的均分上升,只是遵从于一个朴素的好奇心。实验给出的是一个单总线CPU,而不是更一般的数据总线,地址总线,控制总线。这会导致一些繁琐的事情发生。但它结构简单,容易实现。
首先,CPU的一个经典的工作流程是:取指令→分析指令→执行指令→取指令,我一直对那几门课没有热情,就是因为教的时候很多内容高度概括,这导致学到这儿和那儿,联系不起来。比如学Cache,其实不需要想那么多,死学Cache八股即可;然后学到CPU,基本只能考微指令的书写,也是八股。结果两者之间建立不了什么真切的联系,抑或是和数字电路的关系,也太形而上了。而如果应对考试需求,这确实也够了。好了牢骚发完了,我开始写了。
实验的背景设置的是RISC-V指令集,但实际上没有到那么复杂的地步。
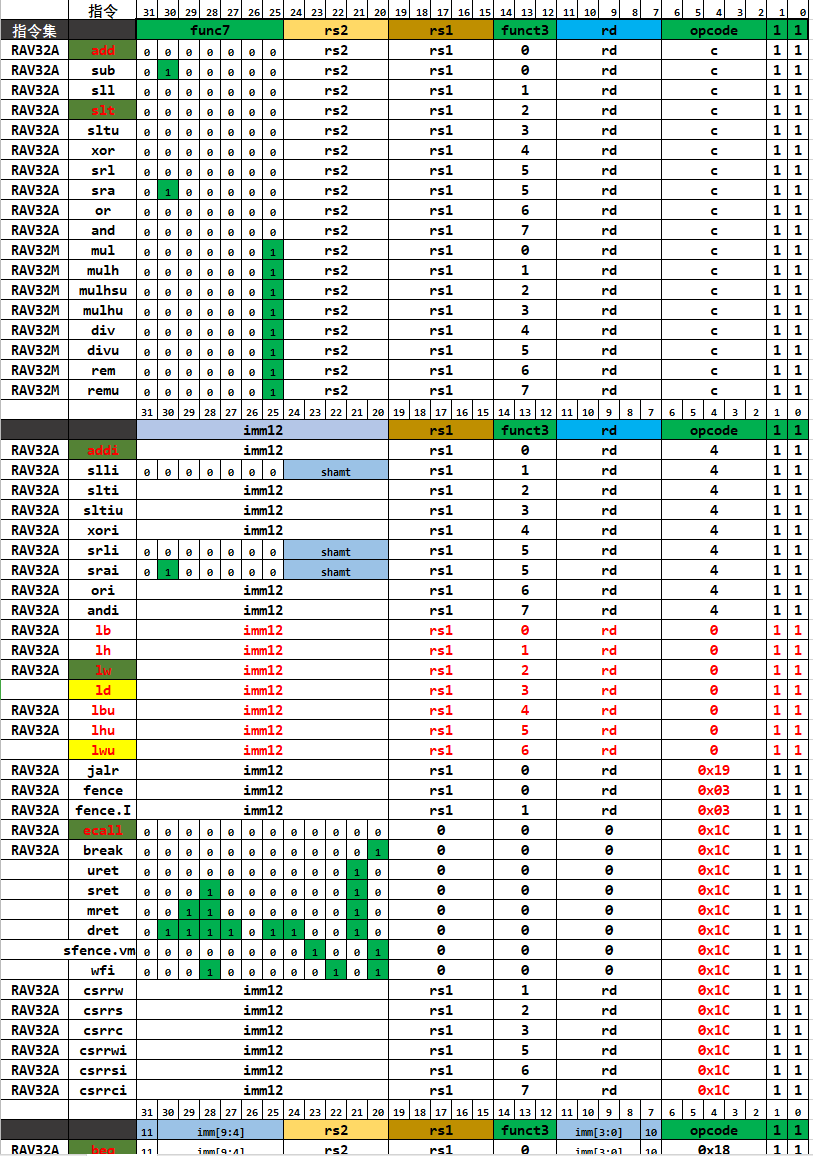
如图是实验材料中附带的指令集,这里有许多指令,其实我们要关注的只有lw,sw,beq,addi,slt五个指令。这五个指令足够演示冒泡排序。