
军训结束了,迎来了上大学以后的第二个暑假。这个暑假意义十分重大,就夹杂着写日记的成份记录一下吧。五月份左右,当时玩了一下渐进生成的GAN,觉得很有意思,比单纯无脑的model.py直球forward更精巧,就记录一下。
在过去比较划水的军训里,我没有从那些形式主义的各种安排和一些不必要的折磨中学到什么,我当时只希望这赶紧结束。但我们排的教官-韩排长,阳光积极的性格令我印象深刻。上大学后我时不时为各种方面不如别人啊,自己干啥啥不行啊非常烦恼焦虑,变得有点愤世嫉俗。所以,当我知道我们因为口嗨,让排长被连长一顿没理由的喷,以及可能由于排长年级低而被另外俩带训教官排挤,而经历了这些排长依然非常的阳光乐观,没有把火撒在我们身上,也没有怨天尤人。他在闲聊的时候,跟我们说他们训练的辛苦,他:“我不想给你们心理那么大压迫,最后我们班那个孩子直接说:我不想练了,班长你把我打死吧。那样把人心理都搞崩了,不太好。”那一刻韩排长的形象直接就高大了起来,他真的,我哭死。总之,祝他前途似锦,早日娶上将军的女儿。
重点就是这个乐观,道理谁都懂,比如中学考试考差了,道理都是“吸取教训”“走出来”。但是放自己身上就未必能行了。上次我被这么震惊的时候,是大一下学期,看见一个同学努力的在操场上跑步,宛如摩西分海。这种来自身边例子的身体力行,才能带来真正的质变。
然后,我就整理一下之前偷偷用老师的机器生成anime girl的这个小demo吧,最简单的那种GAN生成的质量不太行,所以一种优雅的progressive growing GAN(PGGAN)就被我采用了,由于最后显卡的资源限制,只能生成到128×128的了,而且当时的训练时间也长到无法承受了,但是至少能看了。(这也没办法啊,别人开源的上来就4联Tesla V100我这儿就两块快报废的2080ti,动不动就显存溢出,我后面尝试了一个trick,然后失败了,这个后面说。)

(虽然这个生成的sample还是很有瑕疵,但是由于数据集没有清洗/以及是完全无监督/训练时间不够,但这已经可以了。)
实际上,那个trick失败的原因,也正是我想记录那次demo的原因,因为当时我还没整明白,就得忙别的了。
首先是网络参数的初始化,这在平时是无关紧要的,按照框架默认的来一般问题都不大,在PGGAN里有一个更精细的设计,首先先回顾一下常见的初始化方式:
Weights initializations
全零或等值初始化:
这显然是不行的,这样会导致参数反传更新时,变化都是相同的,是不可以的。
正态初始化:
早期的AlexNet就是应用的这种方式,但实践发现这种方式不适用于训练很深的网络。同样也有用均匀分布来生成初始值的,均匀分布和正态分布在使用时差别不大。但是这种做法的初始化,是给整个网络结构的所有权重设定一个初始分布,后面我们会看到这样确实难以训练。
Xavier初始化:
后来通过人们的实验以及一些直觉,人们指出,至少对于像tanh这样的激活函数,每一层输入和输出尽可能服从相同的分布,那么直接的一点就是方差尽可能相等,这里的方差既是各层激活值(输出)的方差也是回传时状态梯度的方差(换句话说对于tanh最好不要饱和也不要为0。)
Kaiming初始化:
Xavier初始化并不适用于sigmoid和relu这样不关于0对称的激活函数,所以Kaiming初始化相当于它的改进。这两种初始化的具体推导以后再写吧。
下面我们关注PGGAN中的均衡学习率设置,下面以实现中的EqualizedConv2d()为例:
1 | class EqualizedConv2d(nn.Module): |
它的意思是,最开始所有参数都用正态分布(0,1)生成,在每一次forward的时,都用一个常数(这个常数在Kaiming初始化中也提到了)来进行缩放,(注意是每一次)个人认为这个操作在后面进行Fading in New Layers操作时十分重要,如果不这样对权重进行约束,后续的训练很可能会因为新layer的加入而崩掉。总之这种方法也像梯度截断一样,是对梯度的一个约束,GAN毕竟靠的是balance,不像简单对着ground truth一顿overfit的任务,即使突然梯度飞了,只要不是太离谱,就还有救。