查阅资料可知,这里slt是R型(寄存器-寄存器操作)指令,addi,lw是I型(用于短立即数和访存)指令,beq是B型(有条件分支)指令,sw是S型(访存操作)指令。
更具体的说,addi是将立即数与rs1的值相加并写入rd中。slt是有符号的比较,rs1小于rs2置1反之置0。lw是把四个字节写入rd中,sw是存字,beq是相等条件分支。(这些对我想达到的理解的程度来说并不重要,RISC-V或者MIPS的指令格式在需要的时候都可以查询。)
由于这个例子是单总线,所以各自部件都连接在总线上,各个部件间通过总线进行传输,同一个节拍内总线上只能有一个数据。
现在,有了一个完善的指令集和一套汇编语言,来达到想要的目的。我们也能看懂每一条指令要做什么。现在我们来认识CPU是如何“执行”一条指令的。
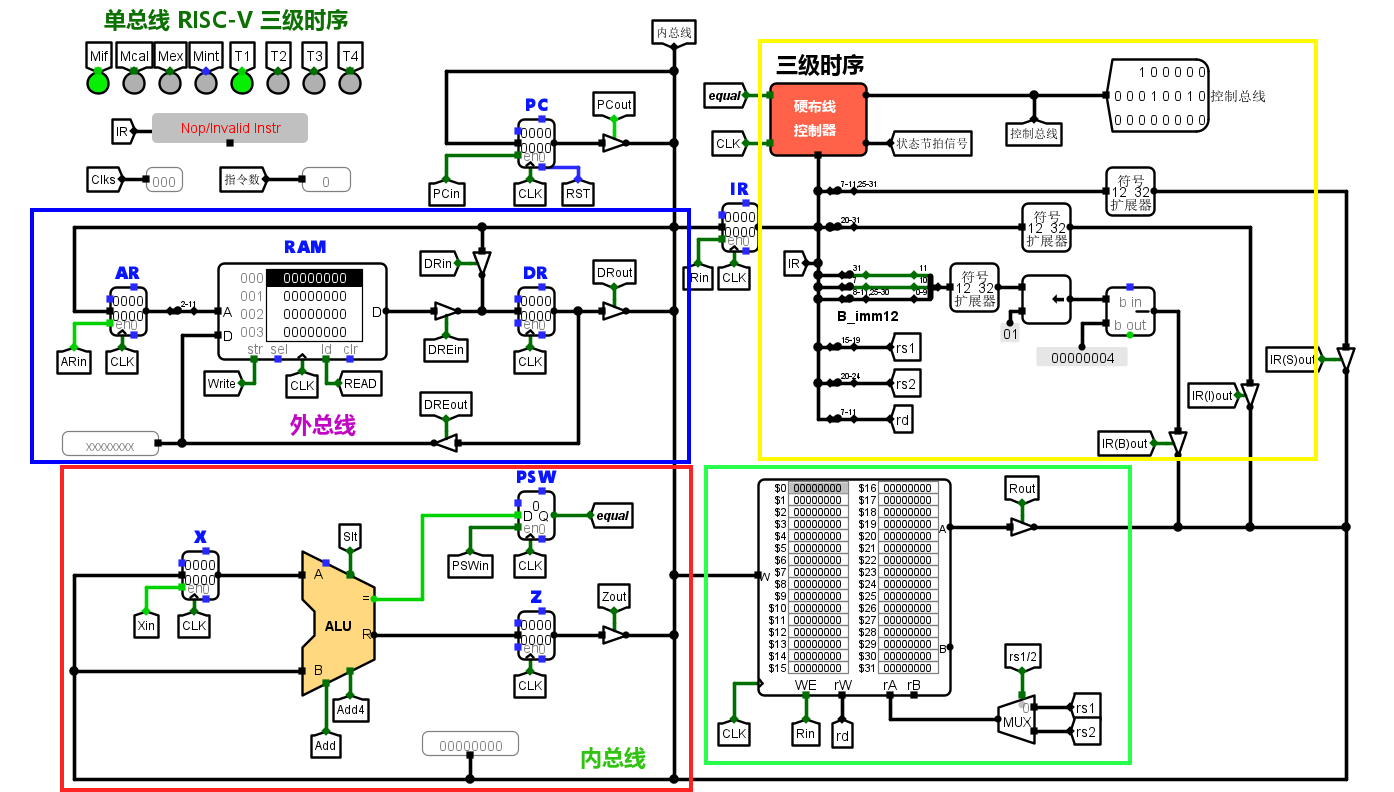
所以这就是了,我必须承认这比课本里流程图式的要更令人激动一点。“spectacular!”