Progressive Growing
另外两个在论文里提及的trick是GAN多年以来的研究经验的直接结果,这里我就略过了,直接进入我觉得最神奇的Fading in阶段:
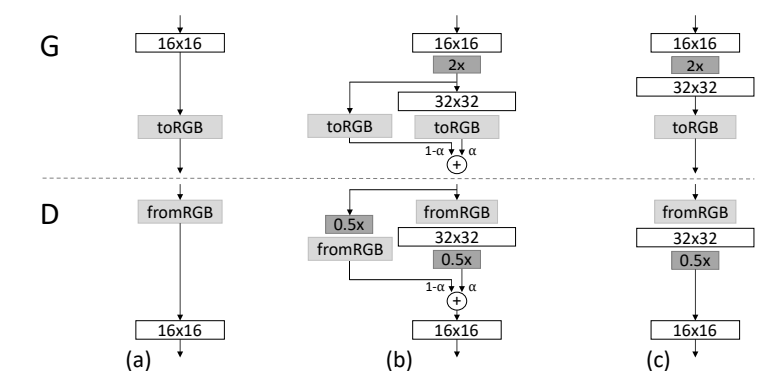
它的核心是,当训练好一层以后,平滑的将层加进来。这一过程在pytorch中实现并不容易,在一些简单的应用里,一般只需要在像model.py里把定义的网络类里修修改改就好了,但是对于PGGAN的实现,这样静态的结构就有些捉急。
1 | class Generator(nn.Module): |
面向对象编程起到了很大的帮助,定义的生成器类和鉴别器类,实例化后的一个对象,是我们得以进行网络结构在训练中逐渐拼接的基础。所以我们定义了generator和discriminator类,这样把很多我们要关注的细节,都写成这个类的属性,会起到很大帮助。
之后的训练中,我们清楚训练的逻辑是:先训练前$k$层,当前stage的迭代次数iter完成后,将第$k+1$层连进来,之后用$\alpha,1-\alpha$来控制前$k$层输出的结果和前$k+1$层输出的结果,其中$\alpha$随iter线性变化,也就是一个stage里总共迭代了2×iter次。为了完成这样的操作,最理想的方法是把整个训练过程封装成一个trainer类,下面我记录一下一些更多的细节:
1 | class Trainer: |
这里我们重点关注train,update_trainer,update_network三个函数,其中gradient_penalty是梯度惩罚项,它也是一个GAN的研究结果,这里就不管了,首先最开始是先从config里拿出一些初始设置的超参数和设置,即:
1 | class Trainer: |
这种通过config来修改超参数,路径等的方式,非常方便建立pipeline,也不会在代码里留下时间一长就令人费解的各种常数,daisiki。这里使用的loss函数是合页函数,至少在我实验的时候,成功了。我对GAN的各种loss的具体细节也不清楚,这里就不报菜名了。至少合页loss,看着就给人一种踏实好训练的感觉,我一直很害怕带着log的东西出现在损失函数里,它们往往会带来nan或者inf的灾难,即log不能输入负数或0,出现这种问题还不好改。
具体的细节可以有些许不一样,在上面所示的实现中,init_size是最开始的图片大小,默认是4,即最开始生成器会生成4×4的图片,鉴别器鉴别的也是4×4的图片,这种操作明显让鉴别器和生成器的任务难度在最开始得到了均衡,而且有助于学到不同层次的feature。鉴别器接受的4×4真实数据是通过原始数据resize来的,后面会有体现。然后size是最后要生成的目标尺寸,设定都是2的若干次方,有了这两个值就可以计算总共要进行的stage阶段数:
+1是因为让初值init_stage=1了(哇这种类似小学数学种树问题的影子好烦),init_ticker以及ticker是后面来进用于fading in的标志量。然后同时实例化了生成器鉴别器,这里的G_EMA是用于推理时的生成器,在训练到一定阶段我们想生成样本看看的时候要用到,因为不想让它再多占用显存,同时它也不用训练,就直接在CPU里推理了。然后我们关注train子函数:
1 | def train(self): |
fixed_z是一个固定的随机生成的向量,高端的说法是从latent space里的采样。它可以用来可视化训练过程,例如:
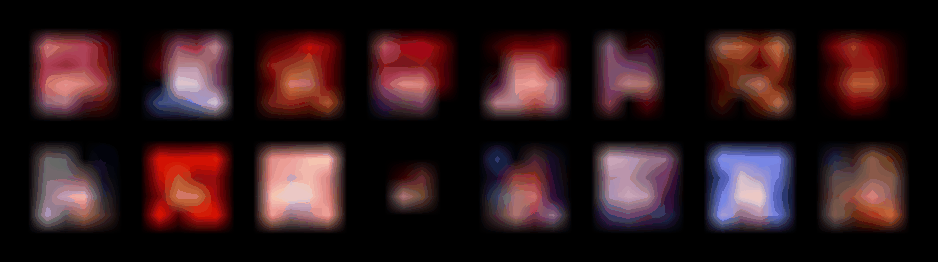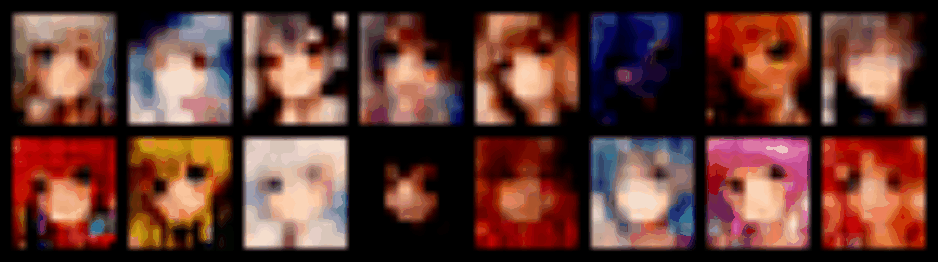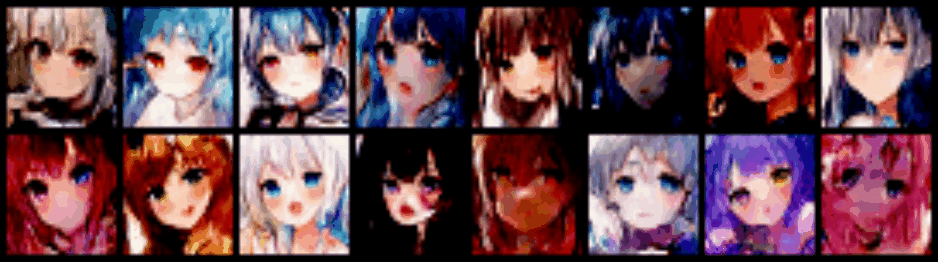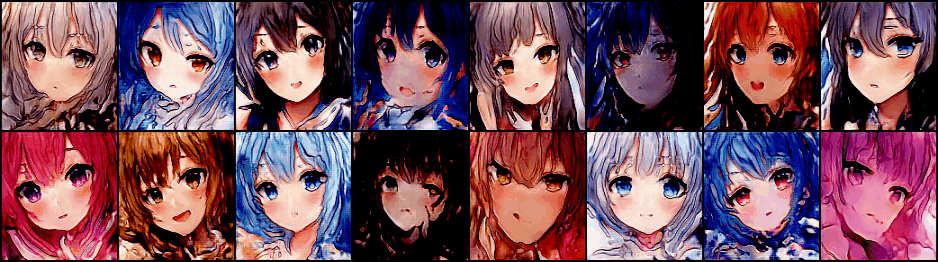