左下角的红色框部分是计算部分的ALU,由于是单总线结构,要设置两个暂存器X,Z来暂时储存数据。状态寄存器PSW用于保存运算标志。右下角绿色框部分是通用寄存器组。左上角的蓝色框部分是PC,AR,DR等与外部RAM连接的区域。这图中的各种变量,带in和out的,都是控制信号。ALU附近的Add4,Add,Slt也是控制信号。这里in往往代表着将总线上的数据锁存到某寄存器内,out往往是将某寄存器的数据输出给总线。这些控制信号会引发数据流动,有规律的控制信号的变化使得一条条指令得以执行。
那么CPU如何知道在什么时候释放什么信号呢?这就是右上角黄色框的控制器的作用。这里的逻辑是当指令寄存器IR接收到指令时,经过分析产生指令译码信号ID,送入控制器就会产生操作控制信号。
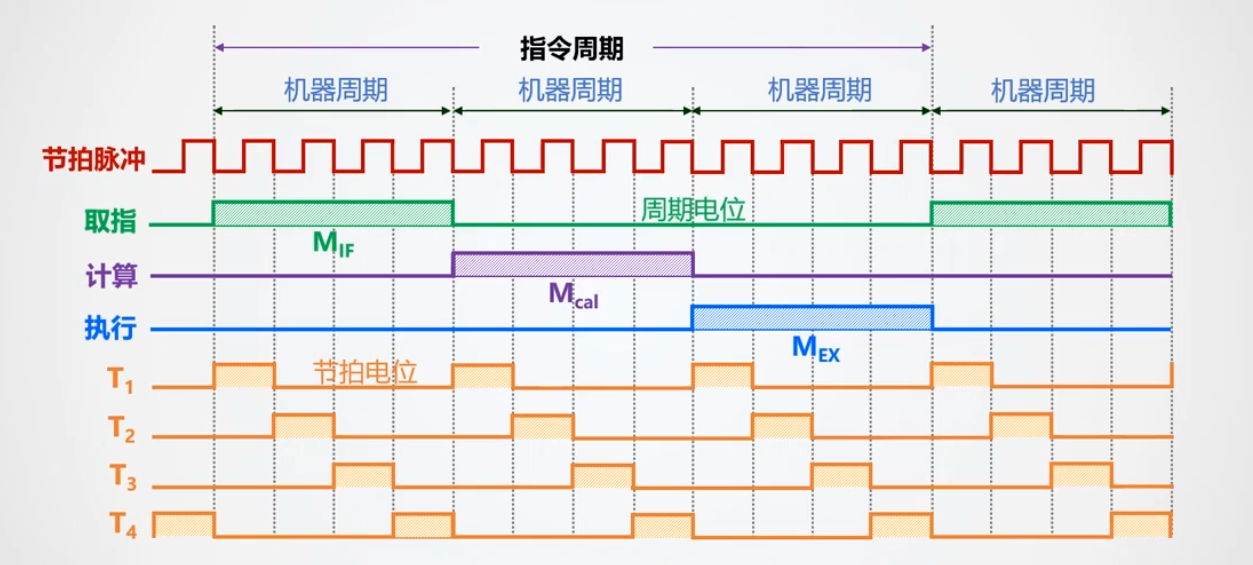
这里的实验采用的是硬布线的控制器,即纯组合逻辑电路。前面我们知道,一条指令的执行,在一个指令周期里,分为若干机器周期,每一机器周期会有若干节拍。在这里实验中模拟的是定长指令周期的三级时序,也就是三个子周期(取指令,计算/分析,执行),每个子周期有4个节拍。一旦确定了某一时刻节拍和子周期的情况,即可输出此时的控制信号。
基于此,需要一个简单的时序发生器,但是和数电课本上不同的是,由于这里已经打包好了由D触发器组成的寄存器(Register),所以它可能外观上不太像从课本里学的经典摩尔型电路……状态转移图和真值表为:
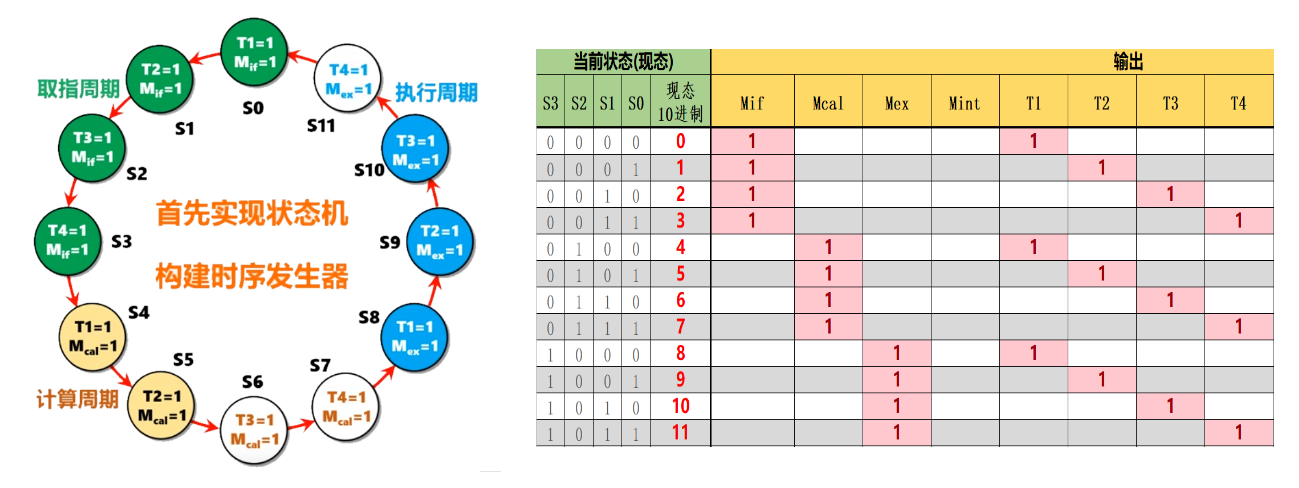
通过真值表可以使用logisim生成组合逻辑电路,最终:
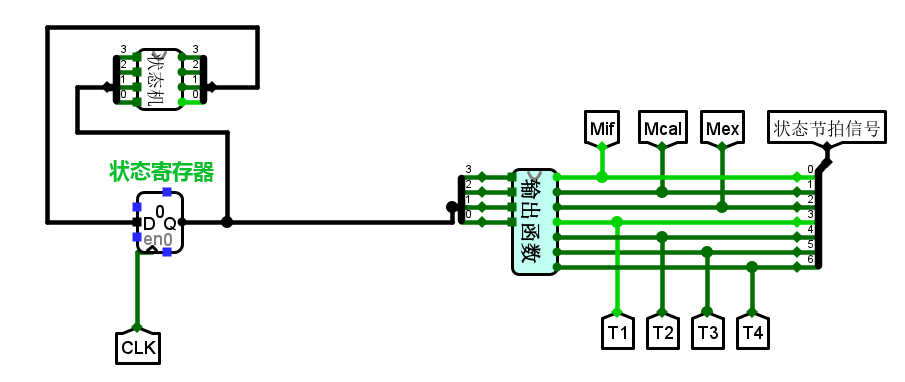