注意最内层遍历数据集的循环,每次都会用update_trainer函数来返回当前的$\alpha$,函数的输入是当前的stage和ticker,在上一层关于stage的循环里,除了当stage==init_stage时,剩下的情况ticker都为0。注意其中对real_data的处理,就是对真实图像进行缩放处理,这里直接调用了torch.nn.functional里现成的池化函数来实现了。
1 | def update_trainer(self, stage, inter_ticker): |
结合上面的更新逻辑,可以看出,当输入的ticker(形参inter_ticker)为0时,实现grow_network,当inter_ticker小于给定的self.tickers时,是fading in阶段,其中:
1 | ... |
当stage不等于1的时候,eps是两倍的unit_epoch,这样ticker最终会比self.tickers大,所以先会进行一个unit_epoch的fading in,然后再进行一个阶段的整体的训练,所以在inter_ticker == self.tickers时,flush掉了network里跳连的部分,生成器和鉴别器实现这几个步骤大同小异,这里以生成器为例,首先要知道,网络结构在pytorch里的存储其实是有序字典,用nn.Module中的add_module方法即可实现增加网络结构。
1 | def grow_network(self): |
上面的函数中用到的deepcopy_layers和deepcopy_exclude函数如下:
1 | def deepcopy_layers(module, layer_name): |
nn.Sequential()是pytorch中的顺序容器,可以将特定的网络模块插入到计算图中,可以用三种方式来使用:
1 | # 方式一 |
这里我们使用的就是第二种方式。以及Sequential类实现了整数索引,可以通过mode[index]这样的方式获取一个层,但是Module类没有,所以在上面的deepcopy函数中,我们利用了Module类中的named-children方法来进行索引,它返回一个迭代器,故可以通过for循环访问,这也是我们deepcopy实现的原理。
回过头再看grow和flush的实现,grow时,我们先把除了to_rgb以外的网络copy给new_model,之后由于grow以后的网络生成的尺寸会提高,则在fade in环节,跳连的结果需要进行上采样,所以old_block是原来的to_rgb层再加上一个上采样层。之后用generator类里定义的intermediate_block方法,我们构造出下一个尺寸需要的反卷积层和to_rgb层,把它接进新定义的new_block里,最后把old_block和new_block拼在一起,之后再加一个Fadein层来,这里的to_rgb层只是1×1的卷积,将现在的通道数缩成RGB三通道,所以每个阶段的to_rgb层不相同。最后的拼接和Fadein层其实并不是熟悉意义上的“层”,只是实例化了一个从nn.Module里继承的类来方便运算:
1 | class ConcatTable(nn.Module): |
可以发现,通过重写forward方法,我们就完成了fade in的操作,然后在grow_network函数的最后,析构掉之前的model,把新的model赋给self.model,就完成了整个grow的阶段。
然后flush操作,道理是一样的,我们只需要把Concat和fadein这两个类移除即可,同时舍弃old_block。这就极大体现了OOP的方便。