这里的状态机完成的是将四位二进制(0~11)每一次都+1,状态寄存器会记录下一时刻的状态,CLK连接使能端。最右边的输出函数即按上图真值表连接的组合逻辑电路。这样当$t$时刻时,状态寄存器的值会传给输出函数产生状态节拍{Mif,Mcal,Mex,T1,T2,T3,T4},同时传给状态机将此时的状态$S$加1,然后储存给寄存器。如此往复……
同理,有了节拍信号后,与指令译码器分析得到的指令结合,可以得到在各自子周期的节拍中的控制信号。逻辑是一样的,只不过有些复杂:
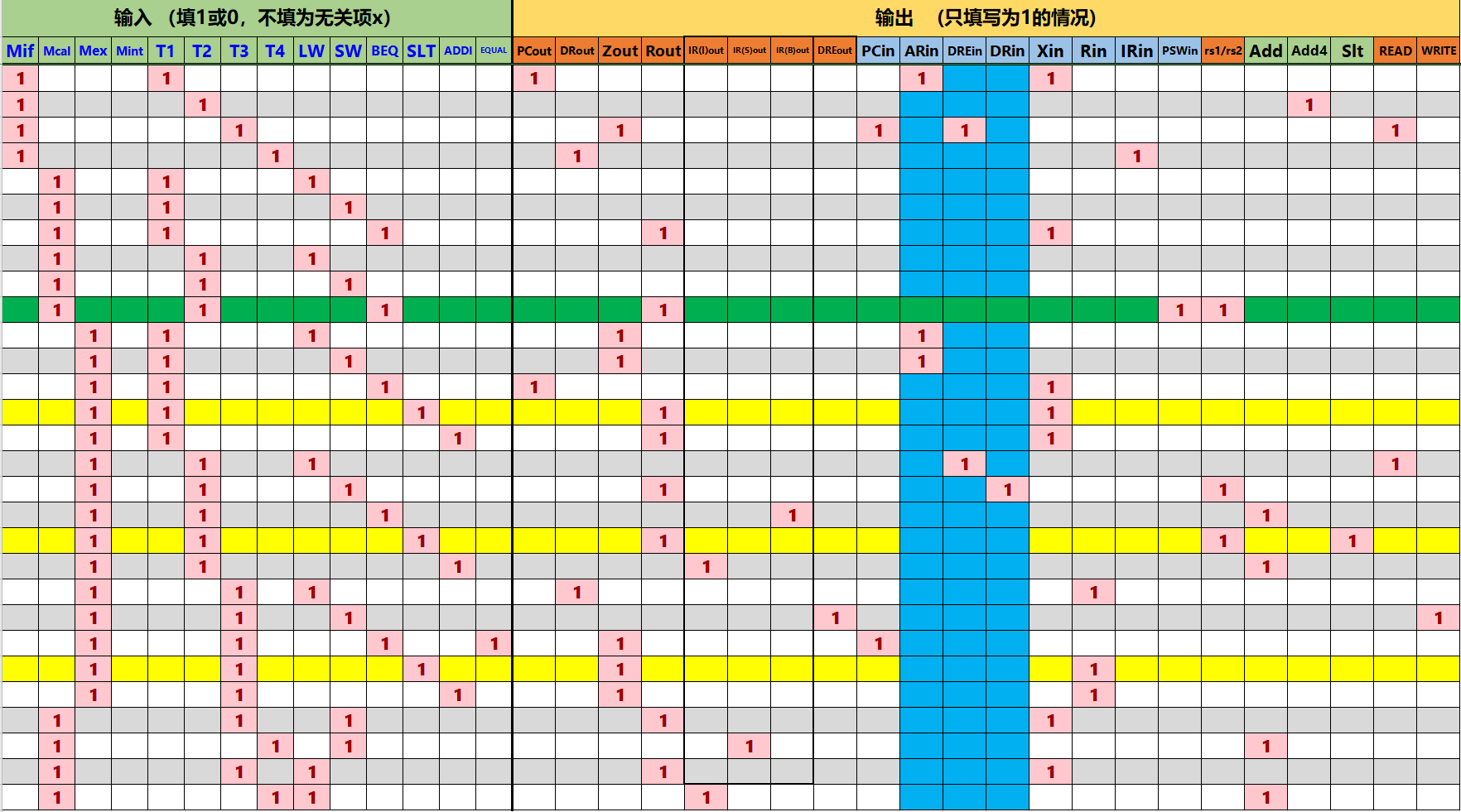
这张表的填写实际上就是分析微指令的操作来的得到的,例如我们对前四行取指令(Mif)阶段作分析,取指令要完成的,是将指令传给IR。首先,以PC为地址访问主存,先将PC传入地址寄存器,同时由于PC后面要++,传入X。此时,相应的控制信号PCout,ARin,Xin就需要点亮。到了T2节拍,X+4→Z,此时只需点亮Add4,完成PC++,加以后的值先储存在Z寄存器里。到了T3节拍,可以将Z→PC,Memory[AR]→DR,将程序计数器自加后的值返给程序计数器,并且从RAM中索引到AR地址记录的数据记给DR。后者不需要占用总线,所以两者可以一起进行。只需点亮Zout,PCin(这使得PC++),DREin,Read(这完成了Memory[AR]→DR)。注意对于数据寄存器,DRE是指跟RAM的连接,DR是跟总线。最后T4节拍,DR→IR,只需DRout,IRin。
我们可以看出,刚才的取指令Memory[PC]→IR,PC++正好使用了4个节拍。那么如果有些指令只需2个或3个节拍完成,就会导致浪费,所以就有了变长指令周期的CPU。这是后话了……
就像取指令这一步一样,我们要考虑的lw,sw,beq等指令也会有各自的控制流。我们就不一个个分析了。总之最后的组合逻辑单元与之前的时序发生器,构成了控制器。

上图是最终的硬布线组合逻辑单元。我们可以发现,这种硬布线的方法,即使只有这么有限的几个指令,线路也很复杂。所以就有了另一种微程序的设计。
现在,我们就基本解构了最开始那张CPU的图。一些更细致的观察:例如右上角硬布线控制器周围的许多分线器,其实仔细观察不难发现他们对照的是RISC-V指令集的各种设置(func7,rs2,rs1,funct3.opcode…),之后通过硬布线控制器发出的控制信号,那些控制三态门的in,out有规律的亮起,来打通数据通路,执行各自的任务。这非常的精巧。