可能有人注意到一个小细节,就是update_trainer里,为什么在fade in阶段是self.X.module.grow/flush,以及在渐进的环节还出现了.fadein.update_alpha(delta)这种鬼畜的写法。原理是,上文为了并行计算,把self.X(即鉴别器和生成器)都用nn.DataParallel进一步封装,封装后的.module是其中一个成员,即我们认识上的模型,之后调用generator/discriminator类的类方法,完成grow和flush,其中$\alpha$在fade in环节中是线性变化的,所以我们要修改Fadein类中的self.alpha。这里,self.X.module是generator/discriminator类的对象,model是其中的成员,前面的分析可以知道generator/discriminator类中的self.model是一个nn.Sequential(),而我们知道调用它,只能用整数索引来调用,而Module类的索引是返回一个迭代器。而……这个.fadein的粗暴调用,是因为Sequential继承自Module,而Module里的魔法方法—getattr—是这么写的:
1 | def __getattr__(self, name: str) -> Union[Tensor, 'Module']: |
—getattr—会在访问不存在的属性时候抛出异常……而这里,补了一个将要访问的名字在modules字典中查询的操作,如果查询到了就return到它,所以self.X.module.model.fadein,pycharm编译器不会检索到fadein这个声明,因为它本就不存在于类的属性之中,会直接运行—getattr—,然后在字典里找到了fadein(Fadein()的一个实例对象是fadein),所以我们还是成功访问到了已经被连接进网络Module里的fadein对象,最后通过它的update_alpha方法,通过输入的delta,完成了对其属性self.alpha的修改。
这里要指出,由于最后网络结构更新,flag_opt会重建一次优化器,实际上这个处理不完善,adam优化器里也有一些学习到的参数,但是实验上这样直接重建,除了更新结构后最开始几个epoch会抖动一下,别的还好,所以就不去迁移优化器内部参数了。
Training GAN
之后的update_network就是我们熟悉的训练GAN的标准流程了:
1 | def update_network(self, real_data): |
上述方式的策略是先训练判别器,再训练生成器。实际上X.zero_grad()和opt_X.zero_grad()在这里面用一个就行了……model.zero_grad()是把model所有参数的梯度全清空,optimizer.zero_grad()是把传入优化器的参数梯度清空,如果模型训练过程只有一个优化器,那就没啥区别……清空梯度是有必要的,backward是对梯度进行积累,而不是替换。以及在不适用detach的策略中,对D的backward会导致G的参数上也有一些不该用于更新的梯度。
注意利用fake_data得到pred_fake时的detach操作,其实不detach不会影响参数,但可以冻结训练鉴别器时生成器反向回传的计算,可以加快训练速度。这只是训练GAN的一种策略,实际上也可以通过backward里的retain_graph=True,保留计算图,来进行训练,这里就略了。
而这种训练时,如果从头到尾都用一个比较大的batchsize,让stage1,stage2时几乎只用一两个G的显存,而等到训练到stage6这种情况是,我两块2080ti根本不够用,显存直接溢出。而如果batchsize最开始非常小,那训练时间,直接三四天起步,所以我当时本着,梯度下降的原理:
其中$\eta$是学习率,$n$是batchsize,所以我试图在不同的stage里,用不同的batchsize,同理等比例改变learning rate。然后,训练崩了,成功败北。我后来也没怎么再次实验,埋个坑吧。
这一篇捋完了让我对pytorch有了更深的理解,暑期留在学校效率倒是不低。这一学期,均分寄了,真的不想当做题家了,就当跟恶魔做交易了。继续努力,争取暑假有publication,后面去到自己想去的地方。