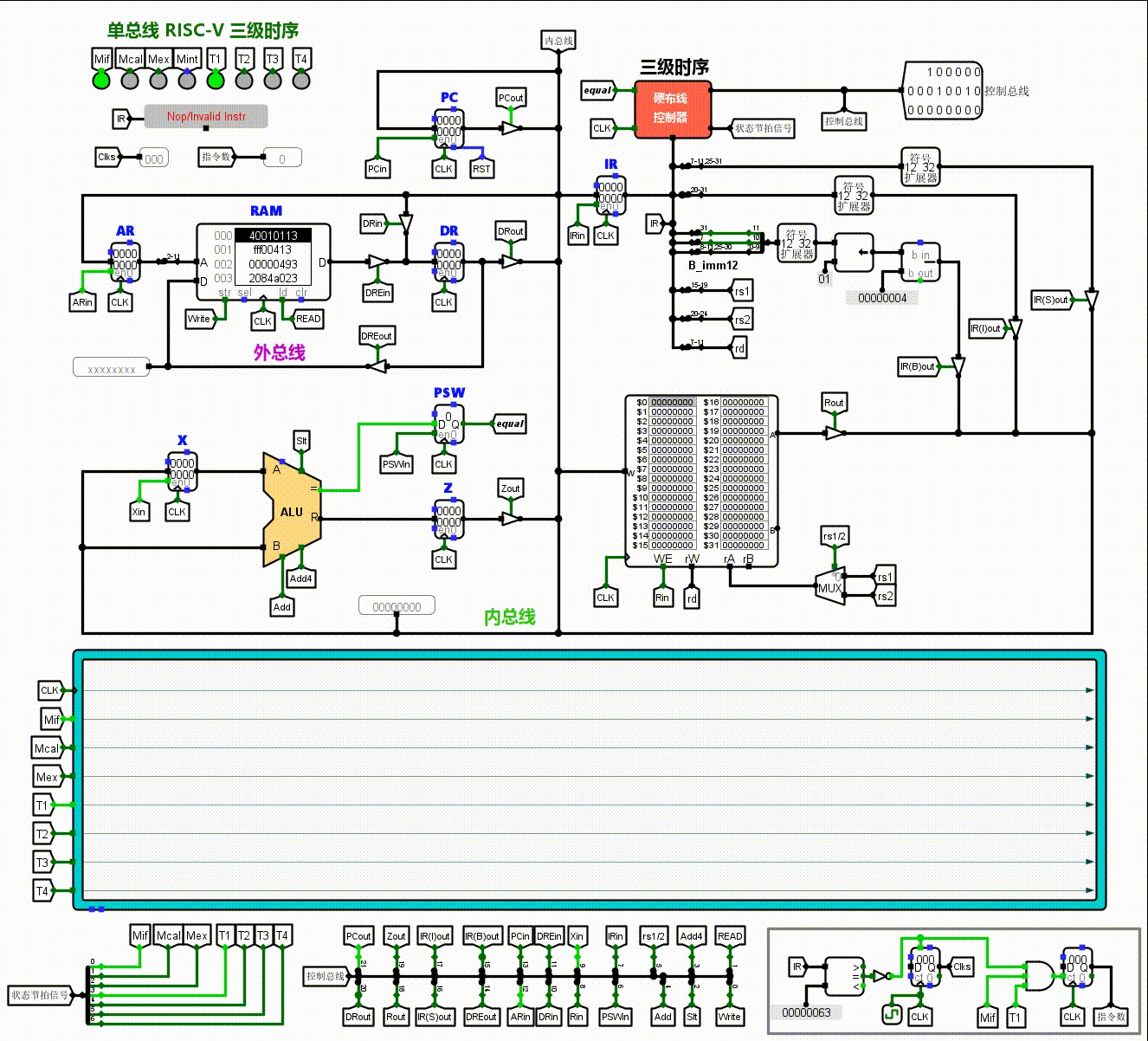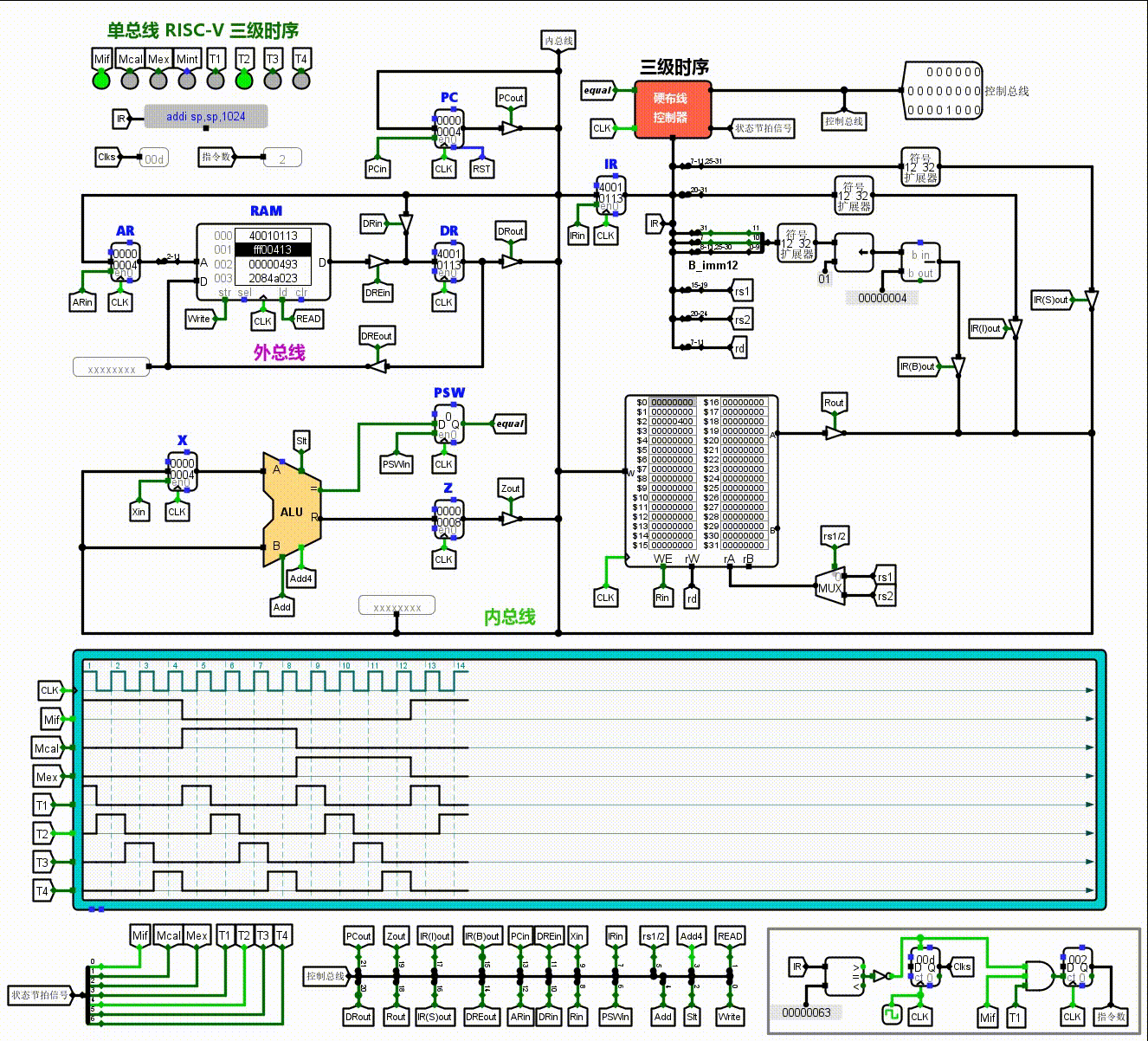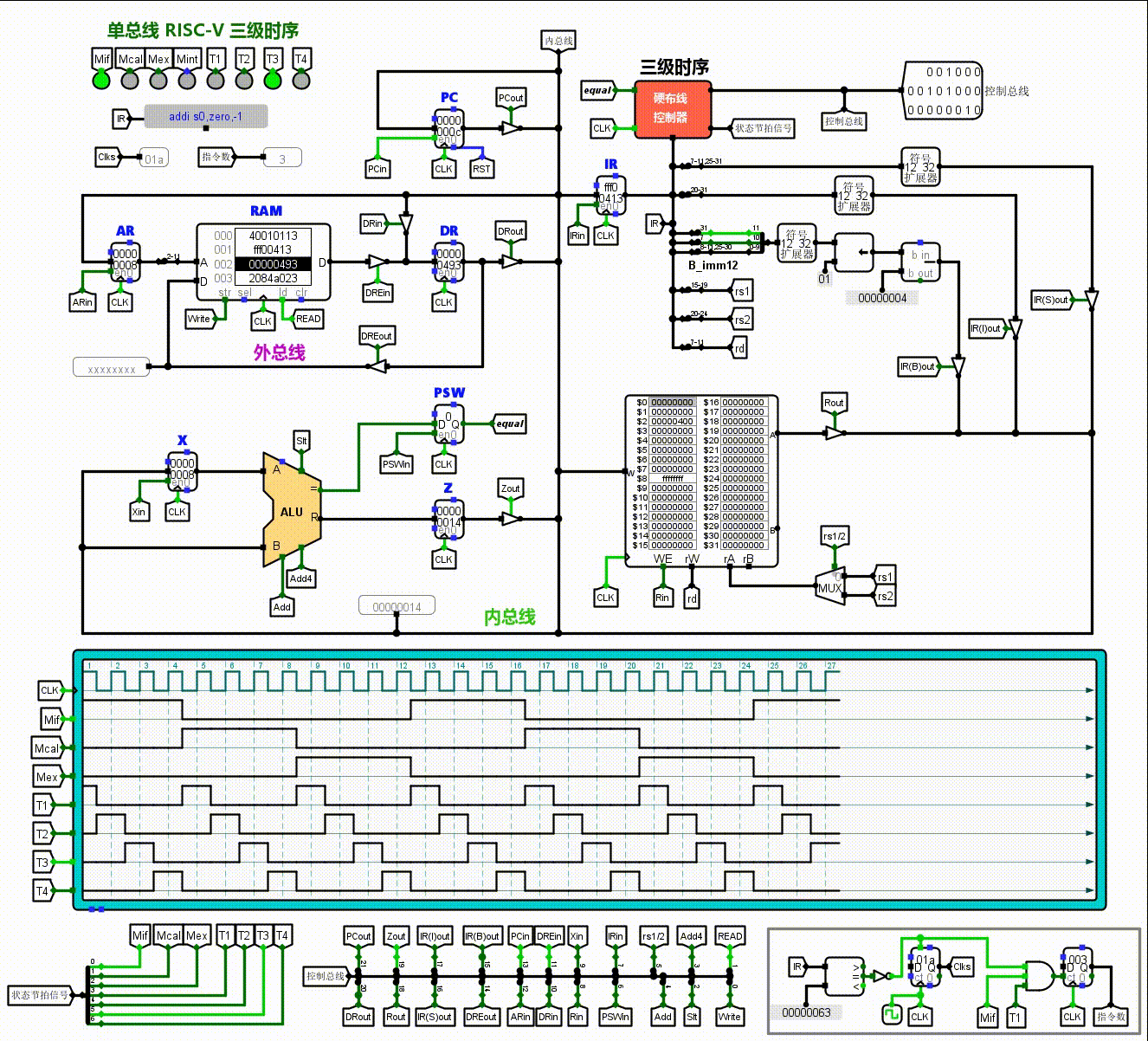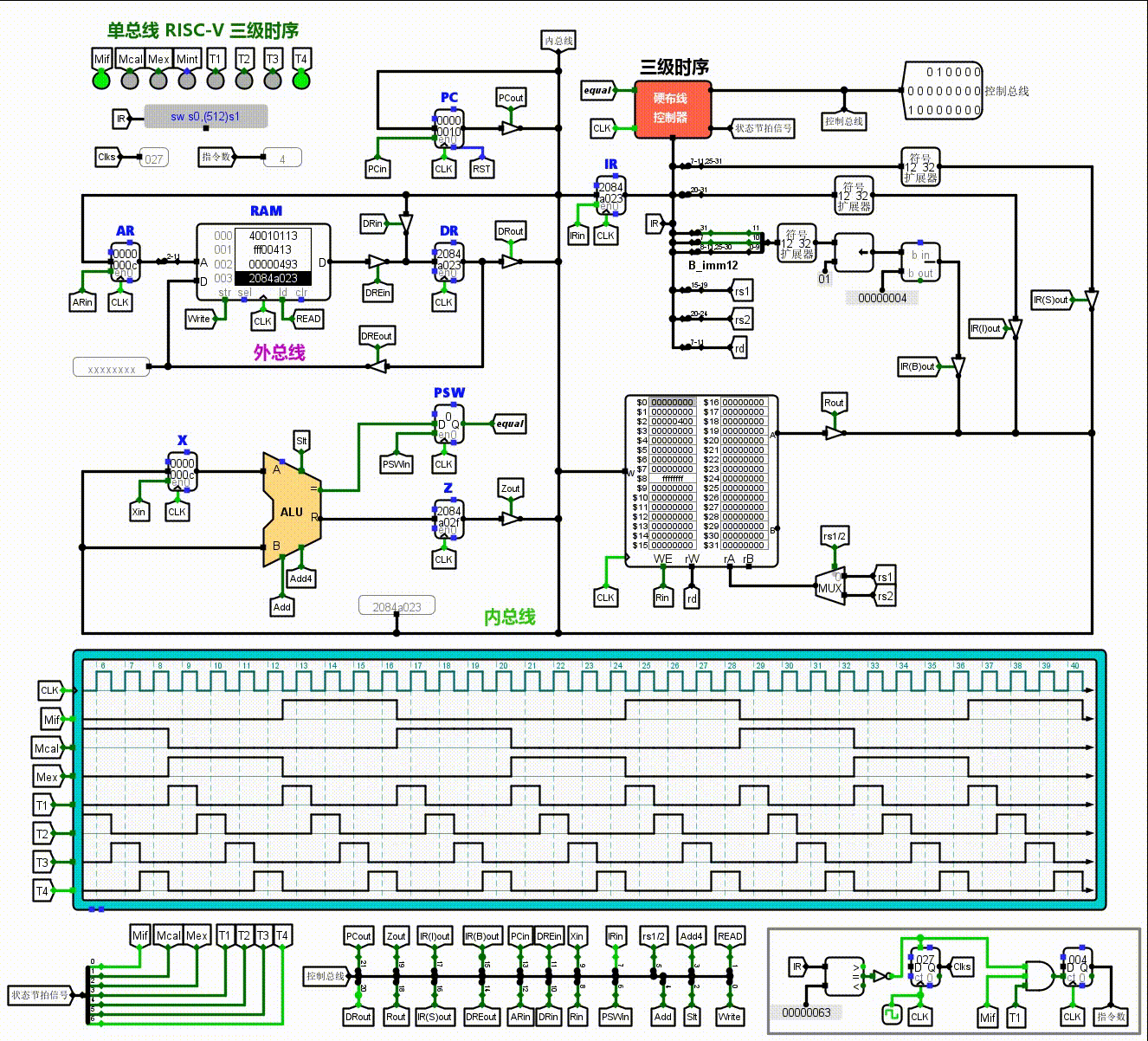
这就是它动起来的样子了。我们可以看到它们按部就班的工作,控制信号有规律的亮起和暗下。
我在很短的篇幅里尽可能刻画了整个的工作流程,但好像少讨论了一个内容。最开始RAM的一串串数据,是一个冒泡排序。实验材料附带了.asm格式的汇编代码:
1 | addi s0,zero,-1 |
解构它们需要学完这学期的微机原理。但这不妨碍理解简单的CPU的这一故事的结束。
人的好奇心,是一个很重要的属性。即使理解到这一程度,并不能让我靠着什么体系结构吃上饭。但没准在某一天送外卖的间隙,可以用来吹水。
